
gpt-image-2玩了下,比之前玩过的那些图像大模型强多了,真的到可以以假乱真底部,感觉这样子进步下去,真真假假难以区分。 测试用例1: 提示词 [crayon-69e8f2ddb2973154681931/] 生成图像 测试用例2 提示词 [crayon-69e8f2ddb297f739137276/] 生成图像 在实际测试过程中,对比以前图像生成模型,一个比较明显的感受是,gpt-image-2 并不只是“更会画图”,而是对“结构化视觉信息”的理解能力更强。例如在快递面单、体检报告这类高密度排版场景中,它不仅能还原元素,还能较好地处理层级关系、信息分区以及视觉噪声(如折痕、模糊、打印质感)。这说明模型在训练中不仅学习了图像风格,还一定程度上学习了“版式语义”,这对于生成拟真文档类图像非常关键。 另外,从提示词设计角度来看,gpt-image-2 对“约束条件”的响应明显优于传统文生图模型。像“标注 Demo Label”“局部模糊”“可扫描风格条码”这类细粒度要求,如果表达清晰且结构合理,模型大概率可以正确执行。这意味着在使用时,与其堆砌形容词,不如将提示词拆成“内容 + 结构 + 视觉约束”三层,会更容易得到稳定且可控的结果。
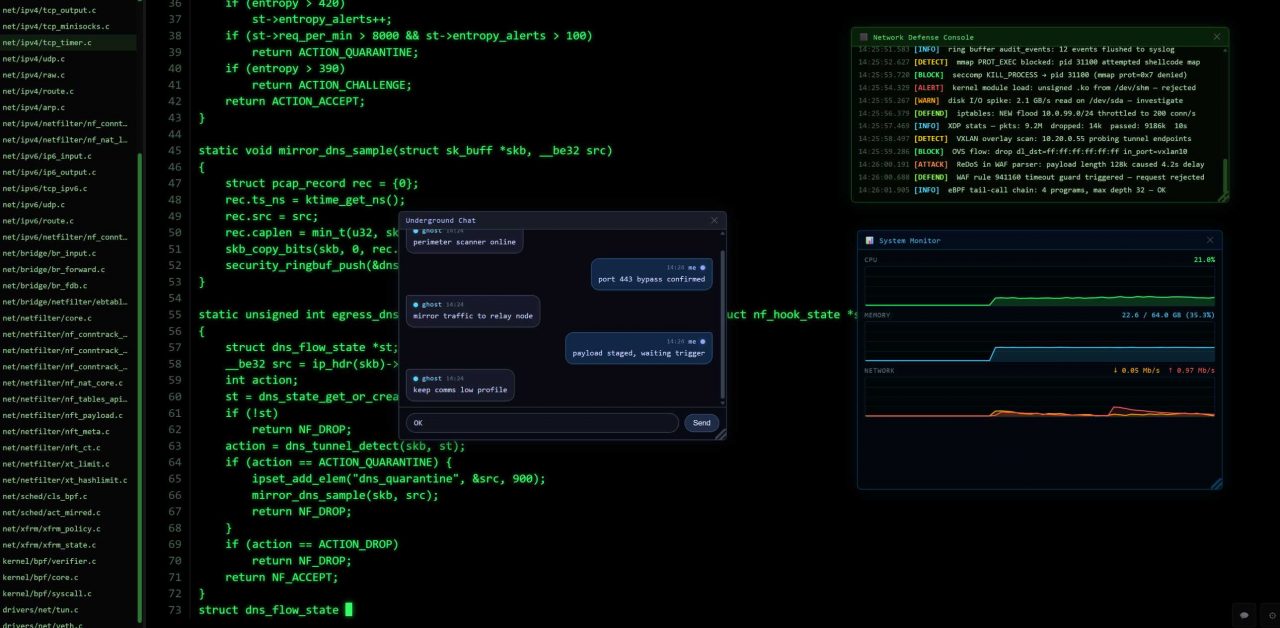
JCH Hacker Typer:https://hackertyper.jianchihu.net/ Make your screen look like a real hacker command center in seconds. JCH Hacker Typer is built for normal users who want a cool, cinematic, and shareable experience — no technical knowledge needed. Why People Love It Instant “Hacker Movie” Atmosphere Press any key and watch realistic code flow across a dark terminal screen with a glowing cursor. Auto Typing Mode Turn on Auto Typing and the page keeps typing by itself — perfect for recording videos, livestream backgrounds, or event displays. Chat Simulation That Looks Real Includes a realistic chat window with: left/right message bubbles avatar dots and timestamps typing effect with blinking cursor your own input and Send button delayed auto-replies for a live conversation feel Dynamic Security Dashboard Feel Floating windows make the scene more convincing: security operation console system monitor with moving CPU, memory, and network charts Easy Visual Personalization Change colors, font size, backgrounds, and chat style to match your personal vibe or content theme. Better “Real Coding” Look Show line numbers and file navigation for a stronger developer-style impression. Feature Screenshots Main Hacker Interface Chat Simulation Window System Monitor Window Settings Panels Chat Settings Panels Best Use Cases Social media short videos Livestream visual effects Cyber-style personal homepage Film/TV background screens Event booth attract screens Ready to Promote If you want a website that looks modern, technical, and eye-catching, JCH Hacker Typer is a strong visual tool for audience attention. Use it to create a memorable first impression — and make your content instantly more engaging.

