什么是声音
介质振动在听觉系统中产生的反应。是一种波。因为是一种波,所以我们可以用频率、振幅等描述。

图1.蚊子翅膀振动产生声音传到人耳
频率与振幅
有两个基本的物理属性:频率与振幅。声音的振幅就是音量,也叫作响度,频率是单位时间振动次数,频率的高低就是指音调,频率用赫兹(Hz)作单位。
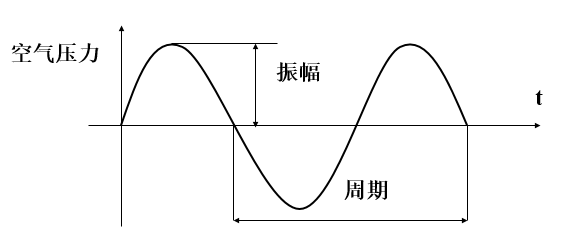
图2.声音波形
人耳只能听到20Hz到20kHz范围的声音。小于20HZ的叫次声波,大于20kHz的叫做超声波。超声波在现实中有很多应用,例如洗牙,测距,成像等。

图3.声音按频率分类
分贝
因为人耳的特性,我们对声音的大小感知呈对数关系。所以我们通常用分贝描述声音大小,分贝(decibel)是量度两个相同单位之数量比例的单位,主要用于度量声音强度,常用dB表示。声学中,声音的强度定义为声压。计算分贝值时采用20微帕斯卡为参考值(通常被认为是人类的最少听觉响应值,大约是3米以外飞行的蚊子声音)。这一参考值是人类对声音能够感知的阈值下限。声压是场量,因此使用声压计算分贝时使用如下公式:
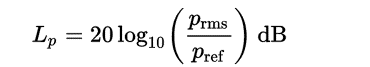
图4.分贝计算(Pref是标准参考声压值20微帕)
由上述公式可知,当声音强度等于Pref时,db=0,也就是说0分贝时声音最小。
模拟音频与数字音频
模拟音频(Analogous Audio),用连续的电流或电压表示的音频信号,在时间和振幅上是连续。在过去记录声音记录的都是模拟音频,比如机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式。
数字音频(Digital Audio),通过采样和量化技术获得的离散性(数字化)音频数据。计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。
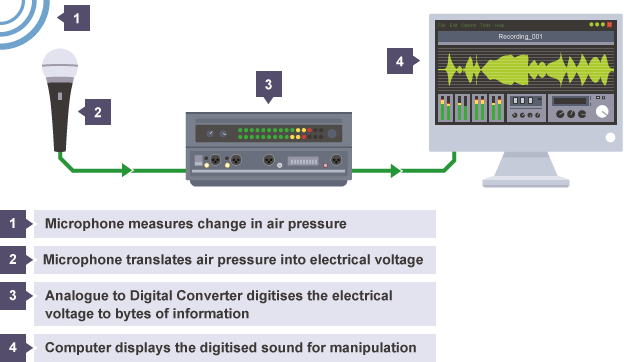
图5.典型的音频采集并转换成计算机处理的数字音频信号流程
采样频率
声音以模拟波形的形式存在。数字音频片段以足够快的速率对模拟波的振幅进行采样,模仿波的固有频率,达到高度接近这种模拟波的效果。
采样频率(Sampling Rate),单位时间内采集的样本数,是采样周期的倒数,指两个采样之间的时间间隔。采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号,这其实就是著名的香农采样定理。例如,要表示人类听觉范围 (20-20000 Hz) 内的音频,数字音频格式必须至少每秒采样 40000 次(CD 音频使用 44100 Hz 的采样率,部分原因也在于此)。
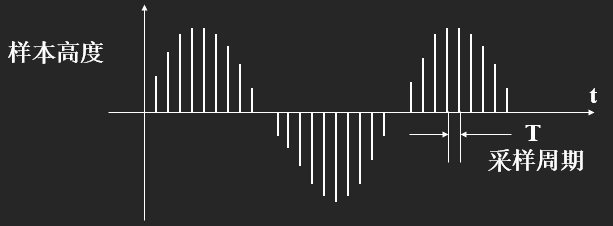
图6.采样频率
CD音质采样率为 44.1 kHz,其他常用采样率:22.05KHz,11.025KHz,一般网络和移动通信的音频采样率:8KHz。采样频率越高,声音质量越好。一般我们语音通信中(VOIP,例如微信,QQ语音聊天),我们对声音质量要求没那么高,能听清讲的什么即可,所以常采用8KHz采样率。
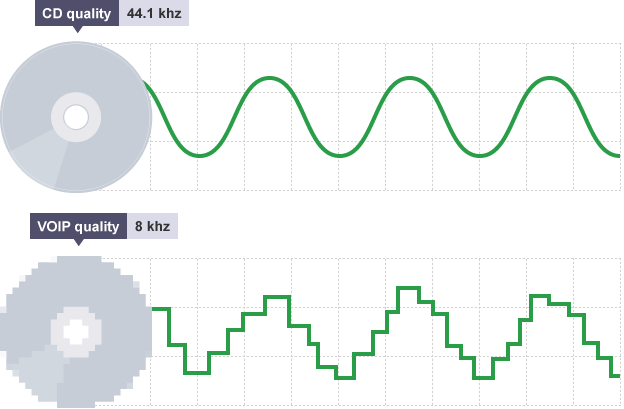
