
引言 随着短视频行业的蓬勃发展,视频编辑工具的需求日益增长。剪映国际版(CapCut)在国外占有很大市场。然而CapCut的恶心收费让那些老外感到恼火,这些老外骂起来也够狠。 至于怎么骂,可以看下这个链接:https://opencut.app/why-not-capcut,如下是部分截图: 因此,一个名为 OpenCut 的开源项目应运而生,旨在成为CapCut的免费替代品,为用户提供强大且无需联网的视频编辑体验。 OpenCut 是什么? OpenCut作为一款免费、开源的视频编辑软件,致力于为用户提供媲美CapCut的视频编辑体验。支持Web、桌面端和移动端。OpenCut追求简单高效、隐私至上,所有视频内容都存储在本地,无需联网即可完成编辑,真正做到无水印、无订阅费用。 截至目前,该项目在 GitHub 上已获得超过8200个星标,还在快速上涨。 OpenCut 与 CapCut 的对比 特性 OpenCut CapCut 价格 完全免费,无订阅 部分功能需付费订阅 水印 无水印 免费版有水印 隐私 本地存储,无需联网 需联网,数据可能上传云端 跨平台支持 Web、移动端、桌面端支持 Web、移动端、桌面端支持 开源 是(MIT 许可证) 否 功能 多轨编辑、实时预览、特效等 功能丰富,但部分需付费解锁 从上表可以看出,OpenCut 在免费、无水印和隐私保护方面具有优势,适合预算有限以及注重隐私的用户。 核心功能 基于时间轴的多编辑 多轨道支持 实时预览 无水印且无需订阅 数据分析由Databuddy提供,100%匿名化且非侵入性 项目结构 apps/web/ – 主Next.js网站应用 src/components/ – UI和编辑器组件 src/hooks/ – 自定义React钩子 src/lib/ – 工具和API逻辑 src/stores/ – 状态管理(Zustand等) src/types/ – TypeScript类型 安装部署 参考:https://github.com/OpenCut-app/OpenCut 支持一键部署到免费的Vercel。 结语 之前以为老外有很好的付费习惯,没想到CapCut把国内恶心的收费毛病带到国外,惹毛老外。OpenCut目前实现还比较基础,不过开源社区的力量很强大,希望OpenCut后续能发展壮大,这个市场需要一点竞争。 参考 [1] https://github.com/OpenCut-app/OpenCut. [2] https://opencut.app/.
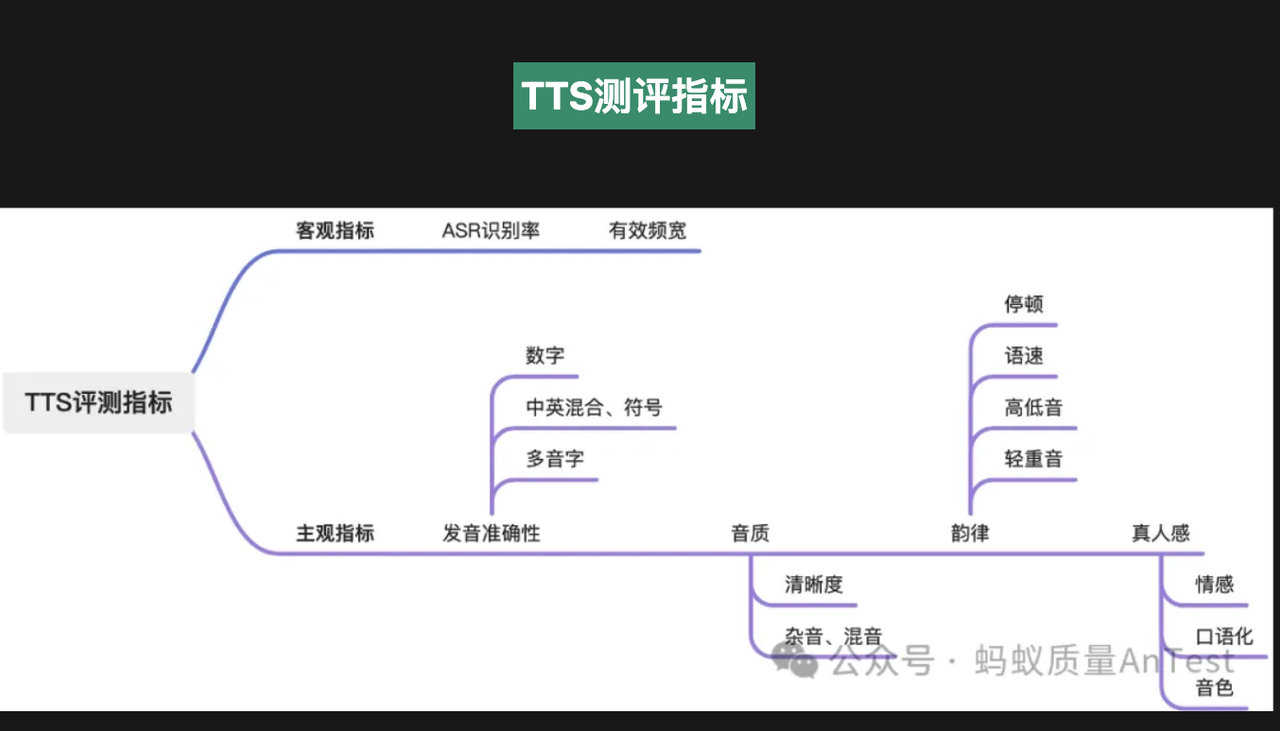
Preface With the arrival of the era of large-model voice conversations (ChatGPT-4o, Gemini Live, Doubao, etc.), high-naturalness, zero/few-shot voice cloning has become one of the core pain points for AI application deployment. Whether it’s AI short-drama dubbing, personalized digital humans, voice customer service, podcast/audiobook production, or localized private deployment, the quality, latency, VRAM usage, and cross-language capabilities of voice-clone TTS directly determine the user experience. This article is a record of evaluating and comparing more than a dozen open-source TTS solutions in early 2025. TTS Evaluation Survey (Basic Tools) Before comparing specific models, here is a brief list of commonly used objective and subjective evaluation methods to help verify results. TTS Evaluation Practices in the Era of Large-Model Voice Conversations Link:QECon Tech Sharing – TTS Evaluation Practices in the Era of Large-Model Voice Conversations Microsoft Pronunciation Assessment Service Link:Using Pronunciation Assessment This introduces how to use Azure Speech Service’s pronunciation assessment feature to automatically evaluate user pronunciation through programming. It can analyze metrics such as accuracy, fluency, and completeness, and is suitable for language learning, speech training, and similar scenarios. seed-tts-eval (Most Commonly Used Objective Metrics) Link:https://github.com/BytedanceSpeech/seed-tts-eval This is used for the most basic evaluations. Almost every TTS model paper provides these two metrics: Word Error Rate(WER)and Speaker Similarity(SIM)。 For WER, Whisper-large-v3 is used for English and Paraformer-zh for Chinese as the automatic speech recognition (ASR) engines. For speaker similarity, a WavLM-large model fine-tuned on speaker verification tasks is used to extract speaker embeddings, and cosine similarity is calculated between each test speech sample and the reference speech sample. Mainstream…