引言 随着短视频行业的蓬勃发展,视频编辑工具的需求日益增长。剪映国际版(CapCut)在国外占有很大市场。然而CapCut的恶心收费让那些老外感到恼火,这些老外骂起来也够狠。 至于怎么骂,可以看下这个链接:https://opencut.app/why-not-capcut,如下是部分截图: 因此,一个名为 OpenCut 的开源项目应运而生,旨在成为CapCut的免费替代品,为用户提供强大且无需联网的视频编辑体验。 OpenCut 是什么? OpenCut作为一款免费、开源的视频编辑软件,致力于为用户提供媲美CapCut的视频编辑体验。支持Web、桌面端和移动端。OpenCut追求简单高效、隐私至上,所有视频内容都存储在本地,无需联网即可完成编辑,真正做到无水印、无订阅费用。 截至目前,该项目在 GitHub 上已获得超过8200个星标,还在快速上涨。 OpenCut 与 CapCut 的对比 特性 OpenCut CapCut 价格 完全免费,无订阅 部分功能需付费订阅 水印 无水印 免费版有水印 隐私 本地存储,无需联网 需联网,数据可能上传云端 跨平台支持 Web、移动端、桌面端支持 Web、移动端、桌面端支持 开源 是(MIT 许可证) 否 功能 多轨编辑、实时预览、特效等 功能丰富,但部分需付费解锁 从上表可以看出,OpenCut 在免费、无水印和隐私保护方面具有优势,适合预算有限以及注重隐私的用户。 核心功能 基于时间轴的多编辑 多轨道支持 实时预览 无水印且无需订阅 数据分析由Databuddy提供,100%匿名化且非侵入性 项目结构 apps/web/ – 主Next.js网站应用 src/components/ – UI和编辑器组件 src/hooks/ – 自定义React钩子 src/lib/ – 工具和API逻辑 src/stores/ – 状态管理(Zustand等) src/types/ – TypeScript类型 安装部署 参考:https://github.com/OpenCut-app/OpenCut 支持一键部署到免费的Vercel。 结语 之前以为老外有很好的付费习惯,没想到CapCut把国内恶心的收费毛病带到国外,惹毛老外。OpenCut目前实现还比较基础,不过开源社区的力量很强大,希望OpenCut后续能发展壮大,这个市场需要一点竞争。 参考 [1] https://github.com/OpenCut-app/OpenCut. [2] https://opencut.app/.

