数字图像
平时我们看到的视频其实是由一幅幅图像组成,所以先来了解下数字图像。
数字图像由一个个像素组成,是二维图像用有限数字数值像素的表示。如下路所示,我们放大一个图像后,能明显看到一个个像素块:

图像分辨率
水平分辨率指的一幅图像的宽,垂直分辨率指的一幅图像的高。一般说的分辨率用水平分辨率(宽)X 垂直分辨率(高)表示。
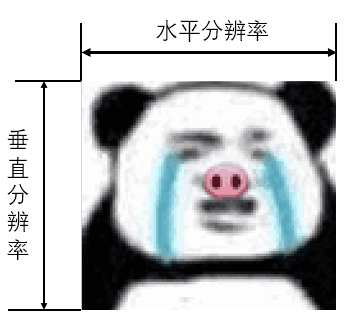
常见分辨率有:
- QVGA:320x240
- CIF:352×288
- VGA:640x480
- HD:1360x768
- FHD:1920x1080
- WQHD:2560x1440
- 4K UHD:3840x2160
数字图像编码方法
指的是图像中每一个像素点在计算机中用什么编码方法表示。
RGB
人的眼睛是根据所看见的光的波长来识别颜色的。可见光谱中的大部分颜色可以由三种基本色光按不同的比例混合而成,这三种基本色光的颜色就是红(Red)、绿(Green)、蓝(Blue)三原色光。这三种光以相同的比例混合、且达到一定的强度,就呈现白色(白光);若三种光的强度均为零,就是黑色(黑暗)。这就是加色法原理,加色法原理被广泛应用于电视机、监视器等主动发光的产品中。
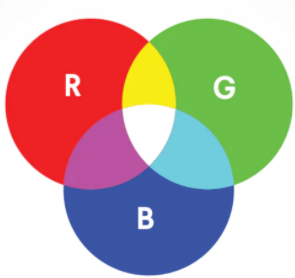
RGB存储表示
每个像素至少包含R、G、B分量,逐个像素存储。
RGB16:每像素占2字节,R、G、B分别用5bit,6 bit,5 bit表示。
RGB24:每像素占3字节,R、G、B各占一字节。
RGB32:每像素占4字节,A(Alpha)、R、G、B各占一字节。
YUV
"Y"表示明亮度(Luminance),"U"和"V"则是色度、浓度(Chrominance、Chroma)。之所以使用YUV编码方法,主要有这些原因:
- R、G、B三个分量的相关性很强,存在冗余,使用YUV后可进行数据压缩
- 人眼对亮度信号较敏感,对色度信号较不敏感,可通过较少UV分量进行数据压缩
- 彩色信号能很好兼容黑白电视,黑白视频只有Y分量
YUV、YCbCr
YUV解决彩色信号对黑白电视的兼容,黑白电视也能接收彩色电视信号。
- Y:亮度(黑白图像)
- UV:彩度
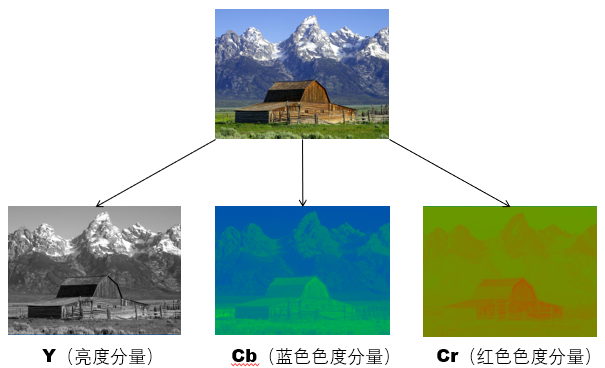
