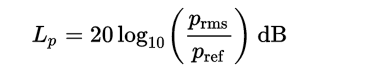
去年写过一篇文章,有关PCM的音量控制:http://blog.jianchihu.net/pcm-volume-control.html。那时阐述了一些概念,对一些细节没有详细描述。因为有人问到使用对数关系调节音量,故开此篇文章。 声学中的分贝 因为人耳的特性,我们对声音的大小感知呈对数关系。所以我们通常用分贝描述声音大小,分贝(decibel)是量度两个相同单位之数量比例的单位,主要用于度量声音强度,常用dB表示。声学中,声音的强度定义为声压。计算分贝值时采用20微帕斯卡为参考值(通常被认为是人类的最少听觉响应值,大约是3米以外飞行的蚊子声音)。这一参考值是人类对声音能够感知的阈值下限。声压是场量,因此使用声压计算分贝时使用下述版本的公式: 其中的pref是标准参考声压值20微帕。 分贝声音变化范围 在编程中,我们可以用以下公式计算两个声音之间的动态范围,单位为分贝: [crayon-69e978e25abf0374344016/] 其中 A1 和 A2 是两个声音的振幅,在程序中表示每个声音样本的大小。声音采样大小(也就是量化深度)为1bit时,动态范围为0,因为只可能有一个振幅。采样大小为8bit也就是一个字节时,最大振幅是最小振幅的 256 倍。因此,动态范围是 48 分贝,计算公式如下: dB = 20 * log(256) 48 分贝的动态范围大约是一个安静房间和一台运行着电动割草机之间的区别。如果将声音采样大小增加一倍到16bit,产生的动态范围则为 96 分贝,计算公式如下: dB = 20 * log(65536) 这非常接近听力最低阈值和产生痛感之间的区别,这个范围被认为非常适合还原音乐。 了解了分贝的相关概念我们通过图表说下为什么要用对数关系描述声音大小。 1)音量滑块与声音增幅大小线性变化。 上述左图中,音量滑块位置与声音振幅为线性增长关系,右图是我们人耳感受的音量大小与滑块位置关系。可知,在左侧移动相同距离的滑块,感知到的声音变化范围很大,在右侧接近声音最大值移动相同距离滑块,感知到的声音大小变化就很小了。 2)音量滑块与声音振幅大小对数关系变化。 左图中,音量滑块位置与声音振幅对数关系增长。右图中无论哪个位置,移动相同距离滑块,感知到的声音变化都是相同的。 需要说明的是滑块最小位置只是接近0,不能为0,因为对数函数y=logx中x>0。 windows系统中音量滑块控制的声音变化范围 在最新版的windows系统中,音量滑块控制的声音变化范围也是96分贝。如下表所示,是不同版本windows的音量范围以及默认音量值。 从表中我们可以看到默认值都是0分贝,根据分贝公式:dB = 20 * log(A1 / A2),当A1,A2相等时,db为0。 程序实现 了解了分贝以及Windows中音量滑块是在哪个范围变化,我们的程序实现起来也很简单。 这里我们规定音量大小变化范围也是96分贝,每个声音采样大小为16位。对于分贝公式:dB = 20 * log(A1 / A2),我们取参考声音振幅A2为原始声音振幅,A1为调节后的声音振幅大小。可知调节后的声音: [crayon-69e978e25abfb252949077/] 看过一篇文章说理想的声音调节步长最好是2db,对于96db范围,我们按2db步长进行分割,可以分成48份,这样我们得到的声音变化为[-96db,-94db,-92db,...-4db.-2db,0db],假设我们要调节一半音量大小,也就是-48db,由上述公式可知:调节后音量A1大小: [crayon-69e978e25ac00008228437/] 程序伪代码如下,具体db大小与滑块位置对应关系的实现这里就不写出: [crayon-69e978e25ac04792294920/] 参考 [1] Audio-Tapered Volume Controls.https://docs.microsoft.com/en-us/windows/win32/coreaudio/audio-tapered-volume-controls
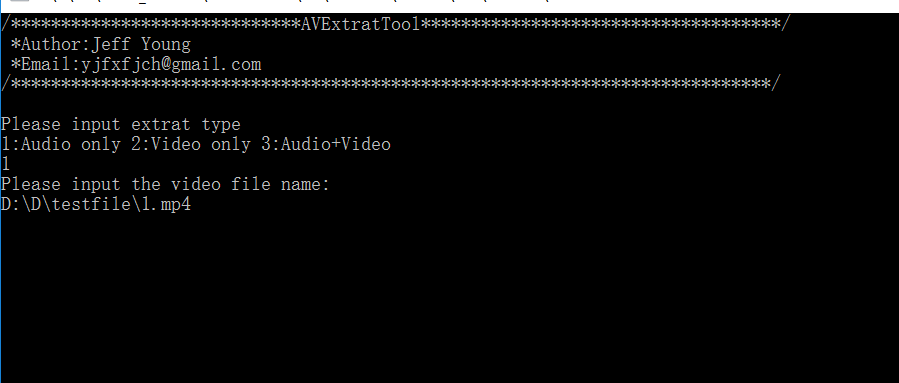
