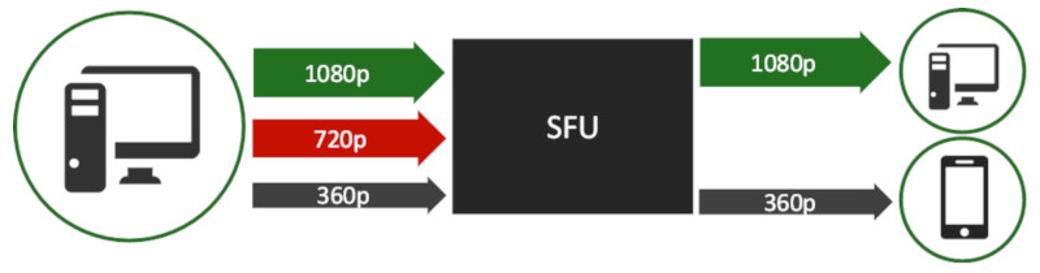
基于SFU架构的视频会议系统中,Simulcast是最主流的带宽自适应方案。发布端(Publisher)同时编码并发送多路不同分辨率的流(通常为小、中、大三路),订阅端(Subscriber)则根据自身网络带宽、设备性能、窗口大小等因素,选择订阅最合适的单路流。这种设计发布端与订阅端互不干扰: 发布端仅受自身上行带宽和编码负载影响 订阅端仅受自身下行带宽,解码能力,显示窗口影响 但在实际生产环境中,某些核心场景却需要订阅端能够“反向影响”发布端,即实现backpressure(反压)机制。 反压需求场景 按需推流 当会议中所有订阅端都处于小窗口显示(如宫格数较多、缩略图模式)时,大家只会订阅小流。此时发布端若仍持续推送大流,就会造成巨大的上行带宽浪费和服务器转发压力。理想状态是:订阅端集体选择小流 → SFU 通知发布端自动降档,只推小流即可。 SFU模拟点对点(P2P)通话 用SFU统一实现1对1通话(便于后续扩展多人)。此时必须达到原生P2P(ICE直连)的体验。 订阅端网络恶化时,不能仅靠切换Simulcast层(因为只有一层流),而应直接让发布端降低编码码率/分辨率 订阅端网络恢复后,发布端也要快速回升 在传统Simulcast中做不到这样的“端到端拥塞控制”。 SFU如何实现订阅端反压 核心思路:在SFU内部为每个发布源(Source)和每个订阅接收器(Sink) 建立反馈通道,让订阅客户端的带宽估计结果能够传递到发布客户端。 下面是实现原理图: 发布客户端 → RTP → SFU Source(发布源) SFU Sink(订阅接收器)收到订阅端发来的 Transport-CC报文,进行下行带宽估计 Sink通过onFeedback接口将估计带宽值传递给对应的Source Source封装REMB(Receiver Estimated Maximum Bitrate)RTCP报文,传回到发布客户端 发布客户端收到REMB后,强制限制自身带宽估计值 这样就实现了订阅端 → SFU → 发布端的完整反压闭环。 REMB RTCP报文复用 WebRTC早期就内置了REMB RTCP,用在最早的接收端带宽估计中,接收端的带宽估计就是通过REMB反馈到发布端。虽然现在是Transport-CC + Sendside BWE,但REMB仍然被支持。这里可以看下REMB报文格式: [crayon-69e9e4f7c4f19286617716/] 对于SFU,带宽反馈处理只需在 Source 侧调用: [crayon-69e9e4f7c4f26804672390/] 发布客户端中WebRTC收到REMB后的处理如下: [crayon-69e9e4f7c4f2a022893936/] 至此我们完成初步的反压实现。 遗留问题:弱网解除后带宽恢复速度慢 前面实现后还有个问题,就是订阅端弱网恢复后,恢复之前码率较慢。原因如下: 订阅端之前带宽差 → SFU反馈低REMB → 发布端码率被压得很低 订阅端网络恢复 → 其BWE想提升,但实际收到的码率仍然很低(受发布端限制) 订阅端BWE探测不到更高带宽 → 继续反馈低REMB → 发布端无法提升 → 形成“死循环” 这就像“受制于人”,恢复速度远慢于原生的P2P实现。 这时候我们可以在SFU的Sink(下行)侧中,主动注入探测流量,也就是引入探测(Padding)包。让订阅端能够获得额外码率进行更大带宽探测,打破死循环,加快恢复到之前码率。 总结 通过以上机制,SFU不仅保留了Simulcast的灵活性,还具备了端到端拥塞控制能力,让视频会议在复杂网络环境下也能提供接近原生P2P的流畅体验。

目前H265应用越来越广泛,很多设备都支持硬件加速的H265编解码。作为最常见的音视频终端,Chrome在过去一直都没有H265支持的,毕竟不是AV1那样的亲儿子。人们为了让Chrome完整支持H265,用上了各种招式,例如传输上,用到了datachannel/WebTransport传输H265码流,解码上用到了wasm。 在Native端,要支持H265,得自己魔改WebRTC代码,例如第三方开源WebRTC库:Intel的OWT。现在这些状况就要改变了,目前Chrome已经支持H265硬解,WebRTC上也开始进行H265支持的开发,这一切都要从这个讨论开始: Issue 41480904:Unblock Chrome platform support of H.265 (including H26xPacketBuffer),提到目前很多安防摄像机都是默认H265编码,修改为H264代价太高,大概率是国人提的需求😀。 