今天wordpress更新到6.8.1后页面顶部一直显示: Notice: 函数 _load_textdomain_just_in_time 的调用方法不正确。 kratos域的翻译加载触发过早。这通常表示插件或主题中的某些代码运行过早。翻译应在 init 操作或之后加载。 请查阅调试 WordPress来获取更多信息。 (这个消息是在 6.7.0 版本添加的。) in /usr/home/wh-axha23av59io7kixhgl/htdocs/wp-includes/functions.php on line 6121 参考这篇文章:https://xuv.cc/110/,删除主题文件style.css如下一行修复: [crayon-69e8f2ddb3b4a855693152/] 后面发现插件也有类似报错,懒得折腾,直接wp-config.php中关闭debug错误信息显示: [crayon-69e8f2ddb3b53676556809/]
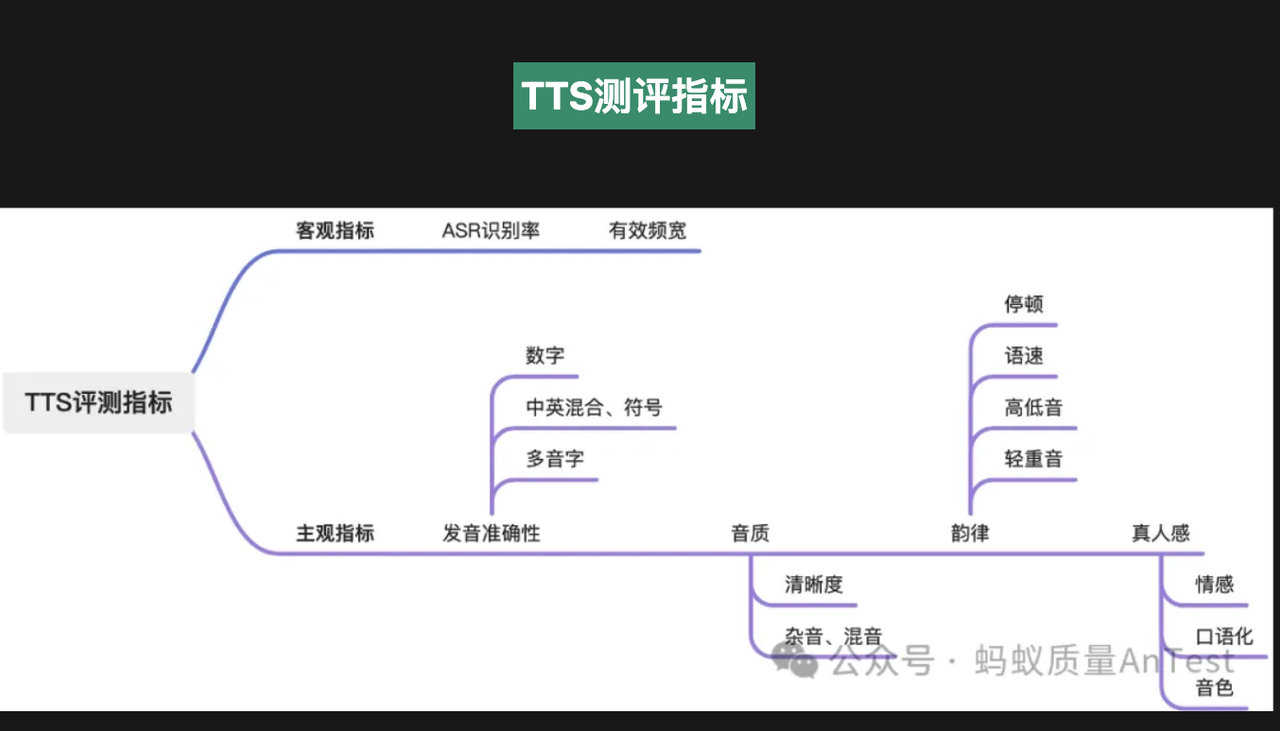
Preface With the arrival of the era of large-model voice conversations (ChatGPT-4o, Gemini Live, Doubao, etc.), high-naturalness, zero/few-shot voice cloning has become one of the core pain points for AI application deployment. Whether it’s AI short-drama dubbing, personalized digital humans, voice customer service, podcast/audiobook production, or localized private deployment, the quality, latency, VRAM usage, and cross-language capabilities of voice-clone TTS directly determine the user experience. This article is a record of evaluating and comparing more than a dozen open-source TTS solutions in early 2025. TTS Evaluation Survey (Basic Tools) Before comparing specific models, here is a brief list of commonly used objective and subjective evaluation methods to help verify results. TTS Evaluation Practices in the Era of Large-Model Voice Conversations Link:QECon Tech Sharing – TTS Evaluation Practices in the Era of Large-Model Voice Conversations Microsoft Pronunciation Assessment Service Link:Using Pronunciation Assessment This introduces how to use Azure Speech Service’s pronunciation assessment feature to automatically evaluate user pronunciation through programming. It can