在Webrtc中存在两种不同的audio level定义,本篇文章我们将介绍下这两种不同的audio level。
AudioDeviceBuffer中的level
在WebRTC中通过AudioDeviceBuffer传递采集播放数据,这里我们将介绍AudioDeviceBuffer中的audio level相关情况。首先先简单介绍下AudioDeviceBuffer在采集播放过程的作用。
音频采集
音频采集模块通过调用AudioDeviceBuffer的SetRecordedBuffer与DeliverRecordedData传递采集数据。
- SetRecordedBuffer:把采集数据存到
AudioDeviceBuffer的缓存中,调用UpdateRecStats进行采集统计 - DeliverRecordedData:将刚才缓存的数据传递给
AudioTransport,从而送到3A以及发送模块
音频播放
音频播放模块通过调用AudioDeviceBuffer的RequestPlayoutData以及GetPlayoutData获取要播放的数据。
- RequestPlayoutData:通过
AudioTransport获取要播放的数据,并存到AudioDeviceBuffer的缓存中,调用UpdatePlayStats进行播放统计 - GetPlayoutData:获取刚才缓存的播放数据
统计日志
前面提到调用接口都是由采集播放线程驱动的。通过调用接口会同时调用音频的统计。
一般排查音频采集播放问题,我们可以通过AudioDeviceBuffer中的统计日志判断,如下是一个示例日志:
|
1 2 |
(audio_device_buffer.cc): [REC : 10000msec, 48kHz] callbacks: 1000, samples: 480000, rate: 48000, rate diff: 0%, level: 500 (audio_device_buffer.cc): [PLAY: 10000msec, 48kHz] callbacks: 1000, samples: 480000, rate: 48000, rate diff: 0%, level: 1000 |
该日志会打印10s内采集播放情况。
- callbacks:表示接口调用次数,一般是默认10ms采集播放一次,所以10s内会调用1000次
- samples:表示实际音频采集播放样本数,由于示例中采样率为48k,所以10ms样本数为480,所以10s采集播放样本数都为480000
- rate:表示实际采集播放速率,也就是每秒的采集播放样本数
- rate diff:表示实际采集播放速率跟采集播放设置的采样率差异,百分数表示,这个值不为0,可能是抖动以及丢音情况
- level:这里的level是通过调用
WebRtcSpl_MaxAbsValueW16计算的,WebRtcSpl_MaxAbsValueW16用于计算16bit音频样本数据的最大绝对值,这个level表示10s内采集播放数据的最大绝对值,也就是最大振幅
至此我们介绍完了AudioDeviceBuffer中的level,这个level表示音频数据的最大振幅,一般我们可以通过统计日志中这个level初步判断下音频数据情况,例如是否静音。
报头扩展中的level
这节我们介绍下音频报头扩展中的audio level。
audio level header extension
根据rfc6464,audio level报头扩展的作用是方便会议转发服务器根据携带的audio level信息进行音频选择转发处理,尤其在音频流非常多情况下。转发服务器可以根据audio level信息,转发最active的几路流,一般是选择3路,从而节省带宽等资源。
rfc中的定义
audio level扩展有两种不同的格式。
one-byte header格式:
|
1 2 3 4 5 |
0 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | ID | len=0 |V| level | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
- V:1bit,标识该音频包是否包含语音(voice activity),为1含有语音。这个字段是否用到由SDP中是否包含"vad="决定,后面SDP小节介绍
- level:7bit,范围为0(最大声)~127(静音),单位-dBov,也就是0到-127dBov
db表示分贝,用于度量声音强度,计算公式如下:
\[
L_{p} = 20log_{10}(\frac{p_{rms}}{p_{ref}})db
\]
计算分贝需要参考值Pref,db后面带的后缀表示用到的参考值,dBov的ov后缀表示overload,参考系统的overload point,也就是当前payload格式音频所能忍受的最大声。
two-byte header格式:
|
1 2 3 4 5 |
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | ID | len=1 |V| level | 0 (pad) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