目前WebRTC中H265代码由Intel团队的人提交,跟Intel自己的开源WebRTC库OWT中代码相似。目前代码中(截至2023.9.20)中主要三个提交,增加了H265 Nalu的解析,SDP中相关定义,RTP包处理/编解码器相关预留H265坑位,离实际能使用还有很多事情要做,如果感兴趣,也可以先看下Intel OWT中的H265代码,代码中搜索OWT_ENABLE_H265字段,就可以看到H265相关。本文后续也将继续跟踪H265进展。 2025-03-12代码更新 Revert the deletion of WebRTC-VideoH26xPacketBuffer flag [crayon-69e9e4f7c6189774704132/] 如上提交后,之前提到的Issue 41480904也被标记为fixed了,从2021到2025四年的跨度,WebRTC总算完成H265的支持。 根据提交代码可以知道,WebRTC-VideoH26xPacketBuffer特性默认关闭的,接收到视频RTP包时,相关处理如下: [crayon-69e9e4f7c6193846904720/]

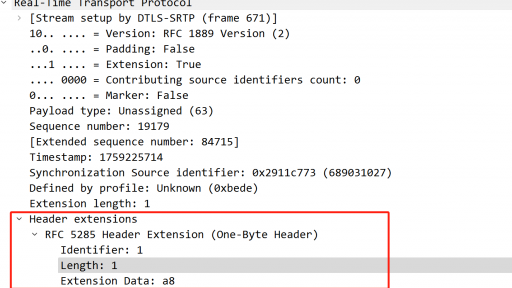
在Webrtc中存在两种不同的audio level定义,本篇文章我们将介绍下这两种不同的audio level。 AudioDeviceBuffer中的level 在WebRTC中通过AudioDeviceBuffer传递采集播放数据,这里我们将介绍AudioDeviceBuffer中的audio level相关情况。首先先简单介绍下AudioDeviceBuffer在采集播放过程的作用。 音频采集 音频采集模块通过调用AudioDeviceBuffer的SetRecordedBuffer与DeliverRecordedData传递采集数据。 SetRecordedBuffer:把采集数据存到AudioDeviceBuffer的缓存中,调用UpdateRecStats进行采集统计 DeliverRecordedData:将刚才缓存的数据传递给AudioTransport,从而送到3A以及发送模块 音频播放 音频播放模块通过调用AudioDeviceBuffer的RequestPlayoutData以及GetPlayoutData获取要播放的数据。 RequestPlayoutData:通过AudioTransport获取要播放的数据,并存到AudioDeviceBuffer的缓存中,调用UpdatePlayStats进行播放统计 GetPlayoutData:获取刚才缓存的播放数据 统计日志 前面提到调用接口都是由采集播放线程驱动的。通过调用接口会同时调用音频的统计。 一般排查音频采集播放问题,我们可以通过AudioDeviceBuffer中的统计日志判断,如下是一个示例日志: [crayon-69e9e4f7cfac1071534363/] 该日志会打印10s内采集播放情况。 callbacks:表示接口调用次数,一般是默认10ms采集播放一次,所以10s内会调用1000次 samples:表示实际音频采集播放样本数,由于示例中采样率为48k,所以10ms样本数为480,所以10s采集播放样本数都为480000 rate:表示实际采集播放速率,也就是每秒的采集播放样本数 rate diff:表示实际采集播放速率跟采集播放设置的采样率差异,百分数表示,这个值不为0,可能是抖动以及丢音情况 level:这里的level是通过调用WebRtcSpl_MaxAbsValueW16计算的,WebRtcSpl_MaxAbsValueW16用于计算16bit音频样本数据的最大绝对值,这个level表示10s内采集播放数据的最大绝对值,也就是最大振幅 至此我们介绍完了AudioDeviceBuffer中的level,这个level表示音频数据的最大振幅,一般我们可以通过统计日志中这个level初步判断下音频数据情况,例如是否静音。 报头扩展中的level 这节我们介绍下音频报头扩展中的audio level。 audio level header extension 根据rfc6464,audio level报头扩展的作用是方便会议转发服务器根据携带的audio level信息进行音频选择转发处理,尤其在音频流非常多情况下。转发服务器可以根据audio level信息,转发最active的几路流,一般是选择3路,从而节省带宽等资源。 