数字图像 平时我们看到的视频其实是由一幅幅图像组成,所以先来了解下数字图像。 数字图像由一个个像素组成,是二维图像用有限数字数值像素的表示。如下路所示,我们放大一个图像后,能明显看到一个个像素块: 图像分辨率 水平分辨率指的一幅图像的宽,垂直分辨率指的一幅图像的高。一般说的分辨率用水平分辨率(宽)X 垂直分辨率(高)表示。 常见分辨率有: QVGA:320x240 CIF:352×288 VGA:640x480 HD:1360x768 FHD:1920x1080 WQHD:2560x1440 4K UHD:3840x2160 数字图像编码方法 指的是图像中每一个像素点在计算机中用什么编码方法表示。 RGB 人的眼睛是根据所看见的光的波长来识别颜色的。可见光谱中的大部分颜色可以由三种基本色光按不同的比例混合而成,这三种基本色光的颜色就是红(Red)、绿(Green)、蓝(Blue)三原色光。这三种光以相同的比例混合、且达到一定的强度,就呈现白色(白光);若三种光的强度均为零,就是黑色(黑暗)。这就是加色法原理,加色法原理被广泛应用于电视机、监视器等主动发光的产品中。 RGB存储表示 每个像素至少包含R、G、B分量,逐个像素存储。 RGB16:每像素占2字节,R、G、B分别用5bit,6 bit,5 bit表示。 RGB24:每像素占3字节,R、G、B各占一字节。 RGB32:每像素占4字节,A(Alpha)、R、G、B各占一字节。 YUV "Y"表示明亮度(Luminance),"U"和"V"则是色度、浓度(Chrominance、Chroma)。之所以使用YUV编码方法,主要有这些原因: R、G、B三个分量的相关性很强,存在冗余,使用YUV后可进行数据压缩 人眼对亮度信号较敏感,对色度信号较不敏感,可通过较少UV分量进行数据压缩 彩色信号能很好兼容黑白电视,黑白视频只有Y分量 YUV、YCbCr YUV解决彩色信号对黑白电视的兼容,黑白电视也能接收彩色电视信号。 Y:亮度(黑白图像) UV:彩度 YUV针对模拟信号。YCbCr模型针对数字信号,是YUV压缩和偏移的版本。一般俗称的YUV大多是指YCbCr。如下是某YCbCr图像的三个分量组成,其中其中Y是指亮度分量,Cb指蓝色色度分量,而Cr指红色色度分量。 YUV与RGB的转换 YUV与RGB可以按公式进行互相转换,具体可参考文末的参考[1]。 YUV采样 YUV 4:4:4采样,每一个Y对应一组UV分量。24 Bits per Pixel。 YUV 4:2:2采样,每两个Y共用一组UV分量。16 Bits per Pixel。 YUV 4:2:0采样,每四个Y共用一组UV分量。12 Bits per Pixel。 上图中黑点表示采样该像素点的Y分量,以空心圆圈表示采用该像素点的UV分量。 YUV 存储格式 YUV的存储格式有两大类: 紧缩格式(packed formats):将Y、U、V值存储成Macro Pixels数组,和RGB的存放方式类似。YUV4:4:4格式而言,用紧缩格式最合适。大概格式为:YUVYUVYUVYUV 平面格式(planar formats):将Y、U、V的三个分量分别存放在不同的矩阵中。大概格式为:YYYYUV。 YUV常见表示方法 根据采样方式和存储格式的不同,就有了多种 YUV 格式。这些格式主要是基于 YUV 4:2:2 和 YUV 4:2:0 采样。 常见的几乎都是基于YUV4:2:0: YU12。先存储 Y 分量,再存储 U、V 分量。例如:YYYYYYYYUUVV。 YV12 ,又称作 I420 格式。它的存储格式就是把 V 和 U 反过来了。例如:YYYYYYYYVVUU。 NV12。先存储了Y分量,但接下来并不是再存储所有的U或者V分量,而是把UV分量交替连续存储。例如:YYYYYYYYUVUV。NV12在硬件编解码中用的比较多。 如下图所示,为YUV420的存储格式,每4个Y对应一组UV: 视频 连续的图像变化每秒超过24帧(frame)画面以上时,根据视觉暂留原理,人眼无法辨别单幅的静态画面,看上去是平滑连续的视觉效果,这样连续的画面叫做视频。视频里面的每一幅图像称为一帧。 视频图像扫描 包括显示器扫描和摄像机视频捕获扫描两个环节。分为逐行扫描和隔行扫描两种扫描方式。 隔行扫描(Interlace Scanning) 每帧分为两场:奇数行组成奇数场,偶数行组成偶数场。 在显示器扫描中,隔行扫描指在显示一幅图像时,先扫描奇数行,再扫描偶数行,因此每幅图像需扫描两次才能完成。 摄像机在进行视频捕获时,例如对于25帧视频,每秒钟扫描50场,每一场只有半幅图像,意味着我们看到的图像的每一帧都是由两个采集时间不同的“半幅”图像合并而成的。当我们观看隔行扫描的视频时,会出现行间闪烁、运动模糊、垂直边缘锯齿等现象,从而影响画面清晰度。一般比较早期的视频是隔行扫描采集的。如下是一个隔行扫描视频截图,可以看到人物运动时有明显的锯齿。 该视频链接如下,大家可以认真看下人物运动时的边缘: https://music.163.com/#/mv?id=5309079 逐行扫描(Progressive Scanning) 每次扫描完所有行,从上到下逐行扫描。在显示器扫描中,逐行扫描指从上到下的扫描每一行图像。摄像机在进行视频捕获时,例如对于25帧视频,每秒钟扫描25场,每一场是完整一副图像。画面平滑干净、细节清晰、没有闪烁感、也不会产生运动模糊与锯齿现象。 1080P和1080i的区别 1080i:就是1920x1080分辨率。不过这种高清图像是隔行扫描(Interlace Scanning)的。每一个奇数行图像都在每一偶数行图像后面显示出来,当然图像就不会那么平滑。1080i适于表现纪录片和野生动物等题材,但是不是那么适合播放运动和电影类的内容。 1080p:也是1920x1080分辨率。和1080i的区别就在于1080p不是隔行扫描的,而是逐行扫描(Progressive Scanning)。每一线都同时表现在画面上,因此比隔行扫描更加得平滑。这是更高的高清标准。 视频时间戳(Timestamp) 每一帧的采样时间tn(相对)为时间戳。时间单位为采样频率或具体时间单位(如毫秒)。 RTP timestamp是用采样频率表示时间的。两帧之间RTP timestamp的增量 = 采样频率 / 帧率 例如:90kHz作为视频采样频率,视频帧率为25fps,相邻帧间RTP timestamp增量值 = 90000/25 = 3600。 视频帧率(Frame rate) 每秒播放的图像帧数量(Frames per Second,简:fps)。