WebRTC中默认都是使用one-byte header格式。这里我们看下one-byte header解析以及构造代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
// rtp_header_extensions.cc bool AudioLevel::Parse(rtc::ArrayView<const uint8_t> data, bool* voice_activity, uint8_t* audio_level) { // One-byte and two-byte format share the same data definition. if (data.size() != 1) return false; // 得到第一个bit信息 *voice_activity = (data[0] & 0x80) != 0; // 得到后7bit信息 *audio_level = data[0] & 0x7F; return true; } bool AudioLevel::Write(rtc::ArrayView<uint8_t> data, bool voice_activity, uint8_t audio_level) { // One-byte and two-byte format share the same data definition. RTC_DCHECK_EQ(data.size(), 1); RTC_CHECK_LE(audio_level, 0x7f); data[0] = (voice_activity ? 0x80 : 0x00) | audio_level; return true; } |
SDP中的audio level header extension
先看下一段音频示例sdp:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
m=audio 9 UDP/TLS/RTP/SAVPF 111 96 103 104 9 102 0 8 106 105 13 110 112 113 126 c=IN IP4 0.0.0.0 a=rtcp:9 IN IP4 0.0.0.0 a=ice-ufrag:BDVT a=ice-pwd:ELabP3awhYCel1ebUM3UQNmQ a=ice-options:trickle a=fingerprint:sha-256 13:52:46:D0:64:E2:4D:4A:F8:5A:10:AD:C1:69:EF:6D:6D:D0:FB:75:E9:9B:D5:4B:CA:50:76:83:45:CA:50:D5 a=setup:actpass a=mid:0 a=extmap:1 urn:ietf:params:rtp-hdrext:ssrc-audio-level a=extmap:2 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time a=extmap:3 http://www.ietf.org/id/draft-holmer-rmcat-transport-wide-cc-extensions-01 a=extmap:4 urn:ietf:params:rtp-hdrext:sdes:mid a=extmap:5 urn:ietf:params:rtp-hdrext:sdes:rtp-stream-id a=extmap:6 urn:ietf:params:rtp-hdrext:sdes:repaired-rtp-stream-id a=recvonly a=rtcp-mux a=rtpmap:111 opus/48000/2 a=rtcp-fb:111 transport-cc a=fmtp:111 minptime=10;useinbandfec=1 a=rtpmap:96 red/48000/2 a=rtpmap:103 ISAC/16000 a=rtpmap:104 ISAC/32000 |
可以看到其中audio level的描述如下:
|
1 |
a=extmap:1 urn:ietf:params:rtp-hdrext:ssrc-audio-level |
如果该描述尾部带有:vad=on,也就是:
|
1 |
a=extmap:1 urn:ietf:params:rtp-hdrext:ssrc-audio-level vad=on |
表示用到了header extension中的V字段,如果是”vad=off“,表示没有用到V字段。没有指定"vad=",默认表示"vad=on",WebRTC生成的SDP中没有指定"vad=",所以WebRTC中默认都是"vad=on"。
Wireshark解析的audio level
根据前面一节的SDP可知audio level扩展的ID为1,根据该ID,我们看下Wireshark中的解析:
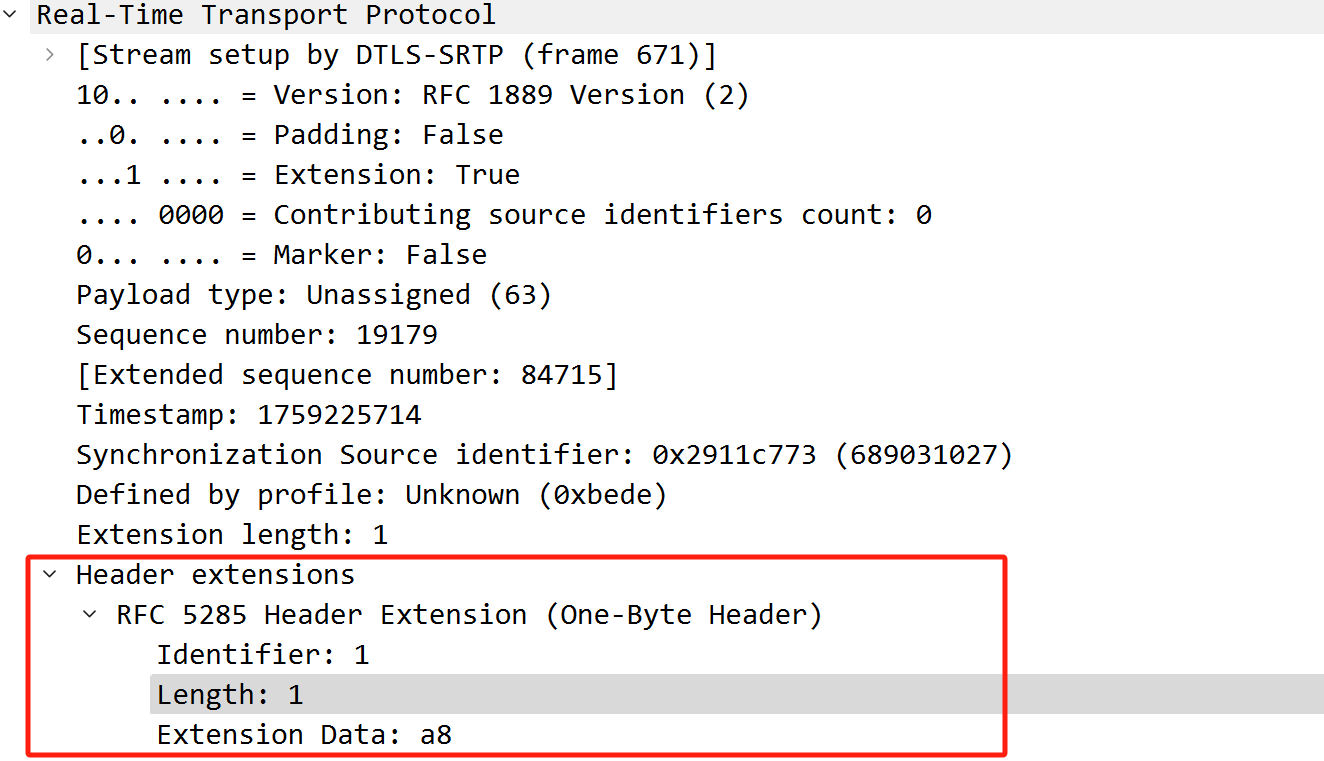