rfc中的定义 audio level扩展有两种不同的格式。 one-byte header格式: [crayon-69e9e4f7cfacf177389447/] V:1bit,标识该音频包是否包含语音(voice activity),为1含有语音。这个字段是否用到由SDP中是否包含"vad="决定,后面SDP小节介绍 level:7bit,范围为0(最大声)~127(静音),单位-dBov,也就是0到-127dBov db表示分贝,用于度量声音强度,计算公式如下: 计算分贝需要参考值Pref,db后面带的后缀表示用到的参考值,dBov的ov后缀表示overload,参考系统的overload point,也就是当前payload格式音频所能忍受的最大声。 two-byte header格式: [crayon-69e9e4f7cfad3105429509/] WebRTC中默认都是使用one-byte header格式。这里我们看下one-byte header解析以及构造代码: [crayon-69e9e4f7cfad6198570212/] SDP中的audio level header extension 先看下一段音频示例sdp: [crayon-69e9e4f7cfad9830829013/] 可以看到其中audio level的描述如下: [crayon-69e9e4f7cfadd937883592/] 如果该描述尾部带有:vad=on,也就是: [crayon-69e9e4f7cfae0489541291/] 表示用到了header extension中的V字段,如果是”vad=off“,表示没有用到V字段。没有指定"vad=",默认表示"vad=on",WebRTC生成的SDP中没有指定"vad=",所以WebRTC中默认都是"vad=on"。 Wireshark解析的audio level 根据前面一节的SDP可知audio level扩展的ID为1,根据该ID,我们看下Wireshark中的解析: 根据解析,该音频包audio level扩展数据为0xa8,可知V字段为0xa8 & 0x80 = 1,说明有语音,level字段为:0xa8 & 0x7f = 0x28,也就是audio level为40-dbov。 代码中的audio level计算 audio level通过计算均方根(Root Mean Square,RMS)得到,计算代码位于RmsLevel类中。 均方根,也叫做平方平均数(quadratic mean),是指一组数据的平方的平均数的算术平方根。 首先需要计算所有幅值平方和: [crayon-69e9e4f7cfae3099718942/] 接着将平方和除以样本数: [crayon-69e9e4f7cfae7004332941/] 最后根据平方和的平均数计算均方根: [crayon-69e9e4f7cfaeb936161408/] 计算后的audio level通过如下代码流程写到header extension中: [crayon-69e9e4f7cfaee931563163/] 总结 本文介绍了WebRTC中两种audio level,其中一种表示振幅,另一种表示均方根能量。通过本文可以对音频问题初步分析以及audio level这个报头扩展增加了解。 参考 [1] A Real-time Transport Protocol (RTP) Header Extension for Client-to-Mixer Audio Level Indication.https://datatracker.ietf.org/doc/rfc6464/

系统要求 磁盘空间:至少5.6 GB磁盘空间(带IOS支持) 准备工作 需要Xcode 9以及以上版本。 对于外网访问,我这里用的是v2rayu,在终端执行如下代理设置: [crayon-69e9e4f7d04c4443583999/] 安装depot tools [crayon-69e9e4f7d04cd667685274/] 获取代码 [crayon-69e9e4f7d04d1714019894/] 如果中间意外中断,执行gclient sync即可。 生成Ninja工程文件 WebRTC默认使用Ninja作为编译系统,Ninja工程文件通过GN生成。 