目前常见帧率:25fps、30fps、60fps、90fps、120fps。 视频码率(Bitrate) 单位时间传送的数据bit数,一般我们用的单位是kbps,也就是数据bit数除以1000(不是1024,发现很多人这个很容易搞错)。 码率越大,单位时间包含的数据越多,视频质量越好。目前有如下两种码率类型: 可变码率(Variable bitrate,简称VBR),指编码码率会随图像的复杂程度的不同而变化。 固定码率(Constant bitrate,简称CBR),指编码码率是固定的。 视频压缩的必要性 1920x1080@30fps视频的每秒数据量: RGB:1920x1080x3x30 = 186624000B = 186M YUV420:1920x1080x1.5x30 = 93M 可以看到数据量非常大。所以为了存储以及网络带宽要求,需要对视频数据进行压缩。 视频压缩原理 利用了视频数据的冗余。例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。通过消除这些冗余信息实现视频数据的压缩。 时间上的冗余信息(temporal redundancy)。在视频数据中,相邻的帧(frame)与帧之间通常有很强的关连性,这样的关连性即为时间上的冗余信息。 空间上的冗余信息(spatial redundancy)。在同一张帧之中,相邻的像素之间通常有很强的关连性,这样的关连性即为空间上的冗余信息。 统计上的冗余信息(statistical redundancy)。统计上的冗余信息指的是欲编码的符号(symbol)的几率分布是不均匀(non-uniform)的。 视觉冗余。人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。 如下图为视频相邻帧间时间上的冗余信息,可以看到只有头部对应的像素发生了变化: 下图为利用空间上的冗余信息进行帧内压缩(后面提到的I帧压缩原理): 下图为利用时间上的冗余信息进行数据压缩(后面提到的P帧压缩原理),参考了前面的视频帧: 下图为利用时间上的冗余信息进行数据压缩(后面提到的B帧压缩原理),参考了前面以及后面的视频帧: 视频编解码器(Codec) 能够对数字视频进行压缩或者解压缩的程序或者设备。下图为一个典型的视频编码器。在进行当前信号编码时,编码器首先会产生对当前信号做预测的信号,称作预测信号(predicted signal),预测的方式可以是时间上的预测(inter prediction),亦即使用先前帧的信号做预测,或是空间上的预测(intra prediction),亦即使用同一张帧之中相邻像素的信号做预测。得到预测信号后,编码器会将当前信号与预测信号相减得到残余信号(residual signal),并只对残余信号进行编码,如此一来,可以去除一部分时间上或是空间上的冗余信息。接着,编码器并不会直接对残余信号进行编码,而是先将残余信号经过变换(通常为离散余弦变换)然后量化以进一步去除空间上和感知上的冗余信息。量化后得到的量化系数会再透过熵编码,去除统计上的冗余信息。在解码端,透过类似的相反操作,可以得到重建的视频数据。 对于编解码器,有硬件以及软件类型,硬件一般基于显卡或者FPGA设备,性能较高,能耗低,软件编解码器一般是指通过CPU进行视频编解码。 I帧、B帧、P帧 详细压缩原理在前面小节分析过了。 I帧:帧内编码图像帧(关键帧),帧内压缩。不依赖其它帧就可以解码还原出完整一帧图像。 P帧:预测编码图像帧,帧间压缩。依赖前面的I帧或P帧进行解码 B帧:双向预测编码图像帧,帧间压缩。提供最高的压缩比,它既需要之前的图像帧(I帧或P帧),也需要后来的图像帧(P帧),采用运动预测的方式进行帧间双向预测编码。 Note:对于实时视频(如摄像头),一般不产生B帧,因为用B帧,意味着会导致一定的帧延时 关键帧 VS 参考帧 GOP(Group of picture) GOP指画面组,一个GOP就是一组连续的画面。I帧表示一个GOP的开始。GOP大小指两个I帧之间的距离(两I帧之间的帧数量)。例如如下帧序列: IBBPBBPBBPBBI GOP大小为12。在视频直播中,为了秒开,GOP大小不宜设置过大。 DTS、PTS DTS:Decoder Timestamp,用来表示图像的解码时间 PTS:Presentation Timestamp,用来表示图像的显示时间 引入这两变量主要是因为,在存在双向参考帧(B帧)时,图像在编码图像的顺序和编码输出的顺序不同,而对于audio 来说,audio没有双向的预测, DTS 和 PTS 可以看成是一个顺序的,因此可一直采用一个,即可只采用 PTS。 如下是一个含有B帧的码流,在解码器端,对于前面4帧来说,得先解码B帧参考的I帧以及P帧,才能解码后续的B帧,所以解码顺序为IPBB,但是实际显示顺序为IBBP,所以DTS与PTS就不一样。 视频编码格式 目前主要有如下几种视频编码格式: H264/AVC。迄今为止业界最为成功的音视频编解码标准。 H265/HEVC。H.264官方的继任者。进一步的工业化目前受到了专利授权费用的显著影响,未来仍不明朗。 VP9。HEVC的一个不可忽视的竞争对手。人气不够高,Google在使用。性能没有受到业界的广泛认可。 AV1(AOMedia Video 1)。针对HEVC的专利问题,Google为首的多家公司成立了AOM(Alliance of Open Media,http://aomedia.org/)组织,专门研发的替代HEVC的免费开放视频编解码标准。 下图是视频编解码器发展历史。 视频容器 也叫封装格式,把已经编码好的视频、音频裸流按照一定的规范放到一起。里面可能还有元信息(metadata)、字幕、脚本之类。 常见容器格式有:MP4,AVI,FLV,MKV。如下是一个MP4容器文件包含的内容: 参考 [1] YUV.https://en.wikipedia.org/wiki/YUV. [2] 视频.https://baike.baidu.com/item/%E8%A7%86%E9%A2%91/321962?fr=aladdin. 本文已收录到大话WebRTC专栏,更多精彩请访问《大话WebRTC》。

