简介
Media SDK 是一个软件开发库,包含解码、视频处理和编码三大模块。利用 Intel 平台的硬件加速能力, Media SDK 为低端用户提供了优秀的高清视频质量,极大的降低了播放高清视频的硬件门槛。此外,强大的视频 APIs 也减轻了程序开发者的工作负担,使他们能够集中精力去处理程序的逻辑模块,而不必关心于 Media SDK 内部的复杂编解码逻辑及其如何提高效率。
本篇文章将着重讲述如何利用 Media SDK 提高程序的效率,面对的读者主要是视音频程序开发人员。
本文以下内容为:
- 初始化设置之优化
- 内存选择之优化
- 多线程之优化
- 异步方式之优化
初始化设置之优化
在讨论优化之前,首先要了解一下 Media SDK 是如何初始化编解码器的。
1. 创建和初始化一个编解码 Session。Media SDK 提供了 mfxStatus MFXInit(mfxIMPL impl,mfxVersion *ver, mfxSession *session)函数来完成这个创建和初始化工作。
2. 使 用 已 创 建 的 Session 来 创 建 它 的 解 码 器 。 Media SDK 提 供 了 mfxStatus MFXVideoDECODE_Init(mfxSession session, mfxVideoParam *par)来完成解码器的创建和初始化工作。
3. 使 用 已 创 建 的 Session 来 创 建 它 的 编 码 器 。 Media SDK 提 供 了 mfxStatus MFXVideoENCODE_Init(mfxSession session, mfxVideoParam *par)来完成编码器的创建和初始化工作。
在创建和初始化编解码 Session 时,我们需要制定编解码的实现方式:硬件方式还是软件方式。最简单的方法是强制使用硬件方式。这会带来一个问题,在非 Intel 显卡支持的平台,应用程序将无法正常工作。当然,如果强制使用软件方式,虽然应用程序能够工作于其他平台,但是在 Intel 显卡平台,硬件加速特性将荡然无存!虽然应用程序可以外加代码检测平台硬件来决定如何选择,但是程序的复杂度和效率将受到影响。Media SDK 内部提供了自动选择功能,它会根据当前运行系统来选择何种方式。这样就能够兼顾不同平台及其性能。
在 MFXInit 函数中,枚举类型 mfxIMPL 定义 AUTO 功能:
|
1 2 3 4 5 6 |
typedef enum { MFX_IMPL_AUTO=0, /* Auto Selection/In or Not Supported/Out */ MFX_IMPL_SOFTWARE, /* Pure Software Implementation */ MFX_IMPL_HARDWARE, /* Hardware Accelerated Implementation */ MFX_IMPL_UNSUPPORTED=0 /* One of the MFXQueryIMPL returns */ } mfxIMPL; |
相应的简单实用方式如下:
|
1 2 |
mfxVersion version = {MFX_VERSION_MINOR, MFX_VERSION_MAJOR}; sts = m_mfxSession.Init(MFX_IMPL_AUTO, &version); |
通过 MFX_IMPL_AUTO 的设置,问题迎刃而解。
那么如何获知当前的编解码实用方法呢?Media SDK 已经考虑到了这种需求,它提供了mfxStatus MFXQueryIMPL(mfxSession session, mfxIMPL *impl)来查询当前采用的方法。
此外,在优化编码器初始化时,程序必须注意 mfxInfoMFX 结构中 TargetUsage 变量的选择,它的定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