使用如下命令生成默认配置工程(Debug编译,工程文件位于out\Default目录下): [crayon-69e9e4f7d04d5260676176/] 如果需要Release编译,通过如下命令生成工程文件: [crayon-69e9e4f7d04d8760093066/] 编译 [crayon-69e9e4f7d04db880589709/] 最后在src/out/Default/obj可以看到生成的静态库文件:libwebrtc.a,WebRTC.framework文件以及测试demo:AppRTCMobile。src/out/Default看到all.xcodeproj文件。 代码更新 后续如需要更新代码,按照如下步骤: [crayon-69e9e4f7d04de991513394/] 然后参考前面步骤重新生成工程文件,编译即可。 参考 [1] WebRTC Native code Development.https://webrtc.github.io/webrtc-org/native-code/development/. 本文已收录到大话WebRTC专栏,更多精彩请访问《大话WebRTC》。

RTP时间戳 RTP固定报头中,带有4字节大小的时间戳。 [crayon-69e9e4f7d1521418567647/] RTP时间戳一般以采样频率为单位。相邻两帧的时间戳增量为: RTP时间戳分为绝对时间戳跟相对时间戳。本文主要介绍这个时间戳是如何产生的。 视频RTP时间戳产生 由于视频每帧间隔也就是时间差不是稳定的,无法使用固定的时间戳增量计算时间戳,所以视频使用当前帧采集的NTP时间作为时间戳计算基础,也就是使用绝对时间戳表示。 采集阶段 调用set_timestamp_ms(rtc::TimeMillis())设置当前时间。 [crayon-69e9e4f7d152b945574753/] 编码阶段 这里将NTP时间戳转换为RTP时间戳,计算方法为: RTP时间:NTP时间(ms) * 90000(采样率) / 1000,对应代码如下: [crayon-69e9e4f7d152f382794281/] 根据rfc3551,5.Video章节,之所以使用90kHz作为采样频率是因为,90kHz跟MPEG呈现时间戳频率相同。同时90kHz差不多是24(HDTV),25(PAL),29.97(NTSC)和30Hz(HDTV)这些电视信号制式帧率以及50,59.94和60帧率的整数倍。同时使用90kHz能够满足一些场景的时间精度需要。例如: 音视频同步,需要将RTP时间戳转为NTP时间戳 抖动计算,参考:WebRTC研究:统计参数之抖动 RTP打包发送阶段 这里会在之前设置的RTP时间戳基础上加上一个随机偏移,加上这个偏移是为了防止时间戳冲突,假如同一个时刻有好几个视频源同时产生视频,它们就可能有完全一样的时间戳,对应代码如下: [crayon-69e9e4f7d1532974400235/] 至此得到了最后视频RTP包中的时间戳。 音频RTP时间戳产生 RTC中音频默认是10ms采集一次。由于采样间隔也就是时间差是稳定的,根据公式(1),相邻采集帧时间戳增量为: 10ms * 采样率 / 1000 = 采样率 / 100,也就是每帧单声道的样本数。所以音频时间戳计算无需获取当前NTP时间,从0开始,按固定时间戳增量不断增加即可,也就是使用相对时间戳表示。 采集阶段 直接取每帧单道样本数作为时间戳增量,计算代码如下: [crayon-69e9e4f7d1535777204205/] 这样得到了每一个采集帧的时间戳。 编码阶段 Opus编码器默认设置20ms编码帧长,一个Opus编码帧包含20ms音频数据。也就是每两个10ms音频采集帧编码为一个opus帧,喂给编码器两帧10ms数据,最后编码出一帧,这时编码帧时间戳增量为:2 * 采样率 / 100,Opus编码器内部处理代码如下: [crayon-69e9e4f7d1538897163267/] Opus编码完一帧后,会将此时的RTP时间戳通过EncodedInfo返回给上层,然后送到RTP打包发送模块,对应处理代码如下: [crayon-69e9e4f7d153c939246678/] RTP打包发送阶段 跟视频RTP时间戳处理一样,也需要加上一个随机偏移: [crayon-69e9e4f7d153f379147281/] 总结 RTP时间戳在组帧,抖动计算,音视频同步等起到了重要作用,通过本文相信对RTP时间戳有了更深刻认识。 参考 [1]RFC3550.https://www.rfc-editor.org/rfc/rfc3550. [2]RFC3551.https://www.rfc-editor.org/rfc/rfc3551.