整理归纳写过的WebRTC系列研究文章。本系列文章专注WebRTC底层技术研究。 版权声明:本系列文章全部原创。欢迎指正文章中的错误。 基础入门 音视频开发入门:音频基础 音视频开发入门:视频基础 WebRTC音视频传输基础:NAT穿透 基础概念 WebRTC研究:MediaStream概念以及定义 Webrtc Glossary:查阅各种WebRTC相关概念 开始放弃。。。 编译 Windows平台WebRTC编译(持续更新) Windows平台WebRTC编译-VS2017 Linux平台WebRTC编译 WebRTC安卓编译 Mac平台WebRTC编译 网络参数 WebRTC研究:统计参数之丢包率 WebRTC研究:统计参数之抖动 WebRTC研究:统计参数之往返时延 WebRTC研究:码率计算 RTP/RTCP WebRTC研究:Transport-cc之RTP及RTCP(TransportFeedback) WebRTC研究:关键帧请求(PLI以及FIR) WebRTC研究:FEC之RED封装 WebRTC研究:RTP报头扩展 WebRTC研究:RTP时间戳的产生 WebRTC研究:Audio level WebRTC研究:H264 RTP包解析 WebRTC研究:H264 RTP包封装 WebRTC研究:RTP包组帧 QoS/QoE优化 WebRTC研究:RTP中的序列号以及时间戳比较 WebRTC研究:丢包判断 WebRTC研究:丢包重传机制-NACK WebRTC研究:视频FEC编码 WebRTC研究:视频FEC解码 WebRTC研究:NACK与FEC机制的配合 WebRTC研究:流畅模式与清晰模式 WebRTC研究:基于卡尔曼滤波的抖动估计 WebRTC研究:音频带内FEC WebRTC研究:基于Transport Feedback的早期丢包检测 浅谈基于SFU实现一对一效果 拥塞控制 WebRTC研究:包组时间差计算-InterArrival WebRTC研究:Trendline滤波器-TrendlineEstimator WebRTC研究:码率控制器-AimdRateControl WebRTC研究:应用受限区域探测器-AlrDetector WebRTC研究:DelayBasedBwe中绝对发送时间转换 WebRTC研究:带宽估计中的稳定估计值 WebRTC研究:Pacing机制 音视频引擎 WebRTC研究:Simulcast层数变化 WebRTC研究:Encoded Transform 基础库 WebRTC研究:线程模型 常见开源SFU源码分析 Licode研究:Pipeline架构 茶余饭后闲谈 WebRTC研究:WebRTC M89关键更新 WebRTC研究:记一次音频带宽估计引入的异常分析 小技巧 Chrome查看WebRTC日志 常用RFC RFC3550.RTP:A Transport Protocol for Real-Time Applications RFC2198.RTP Payload for Redundant Audio Data RFC5109.RTP Payload Format for Generic Forward Error Correction RFC5104.Codec Control Messages in the RTP Audio-Visual Profile with Feedback (AVPF) RFC5285.A General Mechanism for RTP Header Extensions RFC8285.A General Mechanism for RTP Header Extensions RFC3984.RTP Payload Format for H.264 Video A Google Congestion Control Algorithm for Real-Time Communication draft-ietf-rmcat-gcc-02 RFC4585.Extended RTP Profile for Real-time Transport Control Protocol (RTCP)-Based Feedback (RTP/AVPF) Transport CC.RTP Extensions for Transport-wide Congestion Control draft-holmer-rmcat-transport-wide-cc-extensions-01
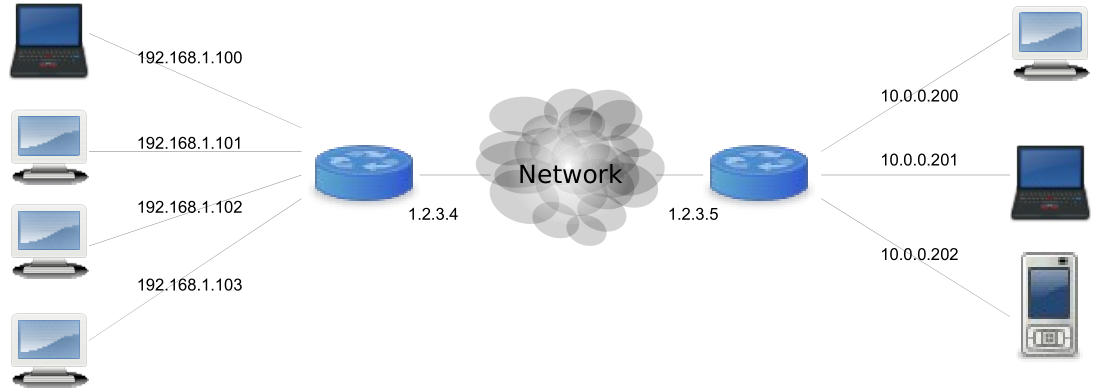
如今越来越多的音视频应用场景采用WebRTC技术,例如视频会议,在线教育,云游戏等。WebRTC包含一套强大的点对点(P2P)通信技术方案,用于音视频传输,本文我们来了解下背后的NAT穿透技术。 什么是NAT NAT(Network Address Translation)指的是网络地址转换,常部署在一个组织的网络出口位置。网络分为私网和公网两个部分,NAT网关设置在私网到公网的路由出口位置,私网与公网间的双向数据必须都要经过NAT网关。位于NAT后的是私网IP地址,分配给NAT的是公网IP地址。NAT通过将私网IP地址映射为公网IP地址,实现私网设备访问外部互联网的能力。组织内部的大量设备,通过NAT就可以共享一个公网IP地址,解决了IPv4地址不足的问题。同时NAT也起到隐藏内部设备,安全防护的作用。 如下图所示,有两个组织,每个组织的NAT分配一个公网IP,分别是1.2.3.4以及1.2.3.5。每个组织私网设备通过NAT将内网地址转换为公网地址,然后加入互联网。通过NAT每个私网设备就不必都需要分配公网IP了,就像图中,一个组织配一个公网IP即可。 NAT问题 虽然NAT解决了IPv4地址耗尽的问题,但是也存在一些问题。首先我们先说下不存在NAT时设备间点对点(P2P)通信情况: 1)位于同一个私网内,可以直接通过内网IP地址通信(例如192.168开头IP地址); 2)通信双方都有独立的公网IP地址,可以直接通过公网IP地址通信。 但是NAT的存在就不能这样处理了,增加了点对点通信的复杂度。如下图所示: 左边私网地址为192.168.1.100的设备要跟右边组织内的设备进行通信,由于右边组织多台设备共享一个公网IP,所以不能直接通过公网IP地址端口号进行通信,数据发过去了,根本不知道送到哪台设备,这样两个组织内的设备就不具有点对点通信的能力。既然这样,数据要怎么穿过NAT到达私网内,NAT网关要如何转发数据到指定设备呢? NAT穿透技术 现实生活中,大多数设备都位于NAT后。比如连着同一个基站的移动设备,同一个小区的宽带用户等。NAT的存在使得设备间不能直接进行点对点通信。有时候为了流量节省,以及安全等原因考虑,我们希望不同NAT后的设备也能进行点对点通信,不需要经过第三方的数据转发。为了进行设备间的点对点通信,我们需要使用相关技术检测设备间是否有点对点通信的可能性,以及如何进行点对点通信。这些相关技术就是NAT穿透(NAT traversal)。NAT穿透是为了解决使用了NAT后的私有网络中设备之间建立连接的问题。目前常见的NAT穿越技术、方法主要有: 应用层网关; 中间件技术; 打洞技术(Hole Punching); Relay(服务器中转)技术。 没有一种完美的NAT穿透,常常是多种技术互相配合,最常见的一种方案是打洞配合中转,例如后面说到的ICE方案。 NAT打洞技术 工作在传输层,最为常见。下面说下基本原理。 