YUV针对模拟信号。YCbCr模型针对数字信号,是YUV压缩和偏移的版本。一般俗称的YUV大多是指YCbCr。如下是某YCbCr图像的三个分量组成,其中其中Y是指亮度分量,Cb指蓝色色度分量,而Cr指红色色度分量。
YUV与RGB的转换
YUV与RGB可以按公式进行互相转换,具体可参考文末的参考[1]。
YUV采样
- YUV 4:4:4采样,每一个Y对应一组UV分量。24 Bits per Pixel。
- YUV 4:2:2采样,每两个Y共用一组UV分量。16 Bits per Pixel。
- YUV 4:2:0采样,每四个Y共用一组UV分量。12 Bits per Pixel。
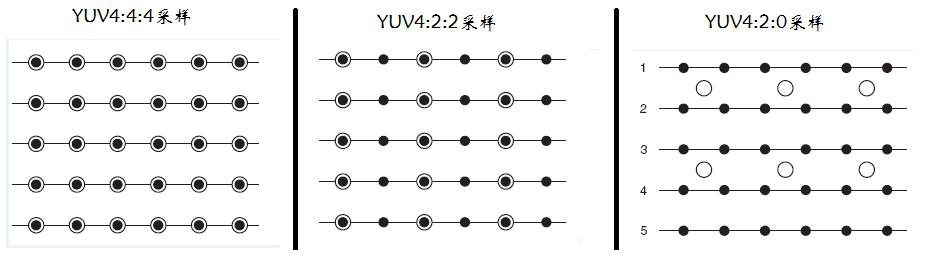
上图中黑点表示采样该像素点的Y分量,以空心圆圈表示采用该像素点的UV分量。
YUV 存储格式
YUV的存储格式有两大类:
- 紧缩格式(packed formats):将Y、U、V值存储成Macro Pixels数组,和RGB的存放方式类似。YUV4:4:4格式而言,用紧缩格式最合适。大概格式为:YUVYUVYUVYUV
- 平面格式(planar formats):将Y、U、V的三个分量分别存放在不同的矩阵中。大概格式为:YYYYUV。
YUV常见表示方法
根据采样方式和存储格式的不同,就有了多种 YUV 格式。这些格式主要是基于 YUV 4:2:2 和 YUV 4:2:0 采样。
常见的几乎都是基于YUV4:2:0:
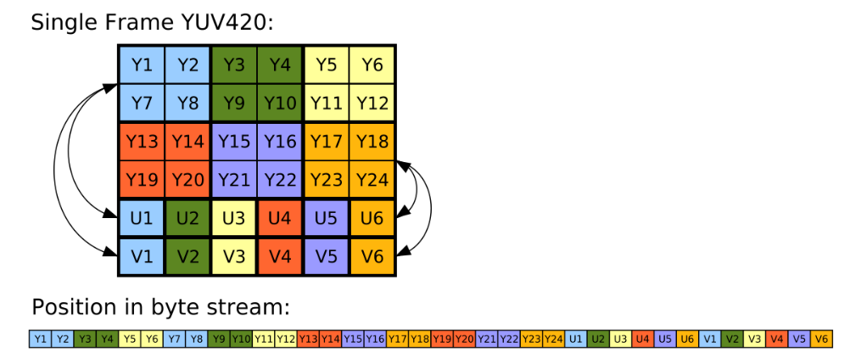
- YU12。先存储 Y 分量,再存储 U、V 分量。例如:YYYYYYYYUUVV。
- YV12 ,又称作 I420 格式。它的存储格式就是把 V 和 U 反过来了。例如:YYYYYYYYVVUU。
- NV12。先存储了Y分量,但接下来并不是再存储所有的U或者V分量,而是把UV分量交替连续存储。例如:YYYYYYYYUVUV。NV12在硬件编解码中用的比较多。
如下图所示,为YUV420的存储格式,每4个Y对应一组UV:
视频
连续的图像变化每秒超过24帧(frame)画面以上时,根据视觉暂留原理,人眼无法辨别单幅的静态画面,看上去是平滑连续的视觉效果,这样连续的画面叫做视频。视频里面的每一幅图像称为一帧。
视频图像扫描