图7.CD以及VOIP采样频率对比
量化
量化(Quantization )是将经过采样得到的离散数据转换成二进制数的过程。量化的过程是先将整个幅度划分成有限个小幅度(量化阶距)的集合,把落入某个阶距内的样值归为一类,并赋予相同的量化值。
量化深度,表示一个样本的二进制的位数,即每个采样点用多少比特表示,在计算机中音频的量化深度一般为4、8、16、32位(bit)等。例如:量化深度为8bit时,每个采样点可以表示256个不同的量化值,而量化深度为16bit时,每个采样点可以表示65536个不同的量化值。量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多,位数越少,声音的质量越低,需要的存储空间越少。CD音质采用的是16 bits,移动通信 8bits。
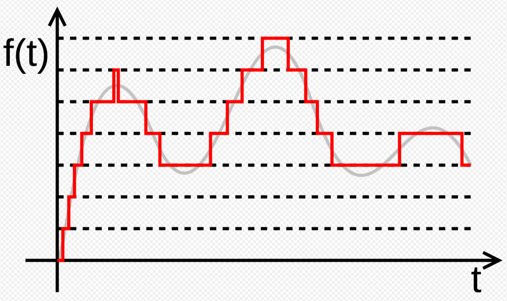
图8.量化信号
存储大小
声道数。记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。使用双声道记录声音,能够在一定程度上再现声音的方位,反映人耳的听觉特性。
数字音频存储大小。采样频率、量化深度数越高,声音质量也越高,保存这段声音所用的空间也就越大。立体声(双声道)存储大小是单声道文件的两倍。即:
文件大小(B)=采样频率(Hz)×录音时间(S)×(量化深度/8)×声道数(单声道为1,双声道为2)
如:录制1分钟采样频率为44.1KHz,量化深度为16位,立体声的声音(CD音质),文件大小为:
44.1×1000×60×(16/8)×2=10584000B≈10.09M
可以看到数字音频信号如果不加压缩地直接进行传送或者存储,将会占用极大的带宽以及磁盘空间,这也是后面讲到的音频要进行压缩的原因。
声音编码压缩
压缩基础
音频数据通常会进行压缩,以便更易于存储和传输。通过采样以及量化得到的数字音频信号中存在着大量冗余。数字音频压缩编码保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩。数字音频压缩编码采取去除声音信号中冗余成分的方法来实现。所谓冗余成分指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为20Hz~20KHz,范围外的其它频率人耳无法察觉,都可视为冗余信号。此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应。
有损压缩与无损压缩
无损压缩。无损压缩虽然缩小音频的储存大小,但可以保留原始文件的所有信息。无损压缩是一个可逆的过程,利用信息冗余进行数据压缩,类似我们平时用的rar,zip等文件压缩。常见无损压缩格式有:APE,FLAC等。
有损压缩。有损压缩是一个不可逆的过程。有损数据压缩利用人类听觉特性,将不重要的声音信息舍弃,虽然有损压缩在理论上对原始文件造成损失,但这种损失不一定能被人耳分辨出来。常见有损压缩格式有:MP3,AAC,OGG等。

Comments
你好 我能转发到csdn上么?写的太好了!
@安子 转载注明出处原文链接即可
写的太棒了
学习了
写的真好,真清晰,谢谢
不懂技术的人看了也能略懂1 2就是不错写的
通俗容懂,神了
写的超棒!