typedef struct { mfxU32 reserved[8]; mfxFrameInfo FrameInfo; mfxU32 CodecId; mfxU16 CodecProfile; mfxU16 CodecLevel; mfxU16 NumThread; union { /* ENCODE */ struct { mfxU16 TargetUsage; mfxU16 GopPicSize; mfxU16 GopRefDist; mfxU16 GopOptFlag; mfxU16 IdrInterval; mfxU16 RateControlMethod; mfxU16 InitialDelayInKB; mfxU16 BufferSizeInKB; mfxU16 TargetKbps; mfxU16 MaxKbps; mfxU16 NumSlice; mfxU16 NumRefFrame; mfxU16 EncodedOrder; }; struct { /* DECODE */ mfxU16 DecodedOrder; mfxU16 reserved2[12]; }; }; } mfxInfoMFX; /* TargetUsages: 1~7; */ enum { MFX_TARGETUSAGE_UNKNOWN =0, MFX_TARGETUSAGE_BEST_QUALITY =1, MFX_TARGETUSAGE_BALANCED =4, MFX_TARGETUSAGE_BEST_SPEED =7 }; |
TargetUsage 值的选择决定了编码的性能和图像质量,它的值从 0~7,值越高效率越好,但图像质量会有所下降。最佳值应该和用户选择需求挂钩,原则上是略比最小用户需求高 1 级。
本节小结:
1. 初始化 Session 时,要使用 MFX_IMPL_AUTO。它有利于跨越硬件平台,并提高编解码效率。
2. TargetUsage 的选择应该和用户需求相结合。为了提高性能,选择略高于用户最小需求的值为佳。
内存选择之优化
Media SDK 使用内存缓冲来输入/输出视频数据,内存缓冲的不同种类将会直接影响编解码的效率。内存缓冲可以是一块在系统内存中的连续块(通过 malloc 或者 new 来分配),也可以是显卡内存的连续块(通过 Microsoft Direct3D9 Surface 函数来分配)。那么内存缓冲的
种类由谁来决定呢?本节就是以此为基础,讨论在不同情况下程序如何选择内存缓冲种类的问题。
在讨论内存缓冲对编解码影响之前,先讨论下面三种情况下的内存数据传送问题。
- 系统内存间数据如何传送?
对于程序员而言,这个是最为简单的日常编程事项。一般的使用方式是 memcpy,在一些数据较大情况下(超过 L3 的 cache 尺寸时候,用 movntqa 等指令)。不管何种方式,都是CPU-BASED 的代码,在 SIMD 下效率很高。
- 显存间数据是如何传送的?
它类似于系统内存之间的数据传送,并且显存的带宽和速率都很高,传送速度更快。
- 显存和系统内存间数据是如何传送的?
通过 DMA 方式传送内存数据,速度依赖于 DMA 的带宽和速率(普通 DMA 的传送速率在33.3MB/s,而 Ultra DMA 最高也不过 100MB/s)。相比与上述两种情况,它的传送速度明显慢。
从上面的三种情况可以看出,程序一定要尽量避免出现系统内存和显存之间的数据传送,那么 Media SDK 在什么配置下会出现此类尴尬状态呢?
初始化设置之优化小节中,程序通过 MFX_IMPL_AUTO 参数根据当前平台来自动选择硬件或软件编解码,并能通过 mfxStatus MFXQueryIMPL(mfxSession session, mfxIMPL *impl)函数来获取当前平台的编解码方式,在此将获取的编码方式分别讨论。
a)使用硬件编解码方式
硬件编解码方式主要是通过显卡的硬件加速达到高效编解码的作用,也就是说它的核心是显卡。如果我们使用系统内存为其提供缓存,会出现什么情况呢?显然,在数据输出/输出时,程序必将会有显存和系统内存之间的数据传送作用,效能将受到严重影响。在此情况下,程序的最好选择就是显存,否则必将受到性能惩罚!
b)使用软件编解码方式
很显然,软件编解码的核心是 CPU。如果我们使用显存作为其缓冲,那么必将导致显存和系统内存之间的数据交互,也就会导致速度低下的程序出现,故此,系统内存是它的不二选择!