包括显示器扫描和摄像机视频捕获扫描两个环节。分为逐行扫描和隔行扫描两种扫描方式。
隔行扫描(Interlace Scanning)
每帧分为两场:奇数行组成奇数场,偶数行组成偶数场。
在显示器扫描中,隔行扫描指在显示一幅图像时,先扫描奇数行,再扫描偶数行,因此每幅图像需扫描两次才能完成。

摄像机在进行视频捕获时,例如对于25帧视频,每秒钟扫描50场,每一场只有半幅图像,意味着我们看到的图像的每一帧都是由两个采集时间不同的“半幅”图像合并而成的。当我们观看隔行扫描的视频时,会出现行间闪烁、运动模糊、垂直边缘锯齿等现象,从而影响画面清晰度。一般比较早期的视频是隔行扫描采集的。如下是一个隔行扫描视频截图,可以看到人物运动时有明显的锯齿。
该视频链接如下,大家可以认真看下人物运动时的边缘:
https://music.163.com/#/mv?id=5309079
逐行扫描(Progressive Scanning)
每次扫描完所有行,从上到下逐行扫描。在显示器扫描中,逐行扫描指从上到下的扫描每一行图像。摄像机在进行视频捕获时,例如对于25帧视频,每秒钟扫描25场,每一场是完整一副图像。画面平滑干净、细节清晰、没有闪烁感、也不会产生运动模糊与锯齿现象。
1080P和1080i的区别
1080i:就是1920x1080分辨率。不过这种高清图像是隔行扫描(Interlace Scanning)的。每一个奇数行图像都在每一偶数行图像后面显示出来,当然图像就不会那么平滑。1080i适于表现纪录片和野生动物等题材,但是不是那么适合播放运动和电影类的内容。
1080p:也是1920x1080分辨率。和1080i的区别就在于1080p不是隔行扫描的,而是逐行扫描(Progressive Scanning)。每一线都同时表现在画面上,因此比隔行扫描更加得平滑。这是更高的高清标准。
视频时间戳(Timestamp)
每一帧的采样时间tn(相对)为时间戳。时间单位为采样频率或具体时间单位(如毫秒)。
RTP timestamp是用采样频率表示时间的。两帧之间RTP timestamp的增量 = 采样频率 / 帧率
例如:90kHz作为视频采样频率,视频帧率为25fps,相邻帧间RTP timestamp增量值 = 90000/25 = 3600。
视频帧率(Frame rate)
每秒播放的图像帧数量(Frames per Second,简:fps)。目前常见帧率:25fps、30fps、60fps、90fps、120fps。