NAT网关维护着一张关联表,进行公网/私网地址端口的转换,结构如下所示: 私网IP 公网IP 192.168.1.100:5566 1.2.3.4:9200 192.168.1.101:80 1.2.3.4:9201 192.168.1.102:4465 1.2.3.4:9202 如下图,左边组织的公网IP为1.2.3.4NAT网关收到发到1.2.3.4:1234的数据,假如关联表中还未存在映射关系,NAT对外部发来的数据包直接丢掉。 所以网络访问只能先由私网侧发起,公网无法主动访问私网主机,既然这样,就由私网侧主动点。如下图: 私网地址10.0.0.100的设备发送数据包到公网。NAT网关关联表中创建了该设备私网地址:端口到公网地址:端口的映射,即上图中的10.0.0.100:1234到1.2.3.4:1234。这相当于在NAT上打了一个洞,其它人就可以通过这个“洞”把数据传进来,这就是为什么叫打洞技术了。 接下来,通过某种方式将打好的洞信息:NAT映射后的公网地址:端口告诉要通信那方,要通信那方就向该洞:1.2.3.4:1234发数据。NAT收到发到1.2.3.4:1234的数据,NAT网关在关联表中找到映射,然后转发数据到对应私网设备(10.0.0.100:1234)。 这里我们总结下打洞技术: 1)首先位于NAT后的Peer1节点需要向外发送数据包,以便让NAT建立起私网Endpoint1(IP1:PORT1)和公网Endpoint2(IP2:PORT2)的映射关系; 2)然后通过某种方式将映射后的公网Endpoint2通知给对端节点Peer2; 3)最后Peer2往收到的公网Endpoint2发送数据包,然后该数据包就会被NAT转发给私网的Peer1。 Relay(服务器中转)技术 在有些情况下,打洞会失败(下节介绍),此时只能通过部署在公网的第三方服务器进行数据转发,间接实现通信。 NAT类型 由于存在不同的NAT部署方式,所以产生了不同类型的NAT。 完全圆锥型NAT(Full cone NAT),即一对一(one-to-one)NAT。 一旦一个内部地址(iAddr:port)映射到外部地址(eAddr:port),所有发自iAddr:port的包都经由eAddr:port向外发送。任意外部主机都能通过给eAddr:port发包到达iAddr:port(注:port不需要一样) 受限圆锥型NAT(Address-Restricted cone NAT) 内部客户端必须首先发送数据包到对方(IP=X.X.X.X),然后才能接收来自X.X.X.X的数据包。在限制方面,唯一的要求是数据包是来自X.X.X.X。 内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。外部主机(hostAddr:any)能通过给eAddr:port2发包到达iAddr:port1。(注:any指外部主机源端口不受限制,但是目的端口必须是port2。只有外部主机数据包的目的IP 为 内部客户端的所映射的外部ip,且目的端口为port2时数据包才被放行。) 端口受限圆锥型NAT(Port-Restricted cone NAT)。类似受限制锥形NAT(Restricted cone NAT),但是还有端口限制。 一旦一个内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。 在受限圆锥型NAT基础上增加了外部主机源端口必须是固定的。 对称NAT(Symmetric NAT) 每一个来自相同内部IP与端口,到一个特定目的地地址和端口的请求,都映射到一个独特的外部IP地址和端口。 同一内部IP与端口发到不同的目的地和端口的信息包,都使用不同的映射 只有曾经收到过内部主机数据的外部主机,才能够把数据包发回 如果NAT是完全圆锥型的,那么双方中的任何一方都可以发起通信。如果NAT是受限圆锥型或端口受限圆锥型,双方必须一起开始传输。若有一方位于对称NAT后,就无法打洞成功。由前面说明可知,对于对称NAT来说,客户端向STUN服务器(下节介绍,用于协助打洞)发包映射的公网IP:端口与向其它客户端发包映射的公网IP:端口是不一样的,一个连接创建一个公网的映射,也就是说其它客户端无法使用之前通过STUN服务器打好的洞,所以客户端双方无法成功打洞,只能使用中转方案。 ICE STUN STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序),是基于UDP的完整的穿透NAT的解决方案,属于我们前面说到的打洞技术。它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的NAT之后以及NAT为某一个本地端口所绑定的公网端端口。这些信息被用来在两个同时处于NAT路由器之后的主机之间创建UDP通信。STUN是一种Client/Server的协议,也是一种Request/Response的协议,默认端口号是3478。 下面我们通过Wireshark抓包看下是如何Request/Response的。 如下图所示,首先客户端向地址为216.93.246.18的STUN服务器发送Binding Request。 服务器回了Binding Response: 接着我们向地址为216.93.246.15的STUN服务器执行同样操作: 我们看到Binding Response包MAPPED-ADDRESS属性里包含了客户端映射到公网的IP地址以及端口。上图可知两个STUN服务器返回的客户端映射到公网的端口不一样,说明客户端现在位于对称型NAT后,无法进行打洞。 四种主要NAT类型中有三种是可以使用STUN进行穿透:完全圆锥型NAT、受限圆锥型NAT和端口受限圆锥型NAT,对称型NAT则不能使用,原因前面也说到了。 TURN TURN(Traversal Using Relay NAT,通过Relay方式穿越NAT),是一种数据传输协议。允许通过TCP或UDP方式穿透NAT或防火墙。TURN是一个Client/Server协议。TURN的NAT穿透方法与STUN类似,都是通过取得应用层中的公网地址达到NAT穿透。但实现TURN client的终端必须在通讯开始前与TURN server进行交互,并要求TURN server产生"relay port",也就是relayed-transport-address。这时TURN server会建立peer,即远端端点(remote endpoints),开始进行中继(relay)的动作,TURN client利用relay port将数据传送至peer,再由peer转传到另一方的TURN client。 TURN主要用在使用STUN无法穿透的场景下,例如前面说到的对称型NAT,只能通过TURN server进行数据中转。 ICE ICE(Interactive Connectivity Establishment,互动式连接建立)。