本节小结:
Media SDK 中内存类型的选择分两步走:
1. 使用 MFXQueryIMPL 函数来查询当前的编解码方式。
2. 根据编解码方式(MFX_IMPL_SOFTWARE 为软件;MFX_IMPL_HARDWARE 为硬件)来决定内存选用类型。为了便于日后方便查询,笔者建立了一个小表格,如表 1 所示,以供参考。

此外,笔者对 Media SDK 的两种不同内存类型在解码器下做了一个简单的比较。在软件解码方式下,显存选取要比内存选取慢了近 1 倍,这个是相当可观的数字!切忌,正确选取内存是高效程序的基本点!
多线程之优化
初始化设置之优化小节和内存选择之优化小节中,已经对 Media SDK 的两个重要配置部分进行了分析和总结。本节,我们将着重讨论如何使用多线程技术提高视频 Converter 的效能(一种视频的常用应用)。
在运用 Media SDK 进行格式转换时,一般要涉及三大模块,他们是 Decoder,VPP 和 Encoder,数据输入输出如图 1 所示。
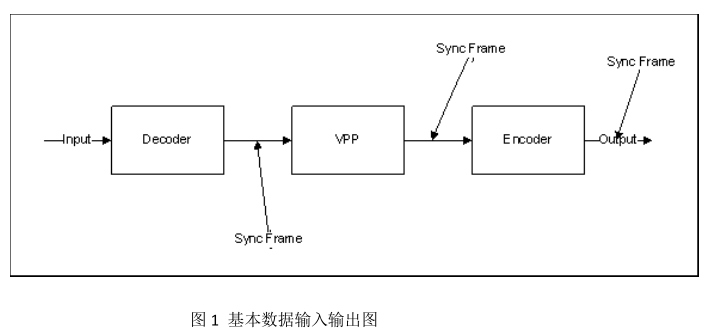
从图 1 可以看出,每经过一个模块,都要对数据进行同步操作。在此期间,其他两个模块是处于空闲状态,是一个典型的串行处理过程。对于英特尔的多核技术,它的多核利用率是最低的,相应的效率也较差。
那么如何对现有流程进行多线程化呢?
本节提供了一种最简单的方法,即对每个模块线程化。请参考图 2 所示。
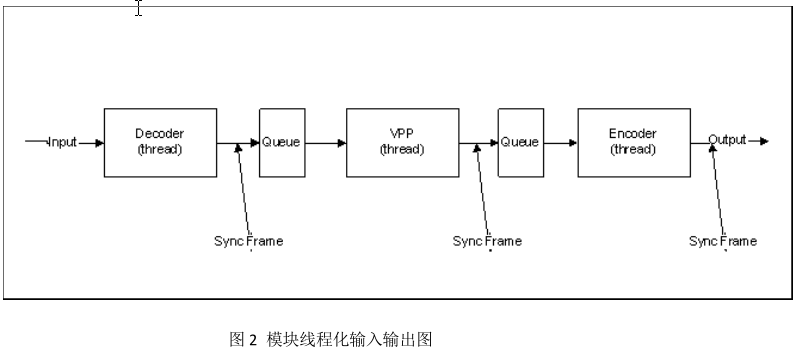
图 2 将 Decoder,VPP 和 Encoder 三个模块分别线程化,在彼此之间以队列(queue)为数据交换。
简单的工作模式如下:
- 若队列为空,后级模块等待数据。
- 若队列被填充,前级模块通知后级模块。
- 若无输入数据,前级模块通知后级模块结束工作,后自行了断。
虽然这种线程化的工作增加的程序的复杂性,但是对于赢得的性能而言是值得的。在理想状态下,我们看到三个模块的并行工作,转化时间的长短取决于最为耗时模块。
本节小结:
1. Media SDK 仅仅提供硬件加速能力,线程化工作展开于具体应用。
2. 三个模块线程化是一种常用的实现,但是如何充分利用英特尔的多核技术,应该建立在具体分析的基础之上。英特尔提供了丰富的性能检测和优化工具,他们能够帮助程序员找出关键问题所在。