视频码率(Bitrate)
单位时间传送的数据bit数,一般我们用的单位是kbps,也就是数据bit数除以1000(不是1024,发现很多人这个很容易搞错)。
码率越大,单位时间包含的数据越多,视频质量越好。目前有如下两种码率类型:
- 可变码率(Variable bitrate,简称VBR),指编码码率会随图像的复杂程度的不同而变化。
- 固定码率(Constant bitrate,简称CBR),指编码码率是固定的。
视频压缩的必要性
1920x1080@30fps视频的每秒数据量:
- RGB:
1920x1080x3x30 = 186624000B = 186M - YUV420:
1920x1080x1.5x30 = 93M
可以看到数据量非常大。所以为了存储以及网络带宽要求,需要对视频数据进行压缩。
视频压缩原理
利用了视频数据的冗余。例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。通过消除这些冗余信息实现视频数据的压缩。
- 时间上的冗余信息(temporal redundancy)。在视频数据中,相邻的帧(frame)与帧之间通常有很强的关连性,这样的关连性即为时间上的冗余信息。
- 空间上的冗余信息(spatial redundancy)。在同一张帧之中,相邻的像素之间通常有很强的关连性,这样的关连性即为空间上的冗余信息。
- 统计上的冗余信息(statistical redundancy)。统计上的冗余信息指的是欲编码的符号(symbol)的几率分布是不均匀(non-uniform)的。
- 视觉冗余。人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。
如下图为视频相邻帧间时间上的冗余信息,可以看到只有头部对应的像素发生了变化:
下图为利用空间上的冗余信息进行帧内压缩(后面提到的I帧压缩原理):
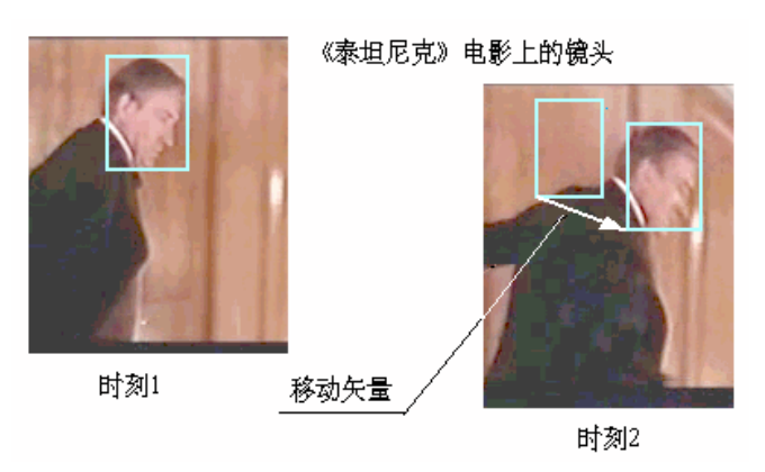
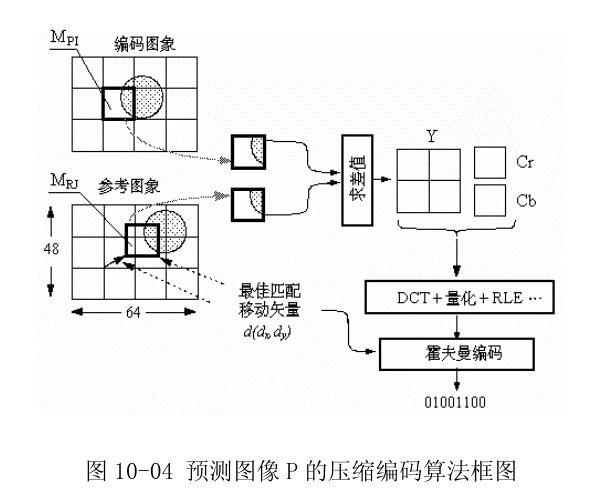
下图为利用时间上的冗余信息进行数据压缩(后面提到的P帧压缩原理),参考了前面的视频帧:
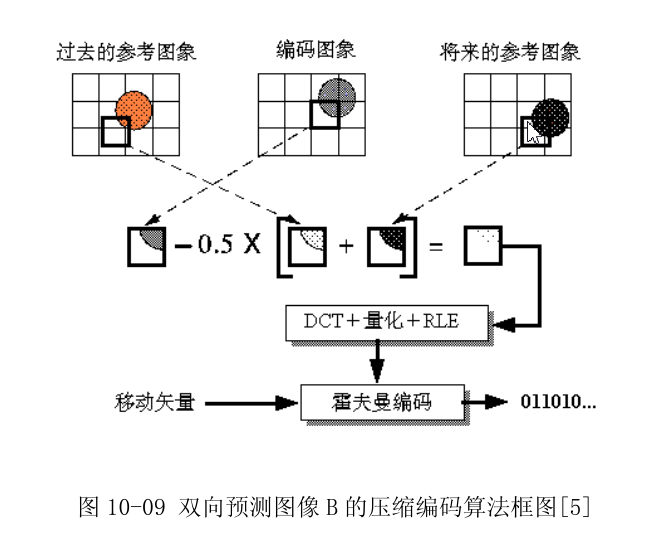