以前搞过播放器的Demuxer模块,业余时间重写了个简单音视频提取工具。可以从视频编码格式为h264+音频编码格式为aac的mp4以及flv封装文件中提取出音视频。写这个工具其实是为了方便自己听歌。因为现在很多音乐都开始注重版权,很多歌下载都要钱,比如网易云音乐,我很喜欢听泰勒的歌曲,以前花钱买过,后面换了部设备,重新下载又得要花钱。不过大部分要花钱的歌曲都有MV可以免费下载,网易云的MV都是mp4格式,现在的mp4基本都是h264+aac,所以我就想从mv中把音频提取出来,这样就可以随便听了。说完这些介绍下这个工具的使用。 工具下载链接在文章末尾,只有几十K,没有用到大多数播放器都用到的ffmpeg,ffmpeg都几十兆了。这个工具是个简单的命令行工具。界面如下: 1)第一步按提示输入提取类型,输入1只提取音频文件,输入2只提取视频文件,输入3提取音视频; 2)第二步输入视频文件名(如果视频文件与程序不在一个目录还要输入路径),最简单的方法是直接拖放视频文件到程序。 3)回车等待解析。提取结束会在程序目录生成对应文件。音频为audio.aac,视频为video.h264。 下载地址:http://jchblog.u.qiniudn.com/201703/ExtratTool.zip 由于之前写的这个软件找不到了,地址也失效了,故提供一个ffmpeg版本的,下载解压后,运行bat文件,输入要操作mp4文件名即可。 ffmpeg版本下载地址:https://gitee.com/jianchihu/jchcdn/raw/master/download/mp4toaac.zip

简介 Media SDK 是一个软件开发库,包含解码、视频处理和编码三大模块。利用 Intel 平台的硬件加速能力, Media SDK 为低端用户提供了优秀的高清视频质量,极大的降低了播放高清视频的硬件门槛。此外,强大的视频 APIs 也减轻了程序开发者的工作负担,使他们能够集中精力去处理程序的逻辑模块,而不必关心于 Media SDK 内部的复杂编解码逻辑及其如何提高效率。 本篇文章将着重讲述如何利用 Media SDK 提高程序的效率,面对的读者主要是视音频程序开发人员。 本文以下内容为: - 初始化设置之优化 - 内存选择之优化 - 多线程之优化 - 异步方式之优化 初始化设置之优化 在讨论优化之前,首先要了解一下 Media SDK 是如何初始化编解码器的。 1. 创建和初始化一个编解码 Session。Media SDK 提供了 mfxStatus MFXInit(mfxIMPL impl,mfxVersion *ver, mfxSession *session)函数来完成这个创建和初始化工作。 2. 使 用 已 创 建 的 Session 来 创 建 它 的 解 码 器 。 Media SDK 提 供 了 mfxStatus MFXVideoDECODE_Init(mfxSession session, mfxVideoParam *par)来完成解码器的创建和初始化工作。 3. 使 用 已 创 建 的 Session 来 创 建 它 的 编 码 器 。 Media SDK 提 供 了 mfxStatus MFXVideoENCODE_Init(mfxSession session, mfxVideoParam *par)来完成编码器的创建和初始化工作。 在创建和初始化编解码 Session 时,我们需要制定编解码的实现方式:硬件方式还是软件方式。最简单的方法是强制使用硬件方式。这会带来一个问题,在非 Intel 显卡支持的平台,应用程序将无法正常工作。当然,如果强制使用软件方式,虽然应用程序能够工作于其他平台,但是在 Intel 显卡平台,硬件加速特性将荡然无存!虽然应用程序可以外加代码检测平台硬件来决定如何选择,但是程序的复杂度和效率将受到影响。Media SDK 内部提供了自动选择功能,它会根据当前运行系统来选择何种方式。这样就能够兼顾不同平台及其性能。 