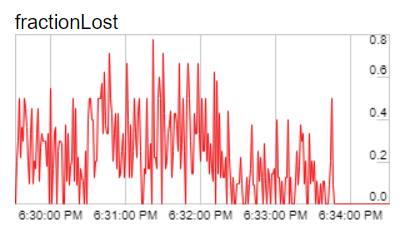
今天我们来看下chrome://webrtc-internals/页面中的一个重要统计参数:丢包率(Fraction lost)。 什么是丢包率 丢包率这个概念我想大家再熟悉不过了,一般来说,丢包率是指所丢失数据包数量占所发送数据包的比例。丢包率也是衡量网络性能的一个指标,我们通常使用丢包率判断当前网络质量,不过丢包也分为拥塞丢包,随机丢包等,随机丢包情况下,我们不能通过得到的丢包率认为当前网络质量差,发生拥塞。这也是现在很多拥塞控制算法不使用丢包率作为主要衡量指标的原因。 ping命令是最常见的一种估计丢包率的方法。下面是ping Google的示例,底部packet loss就是这次ping的丢包率检测结果。 [crayon-69e9e4f7d1eab947746907/] RTCP中的丢包信息 在WebRTC中,一般是通过Receiver report(RR)反馈丢包信息。RR记录着丢包相关统计。首先看下RR报文格式: [crayon-69e9e4f7d1eb3542142600/] 跟丢包统计有关的几个字段如下: fraction lost,自上次发送RR后SSRC_n的丢包率 cumulative number of packets lost: 24 bits,记录SSRC_n从开始到现在总共丢失的包 extended highest sequence number received: 32 bits,将序列号扩展为32bit,用于标识当前收到的最大包序列号 如上3个字段中,fraction lost根据后两个字段即可算出。前后两个RR报文间隔内fraction lost计算公式入下: [crayon-69e9e4f7d1eb7510170963/] 公式中: received_seq_max_:extended highest sequence number receive last_report_seq_max_:last extended highest sequence number received cumulative_loss_:cumulative number of packets lost last_report_cumulative_loss_:last cumulative number of packets lost 接下来我们结合接收端统计代码看下这几个参数如何计算。相关计算代码位于StreamStatisticianImpl中。 StreamStatisticianImpl代码导读 首先是根据RTP包记录相关信息: [crayon-69e9e4f7d1ebb621732403/] 接着构造RR时,根据记录的信息进行相关丢包统计参数计算 [crayon-69e9e4f7d1ebe258031601/] fraction lost 计算位于StreamStatisticianImpl::MaybeAppendReportBlockAndReset中,: [crayon-69e9e4f7d1ec1905101448/] cumulative number of packets lost 对应代码中的cumulative_loss_计算。 [crayon-69e9e4f7d1ec4889613250/] StreamStatisticianImpl::UpdateOutOfOrder中,如果是重传、乱序或者重复包,当前包sequence_number 会小于received_seq_max_。 [crayon-69e9e4f7d1ec7724889430/] 代码中提到得到的丢包率不是原始丢包率,是包括重传包后的丢包率,实际值会低于原始丢包率,这个会干扰我们的一些判断,假如每次丢包后面重传都收到,那么我们也许会得到一个丢包率为0的反馈,由于Sendside BWE中用到了这个丢包率,所以对带宽估计值有影响。那么有什么办法避免吗,如果要想得到原始丢包率,重传包就不能进入这里统计了,WebRTC提供了RTX机制,重传包用额外SSRC的包发送,这样重传包就不会干扰原始媒体包的统计。 extended highest sequence number received 收到的最新非乱序包序列号,前面提到这个字段用32bits表示,所以需要对16bits进行扩展处理。 StreamStatisticianImpl::UpdateCounters中得到64bits的序列号: [crayon-69e9e4f7d1ecb385834695/] 接着在StreamStatisticianImpl::MaybeAppendReportBlockAndReset中将该序列号传给ReportBlock: [crayon-69e9e4f7d1ece408921985/] 传递给ReportBlock时会转为32bits。 [crayon-69e9e4f7d1ed1497579694/] 发送端中的丢包率 WebRTC中通过接收端统计包接收情况,反馈给发送端,然后发送端根据这些统计进行丢包率计算。发送端中丢包率主要用在Sendside BWE中。这里先看下主要代码流程: [crayon-69e9e4f7d1edf388540438/] RtpTransportControllerSend::OnReceivedRtcpReceiverReportBlocks中根据RTCP报文中的信息提取相关信息。 [crayon-69e9e4f7d1ee2667940955/] SendSideBandwidthEstimation::UpdatePacketsLost中根据提取的信息进行丢包率计算。 [crayon-69e9e4f7d1ee5876677774/] 最后在SendSideBandwidthEstimation::UpdateEstimate中根据不同档位的丢包率进行相应的码率调整。 总结 本文主要介绍了WebRTC中丢包相关统计,以及使用非RTX方式进行丢包重传时引入的问题,最后简单介绍了下丢包统计在发送端的使用。 参考 [1] RFC3550.https://tools.ietf.org/html/rfc3550.