3. VPP 模块是可选的,如果应用没有采用,就将 Decoder 后的队列直接连接到 Encoder 之前。
异步方式之优化
多线程之优化小节中已经讲述了如何使用多线程提高编解码的效能问题。因为增加了队列(Queue)的创建和维护等附加工作,使程序的复杂性有所增加,那么还有没有其他优化方法呢?本节主要从异步角度出发,讨论如何采用合适的异步方法来提高编解码器的效能问题。
在多线程方案中,我们使用队列(Queue)的同步机制来保证三个模块的协同工作,如图 3所示。
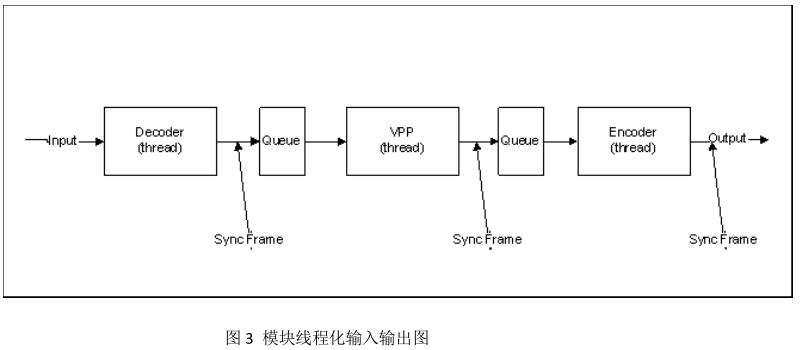
从图 3 中,有两个基本的开销点:
- 需要 3 次同步帧(SyncFrame)来完成一次编解码动作。
- 模块间的 2 个共享 Queue 都需要做同步操作。
这两个开销点对于多线程效率和竞争是不利的,那么有什么方法可以剔除或减小这种开销呢?
Media SDK 提供了异步机制,它提供了三个函数支持相应的三个模块:
- MFXVideoDECODE_DecodeFrameAsync
- MFXVideoVPP_RunFrameVPPAsync
- MFXVideoENCODE_EncodeFrameAsync
模块异步工作原理如图 4 所示。
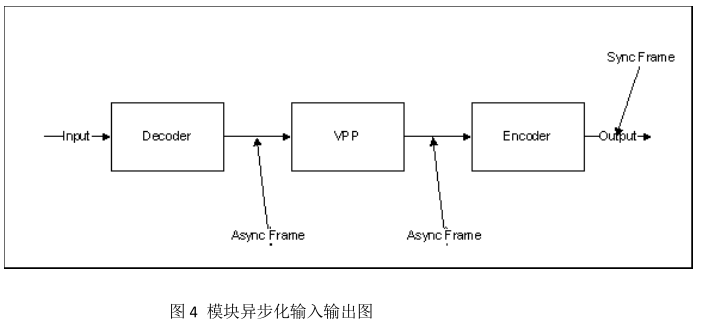
相比于多线程模式,它有几个优点:
- 只需要一次帧同步,而其他两次的异步操作基本上不耗时间,节省了时间。
- 不需要队列的同步操作,提高了效率。
- 不需要多线程,一个线程搞定三个模块,实现复杂度低。
本节小结:
1. 异步模式对于硬件编解码比较适合。它的效能高,软件复杂度低。在软件编解码中,它的效能和简单串行模式无太多优势,所以可考虑采用多线程模式来实现。
2. 多线程模式和异步模式仅仅是提高效率的两种方法,它们之间没有冲突,应用可以根据自身的需求灵活采用,也可以混合运用,提高效率。
总结
虽然使用 Media SDK 提供的 APIs 非常的方便,但是它也有一定的使用技术。正确的使用这些 APIs 能够极大的提高程序的运行效率、移植性和可维护性。本文着重讲述了四个重要的 Media SDK 编程技术,通过分析和揭露 Media SDK 的工作机制,能够让程序员充分认识到Media SDK 的内在工作方式,为视音频软件开发的性能提高起到积极作用。

Comments