在 MFXInit 函数中,枚举类型 mfxIMPL 定义 AUTO 功能: [crayon-69e978e25cf9a358838779/] 相应的简单实用方式如下: [crayon-69e978e25cfa4317587121/] 通过 MFX_IMPL_AUTO 的设置,问题迎刃而解。 那么如何获知当前的编解码实用方法呢?Media SDK 已经考虑到了这种需求,它提供了mfxStatus MFXQueryIMPL(mfxSession session, mfxIMPL *impl)来查询当前采用的方法。 此外,在优化编码器初始化时,程序必须注意 mfxInfoMFX 结构中 TargetUsage 变量的选择,它的定义如下: [crayon-69e978e25cfa8153655740/] TargetUsage 值的选择决定了编码的性能和图像质量,它的值从 0~7,值越高效率越好,但图像质量会有所下降。最佳值应该和用户选择需求挂钩,原则上是略比最小用户需求高 1 级。 本节小结: 1. 初始化 Session 时,要使用 MFX_IMPL_AUTO。它有利于跨越硬件平台,并提高编解码效率。 2. TargetUsage 的选择应该和用户需求相结合。为了提高性能,选择略高于用户最小需求的值为佳。 内存选择之优化 Media SDK 使用内存缓冲来输入/输出视频数据,内存缓冲的不同种类将会直接影响编解码的效率。内存缓冲可以是一块在系统内存中的连续块(通过 malloc 或者 new 来分配),也可以是显卡内存的连续块(通过 Microsoft Direct3D9 Surface 函数来分配)。那么内存缓冲的 种类由谁来决定呢?本节就是以此为基础,讨论在不同情况下程序如何选择内存缓冲种类的问题。 在讨论内存缓冲对编解码影响之前,先讨论下面三种情况下的内存数据传送问题。 - 系统内存间数据如何传送? 对于程序员而言,这个是最为简单的日常编程事项。一般的使用方式是 memcpy,在一些数据较大情况下(超过 L3 的 cache 尺寸时候,用 movntqa 等指令)。不管何种方式,都是CPU-BASED 的代码,在 SIMD 下效率很高。 - 显存间数据是如何传送的? 它类似于系统内存之间的数据传送,并且显存的带宽和速率都很高,传送速度更快。 - 显存和系统内存间数据是如何传送的? 通过 DMA 方式传送内存数据,速度依赖于 DMA 的带宽和速率(普通 DMA 的传送速率在33.3MB/s,而 Ultra DMA 最高也不过 100MB/s)。相比与上述两种情况,它的传送速度明显慢。 从上面的三种情况可以看出,程序一定要尽量避免出现系统内存和显存之间的数据传送,那么 Media SDK 在什么配置下会出现此类尴尬状态呢? 初始化设置之优化小节中,程序通过 MFX_IMPL_AUTO 参数根据当前平台来自动选择硬件或软件编解码,并能通过 mfxStatus MFXQueryIMPL(mfxSession session, mfxIMPL *impl)函数来获取当前平台的编解码方式,在此将获取的编码方式分别讨论。 a)使用硬件编解码方式 硬件编解码方式主要是通过显卡的硬件加速达到高效编解码的作用,也就是说它的核心是显卡。如果我们使用系统内存为其提供缓存,会出现什么情况呢?显然,在数据输出/输出时,程序必将会有显存和系统内存之间的数据传送作用,效能将受到严重影响。在此情况下,程序的最好选择就是显存,否则必将受到性能惩罚! b)使用软件编解码方式 很显然,软件编解码的核心是 CPU。如果我们使用显存作为其缓冲,那么必将导致显存和系统内存之间的数据交互,也就会导致速度低下的程序出现,故此,系统内存是它的不二选择! 本节小结: Media SDK 中内存类型的选择分两步走: 1. 使用 MFXQueryIMPL 函数来查询当前的编解码方式。 2. 根据编解码方式(MFX_IMPL_SOFTWARE 为软件;MFX_IMPL_HARDWARE 为硬件)来决定内存选用类型。为了便于日后方便查询,笔者建立了一个小表格,如表 1 所示,以供参考。 此外,笔者对 Media SDK 的两种不同内存类型在解码器下做了一个简单的比较。在软件解码方式下,显存选取要比内存选取慢了近 1 倍,这个是相当可观的数字!