ICE定义了穿越方法而不是协议。ICE整合了STUN与TURN。ICE使得两个NAT后的端点通信更加便捷。ICE使用STUN进行打洞,若失败,则使用TURN进行中转。 下面我们举个应用场景,说下ICE的大概流程。 场景 如下图的应用场景,用户Alice要与Bob进行通信,这两个用户都位于NAT后,公网部署了STUN与TURN服务器。 收集候选地址(candidate) 首先客户端要收集candidate。candidate表示候选地址,由IP地址与端口组成。收集的candidate要与对方的candidate组成candidate pair,进行连通性检查。candidate主要有三种: Host candidate(host):从本地网卡上获取的地址 Server reflexive candidate(srflx):STUN server 观察的该客户端的地址 Relay reflexive candidate(relay):TURN server 为该客户端分配的中继地址 客户端通过向STUN服务器发送STUN数据包,STUN服务器做出回应,告知其在数据包中监测到的IP地址以及端口。 下图中,Alice与Bob通过STUN以及TURN服务器收集了三种类型的candidate。 连通性检查 收集candidate后把通过信令offer与answer方式双方交换candidate,进行candidate两两配对,然后ICE连通性检查。这个连通性检查按一定规则的。 本地的candidate与远端candidate构成的每一对都有一定的优先级,按优先级排序进行连通性检查。 数据传输 最后从有效的candidate组合中选择优先级最高的作为传输地址,用于数据传输。 Trickle ICE 在WebRTC中使用ICE框架进行P2P通信。前面说到ICE中第一步是收集candidate,需要遍历STUN以及TURN服务器,这一步需要耗费很多时间,导致双方建立通信时间很慢。为了解决这一问题,WebRTC引入了Trickle ICE,这样candidate收集以及连通性检查可以同时进行,加快双方建立通信的速度。 libnice库 若要让我们的程序支持ICE,我们可以借助第三方库。常见的支持ICE的库有Libjingle,Libnice。Libjingle集成在WebRTC里,不方便独立使用,这里我们推荐使用Libnice,常见的WebRTC服务器,例如janus,licode都是使用libnice进行P2P通信,具体可访问Libnice官网了解。 总结 本文主要介绍了NAT穿透技术,几种NAT类型,最后介绍了NAT穿透最常用的方案:ICE。通过本文,希望大家对音视频P2P传输中的NAT穿透有一定了解。 参考 [1] P2P技术详解(一):NAT详解——详细原理、P2P简介.http://www.52im.net/forum.php?mod=viewthread&tid=50&highlight=p2p. [2] 网络地址转换.https://zh.wikipedia.org/zh-hans/网络地址转换. [3] Trickle ICE.https://tools.ietf.org/html/draft-ietf-ice-trickle-21.
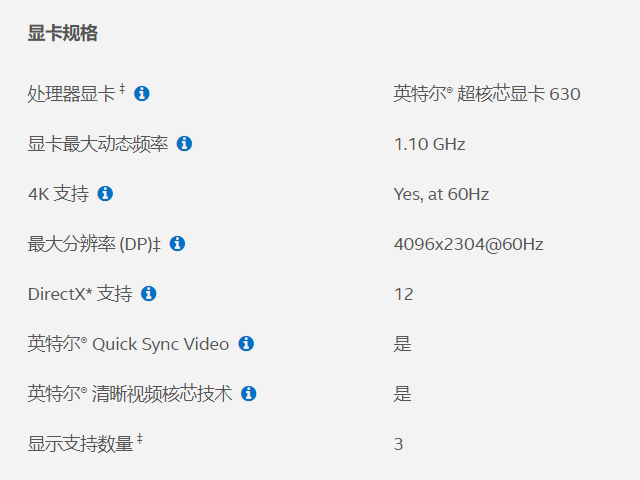
视频编解码分为硬件加速以及非硬件加速。硬件加速是指通过显卡,FPGA等硬件进行视频编解码,由于硬件有专门优化,所以性能高,能耗低,非硬件加速编解码是指通过CPU进行视频编解码,性能就没那么高(虽然有相关CPU指令优化),由于视频编解码计算量很大,所以能耗也很高。在PC平台上主流的硬件加速编解码有Intel集成显卡,Nvidia显卡。Nvidia平台的编解码用的比较多,网上资料也多,接口也很简单,但是相对成本会高些。Intel集显平台视频编解码成本就低很多了,只要是最近几年带集显的CPU基本都支持硬件加速编解码,但是开发复杂度相对高些,网上资料也少,主要是用的人少吧。自己做过Intel集显平台在Linux以及Windows下的编解码开发,也踩过很多坑,故特地写此文章,介绍下Intel集显平台的视频编解码开发,希望更多的人能加入Intel平台视频编解码,降低成本开销。 Quick Sync Video Intel Quick Sync Video(QSV)是Intel GPU上跟视频处理有关的一系列硬件特性的称呼。如下是Intel官网某款CPU带的显卡规格: 可以看到该显卡支持Intel Quick Sync Video。点击Quick Sync Video旁的Info提示: 英特尔® Quick Sync Video 技术可以快速转换便携式多媒体播放器的视频,还能提供在线共享、视频编辑及视频制作功能。 所以看到CPU带的集成显卡支持Quick Sync Video就表示支持硬件加速的视频编解码。 硬件支持 看下Intel不同代处理器对视频编码格式的支持情况。 Platform Name Graphics Adds support for... Ironlake gen5 MPEG-2, H.264 decode. Sandy Bridge gen6 VC-1 decode; H.264 encode. Ivy Bridge gen7 JPEG decode; MPEG-2 encode. Bay Trail gen7 - Haswell gen7.5 - Broadwell gen8 VP8 decode. Braswell gen8 H.265 decode; JPEG, VP8 encode. Skylake gen9 H.265 encode. Apollo Lake gen9 VP9, H.265 Main10 decode. Kaby Lake gen9.5 VP9 profile 2 decode; VP9, H.265 Main10 encode. Coffee Lake gen9.5 - Gemini Lake gen9.5 - Cannonlake gen10 - 可以看到从第五代开始就支持硬件加速视频编解码了,越往后支持的视频编码格式以及特性也逐渐增多。 API支持 在不同平台上可通过不同API使用Intel GPU的硬件加速能力。目前主要由两套API:VAAPI以及libmfx。 VAAPI (视频加速API,Video Acceleration API)包含一套开源的库(LibVA) 以及API规范, 用于硬件加速下的视频编解码以及处理,只有Linux上的驱动提供支持。 libmfx。Intel Media SDK中的API规范,支持视频编解码以及媒体处理。支持Windows以及Linux。 除了Intel自己的API,在Windows系统上还有其他API可使用Intel GPU的硬件加速能力,这些API属于Windows标准,由Intel显卡驱动实现。 