下图为利用时间上的冗余信息进行数据压缩(后面提到的B帧压缩原理),参考了前面以及后面的视频帧:
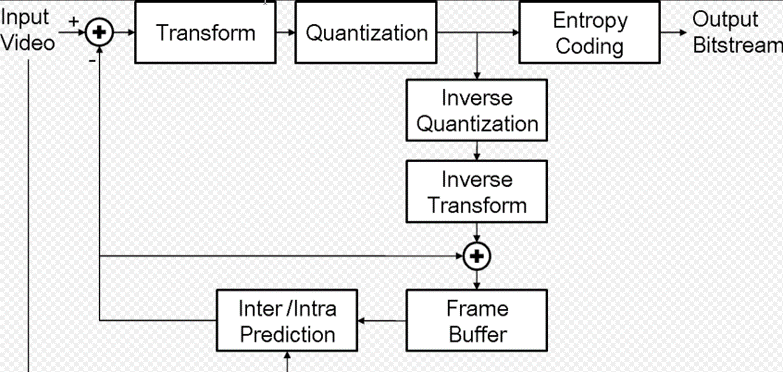
视频编解码器(Codec)
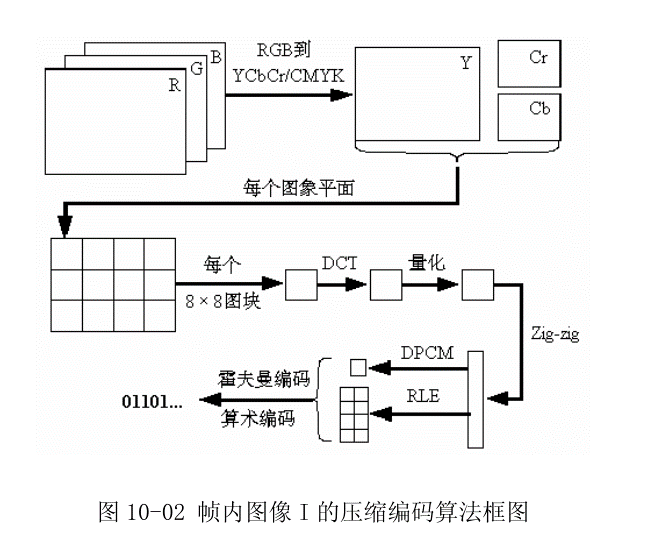
能够对数字视频进行压缩或者解压缩的程序或者设备。下图为一个典型的视频编码器。在进行当前信号编码时,编码器首先会产生对当前信号做预测的信号,称作预测信号(predicted signal),预测的方式可以是时间上的预测(inter prediction),亦即使用先前帧的信号做预测,或是空间上的预测(intra prediction),亦即使用同一张帧之中相邻像素的信号做预测。得到预测信号后,编码器会将当前信号与预测信号相减得到残余信号(residual signal),并只对残余信号进行编码,如此一来,可以去除一部分时间上或是空间上的冗余信息。接着,编码器并不会直接对残余信号进行编码,而是先将残余信号经过变换(通常为离散余弦变换)然后量化以进一步去除空间上和感知上的冗余信息。量化后得到的量化系数会再透过熵编码,去除统计上的冗余信息。在解码端,透过类似的相反操作,可以得到重建的视频数据。
对于编解码器,有硬件以及软件类型,硬件一般基于显卡或者FPGA设备,性能较高,能耗低,软件编解码器一般是指通过CPU进行视频编解码。
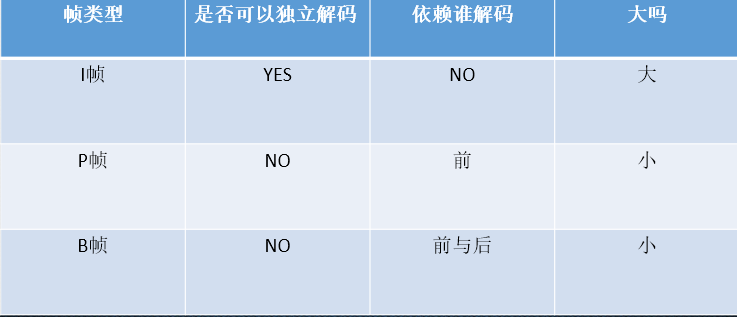
I帧、B帧、P帧
详细压缩原理在前面小节分析过了。
I帧:帧内编码图像帧(关键帧),帧内压缩。不依赖其它帧就可以解码还原出完整一帧图像。
P帧:预测编码图像帧,帧间压缩。依赖前面的I帧或P帧进行解码
B帧:双向预测编码图像帧,帧间压缩。提供最高的压缩比,它既需要之前的图像帧(I帧或P帧),也需要后来的图像帧(P帧),采用运动预测的方式进行帧间双向预测编码。
Note:对于实时视频(如摄像头),一般不产生B帧,因为用B帧,意味着会导致一定的帧延时
关键帧 VS 参考帧
GOP(Group of picture)
GOP指画面组,一个GOP就是一组连续的画面。I帧表示一个GOP的开始。GOP大小指两个I帧之间的距离(两I帧之间的帧数量)。例如如下帧序列:
IBBPBBPBBPBBI