切忌,正确选取内存是高效程序的基本点! 多线程之优化 初始化设置之优化小节和内存选择之优化小节中,已经对 Media SDK 的两个重要配置部分进行了分析和总结。本节,我们将着重讨论如何使用多线程技术提高视频 Converter 的效能(一种视频的常用应用)。 在运用 Media SDK 进行格式转换时,一般要涉及三大模块,他们是 Decoder,VPP 和 Encoder,数据输入输出如图 1 所示。 从图 1 可以看出,每经过一个模块,都要对数据进行同步操作。在此期间,其他两个模块是处于空闲状态,是一个典型的串行处理过程。对于英特尔的多核技术,它的多核利用率是最低的,相应的效率也较差。 那么如何对现有流程进行多线程化呢? 本节提供了一种最简单的方法,即对每个模块线程化。请参考图 2 所示。 图 2 将 Decoder,VPP 和 Encoder 三个模块分别线程化,在彼此之间以队列(queue)为数据交换。 简单的工作模式如下: - 若队列为空,后级模块等待数据。 -…


elst全称Edit List Box,mp4文件中不一定都含有这个box。该box作用是使某个track的时间戳产生偏移。 结构 在ISO_IEC_14496-12中,elst结构定义如下: segment_duration:表示该edit段的时长,以Movie Header Box(mvhd)中的timescale为单位。 media_time:表示该edit段的起始时间,以track中Media Header Box(mdhd)中的timescale为单位。如果值为-1,表示是空edit,一个track中最后一个edit不能为空。 media_rate:edit段的速率为0的话,edit段相当于一个"dwell",即画面停止。画面会在media_time点上停止segment_duration时间。否则这个值始终为1。 例子 现在我们手里有个mp4文件,我们要让封装的视频延迟10秒才开始显示,封装的音频不变,这个可以通过修改视频的时间戳实现,将视频的所有时间戳都加上10秒,但是一个个改太麻烦了,此时elst就派上用场了,我们要通过它让视频时间戳偏移10秒。 下面我们先动手操作番,了解elst如何起作用。 1)找一个没有elst box的mp4文件:test.mp4,假设我放在D:\\bin目录下。至于mp4有没有包含elst可以用文章末尾链接提供的mp4分析工具Mp4Reader分析下。用mediainfo查看该视频的信息: 该mp4音视频时长都为3分32秒。 2)得到带elst的mp4。到https://gpac.wp.mines-telecom.fr/mp4box/ 下载windows下的mp4box,按提示一步步安装。 打开windows cmd命令行,cd到test.mp4目录,然后敲入Mp4Box的命令: [crayon-69e978e25d9bf058049713/] 得到: 由此可知test.mp4中,视频的track id 为1,音频track id为2。 3)接着我们敲如下命令: [crayon-69e978e25d9c7679521789/] 由于我们只对视频操作,视频track id是1,所以是#1:delay=10000。得到: 此时在bin目录下会生成一个delay_10s.mp4,该mp4中视频track延迟了10秒,音频track不变。mediainfo查看delay_10s.mp4信息: 可以看到视频的时长多了10秒 4)打开mp4reader查看视频track的elst信息: 也就是: [crayon-69e978e25d9cb747099932/] 可以看到有两个elst entry,第一个为空,Segment-duration为6000,由于timescale为600(该timescale在mvhd中获 得),6000除以timescale刚好为10秒。由此可知我们要延迟播放某个track,可以在elst中插入一个空的entry,Segment-duration设置为需要延迟播放的时间,Media-Time设置为-1,然后在插入一个entry,Segment-duration设置为正常播放时间,Media-Time也就是起始时间设置为0。 