DXVA2 / D3D11VA。标准Windows API,支持通过Intel显卡驱动进行视频编解码,FFmpeg有对应实现。 Media Foundation。标准Windows API,支持通过Intel显卡驱动进行视频编解码,FFmpeg不支持该API。 Intel媒体栈 基于Intel显卡技术,Intel媒体栈提供了一系列多媒体解决方案。例如:Intel Media driver(也称作iHD driver),Intel Media SDK, LibVA等。 下图为Intel媒体栈的各个组件示意图: 后面说下跟我们视频编解码关系比较大的。 VAAPI驱动 VAAPI驱动属于用户态驱动,用于支持LibVA,底层是i965/1915驱动。Intel提供了两种开源的VAAPI驱动:intel-vaapi-driver以及intel-media-driver,intel-media-driver较intel-vaapi-driver新,维护更积极,所以目前更推荐使用intel-media-driver。 开发库以及SDK LibVA:VAAPI的开源库实现 LibVA-utils:VAAPI相关的一系列工具以及示例 Intel Media SDK:提供一套用于视频编解码以及处理(VPP)的API:libmfx,支持Linux/Windows,具体介绍可查看:Intel Media SDK 开发环境搭建 前面简单介绍了VAAPI以及Intel Media SDK,下面说下开发环境搭建。 Windows系统 只有Intel Media SDK支持。确保安装了集成显卡驱动,然后需要到Intel官网下载Intel Media SDK安装包。具体搭建请参考: Intel Media SDK环境搭建:https://blog.csdn.net/y601500359/article/details/87169715 Linux系统 包含Ubuntu以及CentOS。需要安装驱动以及相应的库。 FFmpeg VAAPI/QSV开发环境搭建 对于VAAPI以及Intel Media SDK,如果使用原生API开发的话比较麻烦,好在FFmpeg提供了对应的插件。我们可以通过FFmpeg间接使用这两套API。在FFmpeg中VAAPI还是叫做VAAPI,但是Intel Media SDK却叫做QSV(一脸懵逼)。 FFmpeg-vaapi插件:基于VAAPI接口 FFmpeg-qsv插件:基于Intel Media SDK FFmpeg VAAPI/QSV开发环境搭建我就不做搬运工了,大家可参考官网教程。 Linux FFmpeg VAAPI/QSV Installation Environment:https://01.org/linuxmedia/quickstart/ffmpeg-vaapi-qsv-installation-environment 不使用FFmpeg的开发环境搭建 有些人可能不想使用FFmpeg,对于Intel Media SDK还好,但是VAAPI就不行了,接口设计很底层,且复杂,所以对于想使用VAAPI的话,还是老老实实使用FFmpeg吧,时间就是金钱。 对于Intel Media SDK,除了可以编解码,还有可以进行视频的其他操作。2017年开始,Linux上才有开源的Intel Media SDK实现,之前Linux上的对应方案叫做Intel® Media Server Studio,现在已经不可用了。 Linux上的Intel Media SDK底层基于Libva。编译Intel Media SDK也是要安装VAAPI驱动等Intel媒体栈软件。 所以开发环境搭建还是参考上一小节的内容,只是可以选择不编译安装FFmpeg。 注意事项 安装的LibVA-utils包含一个vainfo工具,前面的开发环境搭建后,可以通过vainfo检查VAAPI的安装设置。 [crayon-69e8f2c7d49fd465310026/] 正常的输出类似上面,我们用到的是Intel iHD driver(即Intel Media driver),这个在设置: #export LIBVA_DRIVER_NAME=iHD时指定,设置iHD驱动在一些情况下能获得更高的编解码性能。VAEntrypointVLD 指的是显卡能够解码这个格式,VAEntrypointEncSlice 指的是显卡可以编码这个格式。 如果运行vainfo出现如下错误: [crayon-69e8f2c7d4a0d421985753/] 说明驱动没设置正确,确保驱动都正常编译到指定目录,且驱动名称及路径: [crayon-69e8f2c7d4a13378402279/] 设置正确。 示例代码 Intel Media SDK:https://github.com/Intel-Media-SDK/MediaSDK/tree/master/samples ffmpeg-VAAPI:FFmpeg源码目录doc\examples下的vaapi_encode.cpp与vaapi_transcode.c 1)示例代码中,avcodec_find_encoder_by_name输入参数得是FFmpeg注册的vaapi编码器名称,例如 h264的vaapi编码器是:h264_vaapi,可通过ffmpeg -codecs | grep vaapi命令查询; 2)av_hwdevice_ctx_create输入的设备名是/dev/dri/renderD128这样的形式,可通过ls /dev/dri查询,这里的示例/dev/dri/renderD128表示Intel集显设备; 3)VAAPI编码时,输入的YUV格式必须是NV12,其他格式YUV得转为NV12格式。vaapi_encode.c有个AVFrame(sw_frame),用于存放我们输入的YUV数据,该AVFrame的data[0]用于存放Y数据,data[1]存放UV数据,由于输入格式是NV12,所以data[1]中UV数据的内存布局为:UVUVUVUV···UVUV。 FFmpeg-QSV:FFmpeg源码目录doc\examples下的qsvdec.c 参考 [1] Linux FFmpeg VAAPI/QSV Installation Environment.https://01.org/zh/linuxmedia/quickstart/ffmpeg-vaapi-qsv-installation-environment?langredirect=1. [2] Intel media for linux.https://01.org/zh/intel-media-for-linux?langredirect=1. [3]Linux media.https://01.org/zh/linuxmedia?langredirect=1.