根据解析,该音频包audio level扩展数据为0xa8,可知V字段为0xa8 & 0x80 = 1,说明有语音,level字段为:0xa8 & 0x7f = 0x28,也就是audio level为40-dbov。
代码中的audio level计算
audio level通过计算均方根(Root Mean Square,RMS)得到,计算代码位于RmsLevel类中。
均方根,也叫做平方平均数(quadratic mean),是指一组数据的平方的平均数的算术平方根。
首先需要计算所有幅值平方和:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
void RmsLevel::Analyze(rtc::ArrayView<const int16_t> data) { if (data.empty()) { return; } CheckBlockSize(data.size()); const float sum_square = std::accumulate(data.begin(), data.end(), 0.f, [](float a, int16_t b) { return a + b * b; }); RTC_DCHECK_GE(sum_square, 0.f); sum_square_ += sum_square; sample_count_ += data.size(); max_sum_square_ = std::max(max_sum_square_, sum_square); } |
接着将平方和除以样本数:
|
1 2 3 4 5 6 7 8 9 10 |
enum : int { kMinLevelDb = 127 }; RmsLevel::Levels RmsLevel::AverageAndPeak() { Levels levels = (sample_count_ == 0) ? Levels{RmsLevel::kMinLevelDb, RmsLevel::kMinLevelDb} : Levels{ComputeRms(sum_square_ / sample_count_), ComputeRms(max_sum_square_ / *block_size_)}; Reset(); return levels; } |
最后根据平方和的平均数计算均方根:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
static constexpr float kMaxSquaredLevel = 32768 * 32768; // kMinLevel is the level corresponding to kMinLevelDb, that is 10^(-127/10). static constexpr float kMinLevel = 1.995262314968883e-13f; int ComputeRms(float mean_square) { if (mean_square <= kMinLevel * kMaxSquaredLevel) { // Very faint; simply return the minimum value. return RmsLevel::kMinLevelDb; } // 根据max level进行标准化处理 const float mean_square_norm = mean_square / kMaxSquaredLevel; // 20log_10(x^0.5) = 10log_10(x) const float rms = 10.f * std::log10(mean_square_norm); // 返回负值,也就是-dbov单位 return static_cast<int>(-rms + 0.5f); } |
计算后的audio level通过如下代码流程写到header extension中:
|
1 2 3 4 5 6 7 8 9 10 |
int32_t ChannelSend::SendRtpAudio() { if (_includeAudioLevelIndication) { rtp_sender_audio_->SetAudioLevel(rms_level_.Average()); } } bool RTPSenderAudio::SendAudio() { packet->SetExtension<AudioLevel>( frame_type == AudioFrameType::kAudioFrameSpeech, audio_level_dbov); } |
总结
本文介绍了WebRTC中两种audio level,其中一种表示振幅,另一种表示均方根能量。通过本文可以对音频问题初步分析以及audio level这个报头扩展增加了解。
参考
[1] A Real-time Transport Protocol (RTP) Header Extension for Client-to-Mixer Audio Level Indication.https://datatracker.ietf.org/doc/rfc6464/

Comments