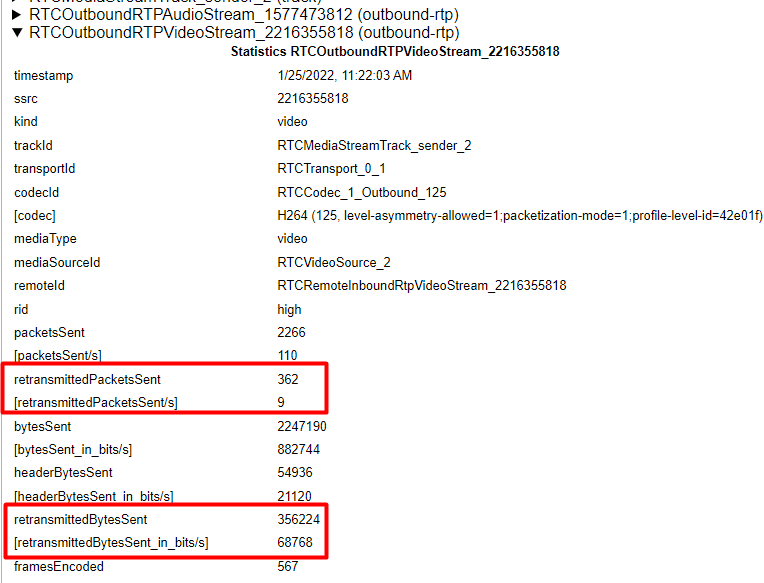
丢包检测与重传作为WebRTC中一个抗弱网机制,对提高QOS起了很大作用。WebRTC中目前主要靠NACK机制实现丢包检测与重传,接收端判断丢包情况并记录,然后通过NACK RTCP报文(RFC 4585)反馈丢包信息给发送端,发送端根据NACK报文信息进行包的重传。 NACK机制针对的是某个SSRC的单独流,对于某个SSRC流,对于一个包N,接收端要检测它是否丢了,需要前面收到的该流的包N-1,以及后面收到该流的包N+1的信息,通过检测N-1以及N+1间是否有空隙判断N是否丢了。如果因为一些特殊原因,包N+1到晚了些,那么我们就无法判断N是否丢失了,假如N真丢了,会造成包N的恢复时间变长。如果该流所在传输通道,还有其它SSRC流,那么可否借助其它流信息更早检测丢包? 目前WebRTC默认都是采用基于发送端的带宽估计(Send-side BWE),通过报头扩展携带的传输序列号Transport sequence number以及Transport Feedback RTCP报文携带的信息进行相关处理。对于单个传输通道,包含的所有流,携带的传输序列号采用统一的计数。Transport Feedback RTCP中基于传输序列号记录着包的详细信息,例如是否收到,到达时间等。既然Transport Feedback RTCP记录着接收端收到的所有流的包信息,那么就可以利用这个进行丢包检测。这样对于某个SSRC流,要检测丢包,就可以借助其他SSRC流的传输序列号了。对于单个传输通道多条流场景,例如单PC或者Simulcast,相比NACK机制,能够更早地检测到丢包情况。在WebRTC这个机制叫做早期丢包检测(Early loss detection)。 与NACK机制差异 我们通过某个例子解释下早期丢包检测机制为什么会快些。假设某个传输通道下有视频流A与B,它们的RTP包记为Ra(n,m),Rb(n,m),n表示RTP sequence number,m表示Transport sequence number,这样同一个传输通道(PeerConnection)下,视频流按如下形式传输: Ra(1,1),Ra(2,2),Rb(1,3),Rb(2,4),Ra(3,5),Ra(4,6),Rb(3,7),Rb(4,8) 假设只有Ra(2,2)丢了,在NACK机制中,只能处理单个SSRC的流,通过RTP序列号判断丢包。需要收到Ra(3,5)或者更靠后的Ra包,才能判断Ra(2,2)丢失。而在早期丢包检测机制中,可以直接通过Rb(1,3)的传输序列号判断Ra(2,2)丢失,所以能更早地检测到。 这里我们总结下跟NACK机制的差异: 1)NACK机制处理的是某个SSRC流,通过报头携带的RTP序列号判断 2)Early loss detection机制处理的是某个传输通道所有流,通过报头扩展携带的传输序列号判断。 接下来我们详细介绍下Early loss detection机制。 Transport Feedback RTCP 首先我们简单复习下Transport Feedback RTCP报文格式。Transport Feedback RTCP中记录着一系列包的到达状态以及时间。 记录的第一个RTP包传输序列号Transport sequence number为base sequence number,总共记录着packet status count个RTP包信息,这些RTP包Transport sequence number以base sequence number为基准,并依次递增。 通过packet chunk记录各个RTP包的到达状态,主要有:packet received,packet not received这两种状态。 