什么是声音 介质振动在听觉系统中产生的反应。是一种波。因为是一种波,所以我们可以用频率、振幅等描述。 图1.蚊子翅膀振动产生声音传到人耳 频率与振幅 有两个基本的物理属性:频率与振幅。声音的振幅就是音量,也叫作响度,频率是单位时间振动次数,频率的高低就是指音调,频率用赫兹(Hz)作单位。 图2.声音波形 人耳只能听到20Hz到20kHz范围的声音。小于20HZ的叫次声波,大于20kHz的叫做超声波。超声波在现实中有很多应用,例如洗牙,测距,成像等。 图3.声音按频率分类 分贝 因为人耳的特性,我们对声音的大小感知呈对数关系。所以我们通常用分贝描述声音大小,分贝(decibel)是量度两个相同单位之数量比例的单位,主要用于度量声音强度,常用dB表示。声学中,声音的强度定义为声压。计算分贝值时采用20微帕斯卡为参考值(通常被认为是人类的最少听觉响应值,大约是3米以外飞行的蚊子声音)。这一参考值是人类对声音能够感知的阈值下限。声压是场量,因此使用声压计算分贝时使用如下公式: 图4.分贝计算(Pref是标准参考声压值20微帕) 由上述公式可知,当声音强度等于Pref时,db=0,也就是说0分贝时声音最小。 模拟音频与数字音频 模拟音频(Analogous Audio),用连续的电流或电压表示的音频信号,在时间和振幅上是连续。在过去记录声音记录的都是模拟音频,比如机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式。 数字音频(Digital Audio),通过采样和量化技术获得的离散性(数字化)音频数据。计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。 图5.典型的音频采集并转换成计算机处理的数字音频信号流程 采样频率 声音以模拟波形的形式存在。数字音频片段以足够快的速率对模拟波的振幅进行采样,模仿波的固有频率,达到高度接近这种模拟波的效果。 采样频率(Sampling Rate),单位时间内采集的样本数,是采样周期的倒数,指两个采样之间的时间间隔。采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号,这其实就是著名的香农采样定理。例如,要表示人类听觉范围 (20-20000 Hz) 内的音频,数字音频格式必须至少每秒采样 40000 次(CD 音频使用 44100 Hz 的采样率,部分原因也在于此)。 图6.采样频率 CD音质采样率为 44.1 kHz,其他常用采样率:22.05KHz,11.025KHz,一般网络和移动通信的音频采样率:8KHz。采样频率越高,声音质量越好。一般我们语音通信中(VOIP,例如微信,QQ语音聊天),我们对声音质量要求没那么高,能听清讲的什么即可,所以常采用8KHz采样率。 图7.CD以及VOIP采样频率对比 量化 量化(Quantization )是将经过采样得到的离散数据转换成二进制数的过程。量化的过程是先将整个幅度划分成有限个小幅度(量化阶距)的集合,把落入某个阶距内的样值归为一类,并赋予相同的量化值。 量化深度,表示一个样本的二进制的位数,即每个采样点用多少比特表示,在计算机中音频的量化深度一般为4、8、16、32位(bit)等。例如:量化深度为8bit时,每个采样点可以表示256个不同的量化值,而量化深度为16bit时,每个采样点可以表示65536个不同的量化值。量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多,位数越少,声音的质量越低,需要的存储空间越少。CD音质采用的是16 bits,移动通信 8bits。 图8.量化信号 存储大小 声道数。记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。使用双声道记录声音,能够在一定程度上再现声音的方位,反映人耳的听觉特性。 数字音频存储大小。采样频率、量化深度数越高,声音质量也越高,保存这段声音所用的空间也就越大。立体声(双声道)存储大小是单声道文件的两倍。即: 文件大小(B)=采样频率(Hz)×录音时间(S)×(量化深度/8)×声道数(单声道为1,双声道为2) 如:录制1分钟采样频率为44.1KHz,量化深度为16位,立体声的声音(CD音质),文件大小为: 44.1×1000×60×(16/8)×2=10584000B≈10.09M 可以看到数字音频信号如果不加压缩地直接进行传送或者存储,将会占用极大的带宽以及磁盘空间,这也是后面讲到的音频要进行压缩的原因。 声音编码压缩 压缩基础 音频数据通常会进行压缩,以便更易于存储和传输。通过采样以及量化得到的数字音频信号中存在着大量冗余。数字音频压缩编码保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩。数字音频压缩编码采取去除声音信号中冗余成分的方法来实现。所谓冗余成分指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为20Hz~20KHz,范围外的其它频率人耳无法察觉,都可视为冗余信号。此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应。 有损压缩与无损压缩 无损压缩。无损压缩虽然缩小音频的储存大小,但可以保留原始文件的所有信息。无损压缩是一个可逆的过程,利用信息冗余进行数据压缩,类似我们平时用的rar,zip等文件压缩。常见无损压缩格式有:APE,FLAC等。 有损压缩。有损压缩是一个不可逆的过程。有损数据压缩利用人类听觉特性,将不重要的声音信息舍弃,虽然有损压缩在理论上对原始文件造成损失,但这种损失不一定能被人耳分辨出来。常见有损压缩格式有:MP3,AAC,OGG等。

最近群里有人问:NV12格式,怎么对应AVFrame中的data[0],data[1],data[2]。其实ffmpeg视频编码,YUV与AVFrame对应关系很简单。 在视频编码时,我们需要把YUV数据拷贝到AVFrame.data中,视频编码有硬件加速以及非硬件加速两种,所以对应关系也有两种。 硬件加速编码 指通过显卡进行硬件加速编码,例如指定vaapi进行编码。使用硬件加速编码时,YUV输入格式一般都是NV12,我做过的Intel以及Nvidia编码都是这样。之所以使用NV12格式,在Intel开发文档有这样说明: [crayon-69e8f2c7d65c1351127786/] 因为ffmpeg底层也是调用相关显卡SDK做硬件加速编码,所以我们把YUV数据拷贝给AVFrame时,也得按NV12格式。对于NV12格式,Y数据在最前,接着是UV交错排布,类似这样:YYYYYYYY UVUV,所以对于AVFrame,我们得把Y数据拷贝data[0],UV数据拷贝给data[1]。 [crayon-69e8f2c7d65ca320299161/] 非硬件加速编码 指通过CPU进行编码,例如指定libx264,libx265进行编码。对应关系就比较简单了,YUV三个分量数据依次对应data[0],data[1],data[2]。 [crayon-69e8f2c7d65ce029999779/]