5)播放器验证。我们使用vlc播放器打开delay_10s.mp4: 前10秒视频没有播放,而声音正常播放,到第10秒时视频才开始播放,等声音播放结束后,视频还会播放10秒,可以看出视频确实是推迟了10秒播放,此时音视频已经不同步了。 不是所有的播放器都支持elst的,我测试了下,vlc与potplayer支持,windows自带播放器就不支持。 ffmpeg相关代码分析 下面结合ffmpeg中相关代码以及上面的视频延迟10秒的例子分析,看ffmpeg中对elst数据如何处理。ffmpeg中elst entry数据存放在MOVElst 结构体中: [crayon-69e978e25d9ce668240141/] duration对应mp4标准中的segment_duration time对应mp4标准中的media_time 在ffmpeg源码libavformat\mov.c中的mov_build_index函数中有如下代码: [crayon-69e978e25d9d2495812745/] 第8行代码中可以知道,如果e->time == -1,也就是第一个elst为空,此时得到empty_duration,按前面的例 子该值为10*timescale,下一个for循环得到start_time =e->time,值为0。 在第26行代码中,可知sc->time_offset =0 -10*timescale = -10timescale,然后所有dts都要减去该sc->time_offse,最后结果是都加上10timescale,与原来时间戳比相当于延迟了10s。所以当mp4存在elst时,dts要按如下计算: 1.参考上述ffmpeg代码得到time_offset 2.解码时间戳dts = sample_delta * n – time_offset,其中sample_delta在stts中获得,如果存在B帧,还要从ctts中获得sample_offset,此时: 显示时间戳pts= dts+ sample_offset 否则pts = dts。 接下来我们使用ffmpeg验证下,打印出所有viedeo packet的dts与pts: 可以看到所有时间戳都偏移了230000,也就是10timescale,在video track的mdhd中可知timescale为23000,刚好是10timescale = 23000*10: 由此可知elst的作用就是使某个track时间戳偏移,达到延迟播放的效果。在我们解析mp4文件时,如果存在elst,一定要解析,然后配合stts与ctts,这样才可以得到正确的时间戳。 相关下载 Mp4Reader:https://pan.baidu.com/s/1cBC_yRR-BUfMGpUnC2LN8g
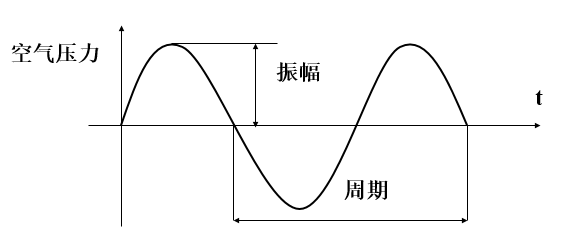
一、声音的相关概念 声音是介质振动在听觉系统中产生的反应。声音总可以被分解为不同频率不同强度正弦波的叠加(傅里叶变换)。 声音有两个基本的物理属性:频率与振幅。声音的振幅就是音量,频率的高低就是指音调,频率用赫兹(Hz)作单位。人耳只能听到20Hz到20khz范围的声音。 模拟音频(Analogous Audio),用连续的电流或电压表示的音频信号,在时间和振幅上是连续。在过去记录声音记录的都是模拟音频,比如机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式。 数字音频(Digital Audio),通过采样和量化技术获得的离散性(数字化)音频数据。计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。 采样频率(Sampling Rate),单位时间内采集的样本数,是采样周期的倒数,指两个采样之间的时间间隔。采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号,这其实就是著名的香农采样定理。