analyze metrics such as accuracy, fluency, and completeness, and is suitable for language learning, speech training, and similar scenarios. seed-tts-eval (Most Commonly Used Objective Metrics) Link:https://github.com/BytedanceSpeech/seed-tts-eval This is used for the most basic evaluations. Almost every TTS model paper provides these two metrics: Word Error Rate(WER)and Speaker Similarity(SIM)。 For WER, Whisper-large-v3 is used for English and Paraformer-zh for Chinese as the automatic speech recognition (ASR) engines. For speaker similarity, a WavLM-large model fine-tuned on speaker verification tasks is used to extract speaker embeddings, and cosine similarity is calculated between each test speech sample and the reference speech sample. Mainstream…
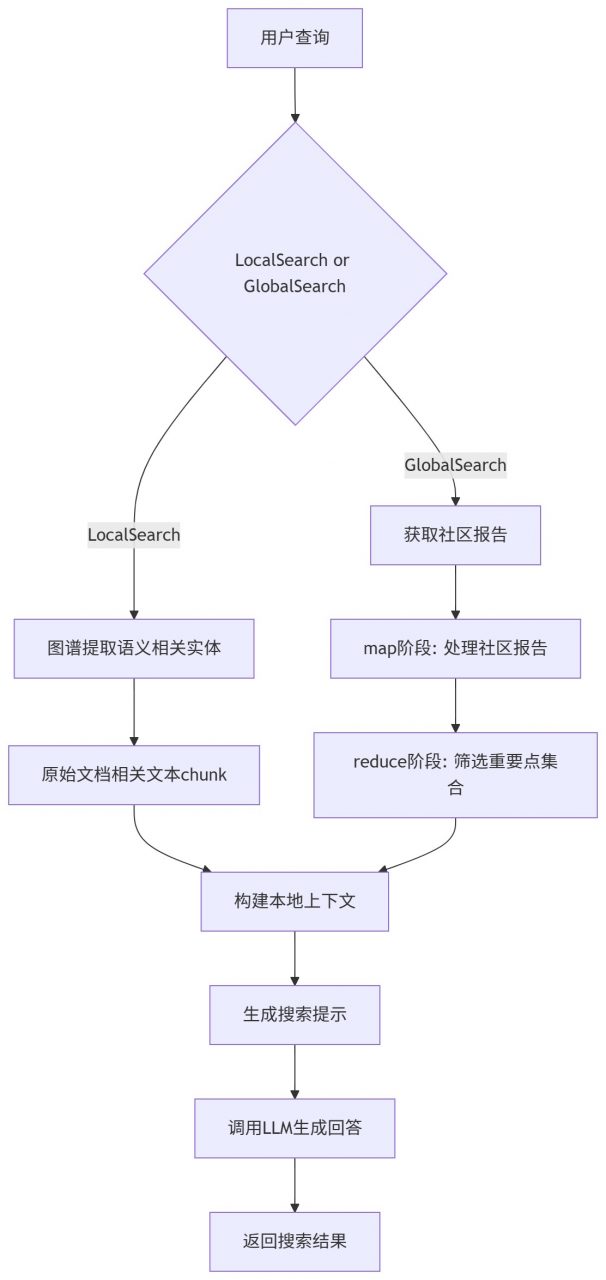
Conda 环境 [crayon-69e8f2ddb451a713492926/] Ollama配置 [crayon-69e8f2ddb4523633561506/] 通过Ollama下载需要的大语言模型以及嵌入模型,这里用的阿里千问以及nomic。 [crayon-69e8f2ddb4527422605940/] 代码下载以及依赖安装 [crayon-69e8f2ddb452a723985741/] 环境配置 创建一个目录用于存放输入的文本数据集,例如txt,csv文档。 [crayon-69e8f2ddb452e620874036/] 初始化./ragtest目录用于生成默认环境配置文件。 [crayon-69e8f2ddb4531972352178/] ./ragtest目录下settings.yaml为默认配置文件,配的是Chatgpt模型,由于我们通过Ollama使用本地大模型,所以需要修改配置,可以使用如下内容直接替换settings.yaml中的配置: [crayon-69e8f2ddb4534744955163/] 修改内容如下: [crayon-69e8f2ddb4537814851851/] 配置文件参数说明参考:https://microsoft.github.io/graphrag/posts/config/json_yaml/ 提示词微调 在当前工作目录ragtest下,用于大模型提取实体以及关系等的提示词默认存放在prompts子目录下,可通过settings.yaml修改提示词目录。对于特定领域,默认提示词模板表现不佳。这里我们可以通过官方提供的方法进行提示词微调,替换默认提示词模板,从而提高在特定领域上的表现。 自动模板 可以通过配置domain,language等参数,生成符合我们要求的提示词模板,如下是针对某电影拍摄书籍的一个自动模板提示词微调示例。这样就会在prompt目录下生成新的提示词模板,更符合拍摄领域。 [crayon-69e8f2ddb453b885174168/] 详细参数配置可以参考:https://microsoft.github.io/graphrag/posts/prompt_tuning/auto_prompt_tuning/ 手动提示词微调 按照规范自己写一个提示词模板,参考:https://microsoft.github.io/graphrag/posts/prompt_tuning/manual_prompt_tuning/ 执行索引 这一步会通过大模型提取实体,关系等,构建知识图谱,耗时较久。 [crayon-69e8f2ddb453f263990486/] 搜索 索引阶段提取的结构被用来提供材料,作为LLM的context来回答问题。查询模式包括本地和全局的搜索: 本地搜索:通过图谱中实体关联信息和原始文档相关文本块来推理关于特定实体的问题 全局搜索:通过社区的总结来推理关于语料库整体问题的答案 本地搜索 [crayon-69e8f2ddb4542061860247/] 全局搜索 [crayon-69e8f2ddb4545806908294/] 参考 [1] https://microsoft.github.io/graphrag/posts/query/overview/
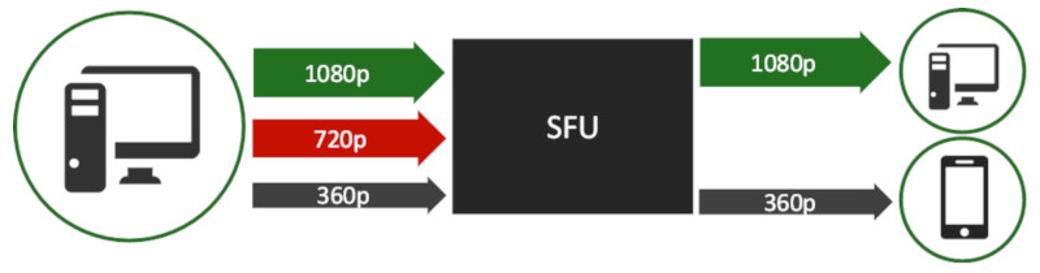
基于SFU架构的视频会议系统中,Simulcast是最主流的带宽自适应方案。发布端(Publisher)同时编码并发送多路不同分辨率的流(通常为小、中、大三路),订阅端(Subscriber)则根据自身网络带宽、设备性能、窗口大小等因素,选择订阅最合适的单路流。这种设计发布端与订阅端互不干扰: 发布端仅受自身上行带宽和编码负载影响 订阅端仅受自身下行带宽,解码能力,显示窗口影响 但在实际生产环境中,某些核心场景却需要订阅端能够“反向影响”发布端,即实现backpressure(反压)机制。 反压需求场景 按需推流 当会议中所有订阅端都处于小窗口显示(如宫格数较多、缩略图模式)时,大家只会订阅小流。此时发布端若仍持续推送大流,就会造成巨大的上行带宽浪费和服务器转发压力。理想状态是:订阅端集体选择小流 → SFU 通知发布端自动降档,只推小流即可。 SFU模拟点对点(P2P)通话 用SFU统一实现1对1通话(便于后续扩展多人)。此时必须达到原生P2P(ICE直连)的体验。 订阅端网络恶化时,不能仅靠切换Simulcast层(因为只有一层流),而应直接让发布端降低编码码率/分辨率 订阅端网络恢复后,发布端也要快速回升 在传统Simulcast中做不到这样的“端到端拥塞控制”。 SFU如何实现订阅端反压 核心思路:在SFU内部为每个发布源(Source)和每个订阅接收器(Sink) 建立反馈通道,让订阅客户端的带宽估计结果能够传递到发布客户端。 下面是实现原理图: 发布客户端 → RTP → SFU Source(发布源) SFU Sink(订阅接收器)收到订阅端发来的 Transport-CC报文,进行下行带宽估计 Sink通过onFeedback接口将估计带宽值传递给对应的Source Source封装REMB(Receiver Estimated Maximum Bitrate)RTCP报文,传回到发布客户端 发布客户端收到REMB后,强制限制自身带宽估计值 这样就实现了订阅端 → SFU → 发布端的完整反压闭环。 REMB RTCP报文复用 WebRTC早期就内置了REMB RTCP,用在最早的接收端带宽估计中,接收端的带宽估计就是通过REMB反馈到发布端。虽然现在是Transport-CC + Sendside BWE,但REMB仍然被支持。这里可以看下REMB报文格式: [crayon-69e8f2ddb4ed0312973405/] 对于SFU,带宽反馈处理只需在 Source 侧调用: [crayon-69e8f2ddb4ed9050475600/] 发布客户端中WebRTC收到REMB后的处理如下: [crayon-69e8f2ddb4edd526970156/] 至此我们完成初步的反压实现。 