GOP大小为12。在视频直播中,为了秒开,GOP大小不宜设置过大。
DTS、PTS
DTS:Decoder Timestamp,用来表示图像的解码时间
PTS:Presentation Timestamp,用来表示图像的显示时间
引入这两变量主要是因为,在存在双向参考帧(B帧)时,图像在编码图像的顺序和编码输出的顺序不同,而对于audio 来说,audio没有双向的预测, DTS 和 PTS 可以看成是一个顺序的,因此可一直采用一个,即可只采用 PTS。
如下是一个含有B帧的码流,在解码器端,对于前面4帧来说,得先解码B帧参考的I帧以及P帧,才能解码后续的B帧,所以解码顺序为IPBB,但是实际显示顺序为IBBP,所以DTS与PTS就不一样。

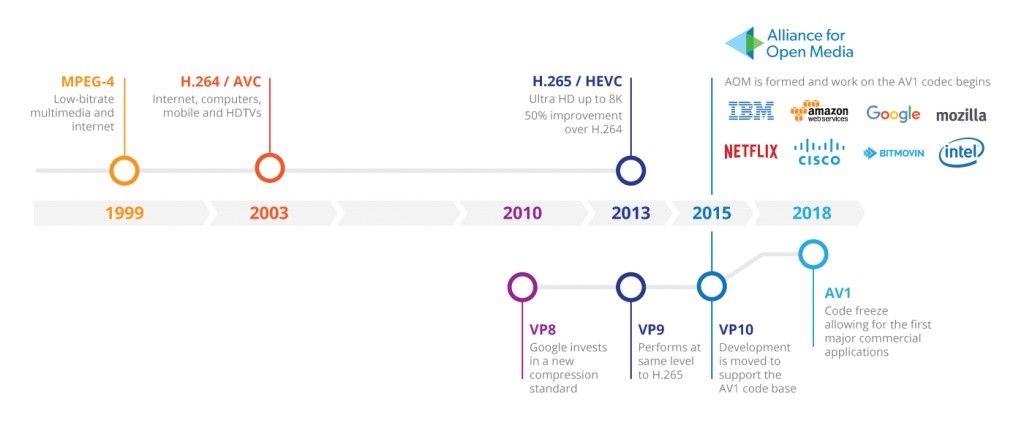
视频编码格式
目前主要有如下几种视频编码格式:
- H264/AVC。迄今为止业界最为成功的音视频编解码标准。
- H265/HEVC。H.264官方的继任者。进一步的工业化目前受到了专利授权费用的显著影响,未来仍不明朗。
- VP9。HEVC的一个不可忽视的竞争对手。人气不够高,Google在使用。性能没有受到业界的广泛认可。
- AV1(AOMedia Video 1)。针对HEVC的专利问题,Google为首的多家公司成立了AOM(Alliance of Open Media,http://aomedia.org/)组织,专门研发的替代HEVC的免费开放视频编解码标准。
下图是视频编解码器发展历史。
视频容器
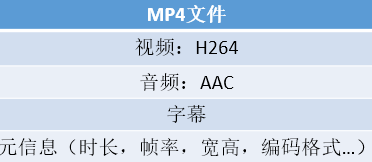
也叫封装格式,把已经编码好的视频、音频裸流按照一定的规范放到一起。里面可能还有元信息(metadata)、字幕、脚本之类。
常见容器格式有:MP4,AVI,FLV,MKV。如下是一个MP4容器文件包含的内容:
参考
[1] YUV.https://en.wikipedia.org/wiki/YUV.
[2] 视频.https://baike.baidu.com/item/%E8%A7%86%E9%A2%91/321962?fr=aladdin.
本文已收录到大话WebRTC专栏,更多精彩请访问《大话WebRTC》。

Comments
赞一个
谢谢,点赞点赞
点赞点赞点赞
赞了
inter prediction