CD音质采样率为 44.1 kHz,其他常用采样率:22.05KHz,11.025KHz,一般网络和移动通信的音频采样率:8KHz。 量化深度,表示一个样本的二进制的位数,即样本的比特数。量化是将经过采样得到的离散数据转换成二进制数的过程,量化深度表示每个采样点用多少比特表示,在计算机中音频的量化深度一般为4、8、16、32位(bit)等。例如:量化深度为8bit时,每个采样点可以表示256个不同的量化值,而量化深度为16bit时,每个采样点可以表示65536个不同的量化值。量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。CD音质采用的是16 bits,移动通信 8bits。 声道数,记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。使用双声道记录声音,能够在一定程度上再现声音的方位,反映人耳的听觉特性。 数字音频存储大小。采样频率、量化深度数越高,声音质量也越高,保存这段声音所用的空间也就越大。立体声(双声道)存储大小是单声道文件的两倍。即:文件大小(B)=采样频率(Hz)×录音时间(S)×(量化深度/8)×声道数(单声道为1,立体声为2) 如:录制1分钟采样频率为44.1KHz,量化深度为16位,立体声的声音(CD音质),文件大小为: 44.1×1000×60×(16/8)×2=10584000B≈10.09M 二、PCM 音频编码,指将模拟音频转换成数字音频并以某种格式存储的技术或过程。 PCM(Pulse Code Modulation)编码,即通过脉冲编码调制方法生成数字音频数据的技术或格式,是一种无损编码格式,是音频模拟信号数字化的一种方法,需要经过采样、量化和编码过程,以实现音频模拟信号数字化。 首先从6个方面描述PCM: 1)采样率; 2)符号:表示样本数据是否是有符号位,比如用一字节表示的样本数据,有符号的话表示范围为-128~127,无符号就是0~255,; 3)字节序:字节序分为大端与小端; 4)样本大小:决定了每个样本由多少位组成,即前面说到的量化深度,一般16位是最常见的; 5)声道数:分为单声道与双声道。 6)整形或浮点型:大多数格式的PCM样本数据使用整形表示,然而在一些对精度要求高的应用方面,使用浮点类型表示PCM样本数据。 打开ffmpeg,敲:ffmpeg -formats命令,获取ffmpeg支持的音视频格式,在这当中我们可以找到支持的PCM格式 [crayon-69e978e25ea4c586308565/] 比如DE s16be,就表示一个样本用16bits有符号的整形数据表示,字节序为大端。 假设我们有一个PCM signed 16-bit little-endian,双声道的PCM文件。如下是文件中前9个样本: [crayon-69e978e25ea56314344267/] 每个样本2字节,总共18字节,每个样本取值范围:-32768 ~ 32767。 三、PCM音量控制 通过前面描述我们对PCM有了个了解,知道了在PCM流中数据如何存储。下面我们先看一个真正的音频样本波形: 如果我们放大5倍波形,也就是振幅乘以5,此时我们听到了更大的声音,此时样本波形如下: 假如我们有2048bytesPCM数据,样本大小两个字节,共有1024个样本,我们要放大两倍声音,代码可以按如下写: [crayon-69e978e25ea5a965696605/] 这是不是很简单,但是接下来我们还需要考虑两个方面的问题。 数据溢出 因为每个样本取值范围是有限制的,调节音量时不可能随便增大,比如一个signed 16 bits的样本,值为5000,我们放大10倍,由于有符号位16bits数据取值范围为-32768~32767,5000乘以10得到的50000超过了32767,数据溢出了,最后值可能变为-15536,不是我们期望的。此时我们就需要裁剪了,确保数值在正确范围内。如下代码对前面说到的放大两倍声音做了裁剪处理: [crayon-69e978e25ea5e863020957/] 对数描述 平时表示声音强度我们都是用分贝(db)作单位的,声学领域中,分贝的定义是声源功率与基准声功率比值的对数乘以10的数值。