遗留问题:弱网解除后带宽恢复速度慢 前面实现后还有个问题,就是订阅端弱网恢复后,恢复之前码率较慢。原因如下: 订阅端之前带宽差 → SFU反馈低REMB → 发布端码率被压得很低 订阅端网络恢复 → 其BWE想提升,但实际收到的码率仍然很低(受发布端限制) 订阅端BWE探测不到更高带宽 → 继续反馈低REMB → 发布端无法提升 → 形成“死循环” 这就像“受制于人”,恢复速度远慢于原生的P2P实现。 这时候我们可以在SFU的Sink(下行)侧中,主动注入探测流量,也就是引入探测(Padding)包。让订阅端能够获得额外码率进行更大带宽探测,打破死循环,加快恢复到之前码率。 总结 通过以上机制,SFU不仅保留了Simulcast的灵活性,还具备了端到端拥塞控制能力,让视频会议在复杂网络环境下也能提供接近原生P2P的流畅体验。

目前H265应用越来越广泛,很多设备都支持硬件加速的H265编解码。作为最常见的音视频终端,Chrome在过去一直都没有H265支持的,毕竟不是AV1那样的亲儿子。人们为了让Chrome完整支持H265,用上了各种招式,例如传输上,用到了datachannel/WebTransport传输H265码流,解码上用到了wasm。 在Native端,要支持H265,得自己魔改WebRTC代码,例如第三方开源WebRTC库:Intel的OWT。现在这些状况就要改变了,目前Chrome已经支持H265硬解,WebRTC上也开始进行H265支持的开发,这一切都要从这个讨论开始: Issue 41480904:Unblock Chrome platform support of H.265 (including H26xPacketBuffer),提到目前很多安防摄像机都是默认H265编码,修改为H264代价太高,大概率是国人提的需求😀。 目前WebRTC中H265代码由Intel团队的人提交,跟Intel自己的开源WebRTC库OWT中代码相似。目前代码中(截至2023.9.20)中主要三个提交,增加了H265 Nalu的解析,SDP中相关定义,RTP包处理/编解码器相关预留H265坑位,离实际能使用还有很多事情要做,如果感兴趣,也可以先看下Intel OWT中的H265代码,代码中搜索OWT_ENABLE_H265字段,就可以看到H265相关。本文后续也将继续跟踪H265进展。 2025-03-12代码更新 Revert the deletion of WebRTC-VideoH26xPacketBuffer flag [crayon-69e8f2ddb5851501007234/] 如上提交后,之前提到的Issue 41480904也被标记为fixed了,从2021到2025四年的跨度,WebRTC总算完成H265的支持。 根据提交代码可以知道,WebRTC-VideoH26xPacketBuffer特性默认关闭的,接收到视频RTP包时,相关处理如下: [crayon-69e8f2ddb5859618352523/]
Recent Comments
Miles0u Published at 3 hours ago(04 04202643009 22 22pm26)
Addiea9 Published at 2 weeks ago(04 04202643001 08 08am26)
snail Published at 4 weeks ago(03 03202633105 27 27pm26)
dongxuh Published at 9 months ago(07 07202573103 27 27pm25)
南南 Published at 9 months ago(07 07202573103 15 15pm25)