以reference time为基准,通过recv delta记录各个"packet received"状态的包的到达时间信息。 [crayon-69e9e4f7d30ca694332446/] 检测原理 前面我们简单回顾了Transport Feedback RTCP的格式,那么通过这个RTCP检测丢包就很简单了。"packet not received"状态的包就是我们所认为的丢包。只要我们解析Transport Feedback RTCP,获取这些"packet not received"状态的包,然后通过这些RTP包的Transport sequence number,从发送端记录的RTP包发送历史中获取对应RTP包的SSRC以及RTP sequence number,告知相应发送模块,即可实现重传。 接收端 接收端主要处理代码位于RemoteEstimatorProxy::MaybeBuildFeedbackPacket中,packet_arrival_times_记录着收到的RTP包的Transport Sequence Number以及到达时间。 [crayon-69e9e4f7d30d4010065969/] 发送端 发送端处理代码位于RtpVideoSender::OnPacketFeedbackVector中。主要处理代码如下: [crayon-69e9e4f7d30d8803613761/] 通过SSRC找到对应的RTPSender,传入RTP序列号完成重传。 可能引起的问题 由于WebRTC中存在这种机制,那么我们自己编写接收端代码时需要注意一些事(一般是服务端),否则会引起问题。 举个例子,客户端上行推Simulcast流。大流B表示,小流S表示,后面跟着传输序列号。某次传输情况如下: [crayon-69e9e4f7d30dc251998554/] 假如我们服务端是单独处理大小流,构造大小流Transport Feecback RTCP报文也是单独处理,那么就会有个问题。 对大流的处理模块,收到的流为B1 B2 B3 B4 B7 B8 B9 B10,构造的Transport Feecback报文中记录的收到的传输序列号为:1 2 3 4 7 8 9 10,其中5,6由于属于小流导致记录为没收到。所以在发送端处理该Transport Feedback RTCP报文时,会将传输序列号5,6所属的RTP包重传,直到收到小流反馈的Transport Feecback报文。这样就会导致每收到反馈的Transport Feedback RTCP,就会重传RTP包,虽然并没有丢包。如果通过浏览器推流,那么在chrome://webrtc-internals/中会看到: 其中retransmittedPacketsSent一直在增加。 不过对于接收端而言,这些重传的包会被SRTP处理过滤掉,在libSRTP库中会报srtp_err_status_replay_fail错误,这是因为libSRTP的一个安全措施。libSRTP中有个窗口,记录着收到的包,如果后面收到的包在这个窗口内,会被认为是重复的包,从而报srtp_err_status_replay_fail错误,然后被丢弃。 所以编写服务端代码时,同一个传输通道的流,无论单PC,还是Simulcast场景,Transport Feecback RTCP构造得统一处理,这样就可以利用到早期丢包检测机制优势,同时避免增加不必要的带宽消耗。 总结 本文主要介绍了NACK机制与早期丢包检测机制差异,回顾了Transport Feedback RTCP报文格式,并结合代码简单介绍了早期丢包检测机制,最后举例讲了下这个机制可能引起的问题。WebRTC本身在不断演进,我们服务端开发的得时刻关注,做好兼容处理。