根据人耳的心理声学模型,人耳对声音感知程度是对数关系,而不是线性关系。人类的听觉反应是基于声音的相对变化而非绝对的变化。对数标度正好能模仿人类耳朵对声音的反应。所以用分贝作单位描述声音强度更符合人类对声音强度的感知。前面我们直接将声音乘以某个值,也就是线性调节,调节音量时会感觉到刚开始音量变化很快,后面调的话好像都没啥变化,使用对数关系调节音量的话声音听起来就会均匀增大。 如下图,横轴表示音量调节滑块,纵坐标表示人耳感知到的音量,图中取了两块横轴变化相同的区域,音量滑块滑动变化一样, 但是人耳感觉到的音量变化是不一样的,在左侧也就是较安静的地方,感觉到音量变化大,在右侧声音较大区域人耳感觉到的音量变化较小。 下面我们讲下音量值乘数取值,这里我只简单的用tan函数模拟,效果也不错,至于使用对数如何调整请参考文末链接: [crayon-69e978e25ea61685180224/] 上面代码中音量乘数取值为tan (some_level / 100.0 ),最后实现代码如下: [crayon-69e978e25ea65629898729/] 其中level取值需要具体测试实现,一般使用时level取值为某个范围的几个数,比如取10个数,这样音量就有10个阶跃可以调节。 如下图,最后声音音量近似按对数关系增长了: 如果想了解利用对数关系调节音量的具体实现,请参考: PCM音量控制(高级篇)
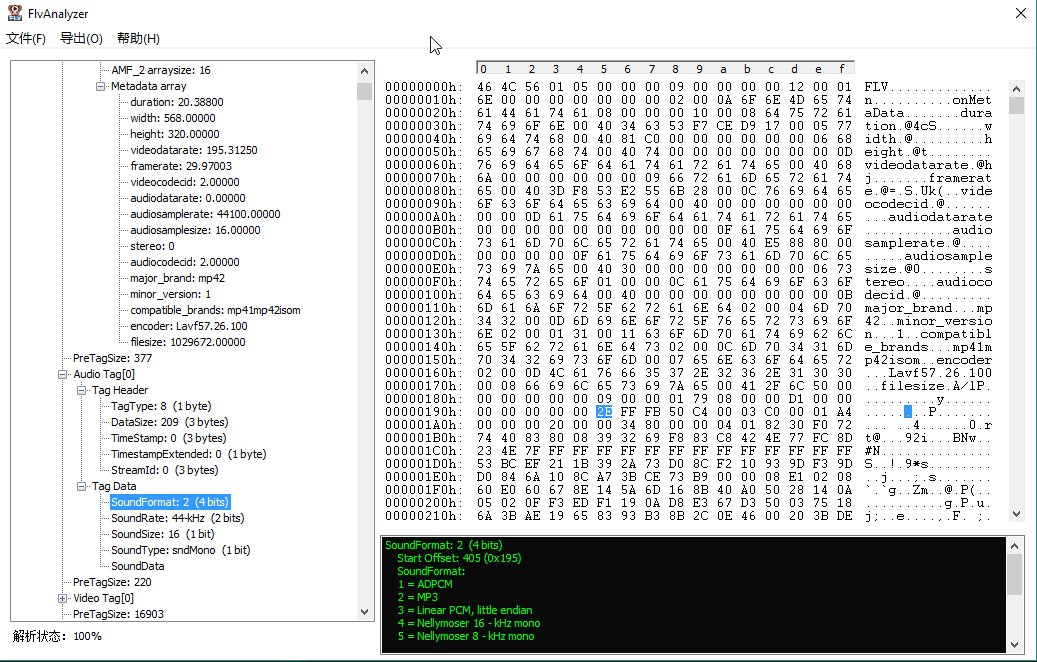
在学习视频文件的解析时,刚开始我都是用ultraedit配合标准文档查看,不是很方便,后来在网上看到了一个叫flvparse的程序,虽然做的很粗糙,但是为flv文件的学习提供了帮助。现在我自己对flv,avi,mp4文件都非常了解了。在业余时间也做了一个flv文件的分析程序,完全按照flv标准文档解析,每一个字段都清楚展示出来,可以说是网上最强大的一个flv分析工具了(应该是这样的,还没见过比这好的)。flv在流媒体领域应用很广泛的,想做流媒体,视频直播这一块的都得学习flv封装格式,所以希望这个工具对于那些初学者有所帮助。 为了不跟网上其他工具重名,就取了个FlvAnalyzer的名字,目前发布的是第一版。 FlvAnalyzer V1.0 目前支持如下功能: 1)左侧树状结构显示flv的文件结构信息,可以清楚了解flv文件的结构; 2)点击左侧节点,右侧显示对应hex与ascii信息,这样就不必打开二进制编辑器了; 3)详细显示audio tag与video tag各个字节(精确到bit)的详细信息,了解每个tag是如何构造的,同时右下角黑色输出框显示某个值的意义; 4)程序限制最大200M的文件内容显示,显示太多没必要。 如果遇到使用问题或希望改进的,欢迎提出,其他地方下载的遇到的问题概不负责。 -------------------------------------------------------------------------------------- FlvAnalyzer最新版下载地址:https://pan.baidu.com/s/1vmf6yuYAUh5nOk1CBXy8tQ 提取码: qiah 转眼4年多过去了,4年前业余时间写的工具发现用户挺多的,当然软件也有很多Bug,代码也有4年多没更新了,准备抽出时间开发第二版了,希望这款工具软件能帮助更多人。 -- 2020.08.17
现在VR是越来越火,VR全景视频在未来会有很大普及,颠覆人们传统看视频方式。目前VR视频都是将不同角度拍摄的视频进行拼接而成的,然后通过特定播放器播放。自己对这也很感兴趣,视频拼接目前还没实力搞,先打算做个全景视频播放器。目前思路如下: 1)获取拼接前的各个角度视频; 2)使用某个游戏引擎(比如unity)或者图像渲染引擎(OGRE,大学毕设用过)构造一个立体的物体,可以是球体,立方体,锥体等等; 3)解码之前获取的各个角度视频,然后映射到构造的立体物体上; 4)由于在游戏引擎的世界中我们可以360度浏览虚拟世界,我们将我们的相机放在前面构造的立体物体内,也就是从立体物体内部角度浏览,这样就可以浏览360度的全景视频了。