Preface
With the arrival of the era of large-model voice conversations (ChatGPT-4o, Gemini Live, Doubao, etc.), high-naturalness, zero/few-shot voice cloning has become one of the core pain points for AI application deployment. Whether it’s AI short-drama dubbing, personalized digital humans, voice customer service, podcast/audiobook production, or localized private deployment, the quality, latency, VRAM usage, and cross-language capabilities of voice-clone TTS directly determine the user experience.
This article is a record of evaluating and comparing more than a dozen open-source TTS solutions in early 2025.
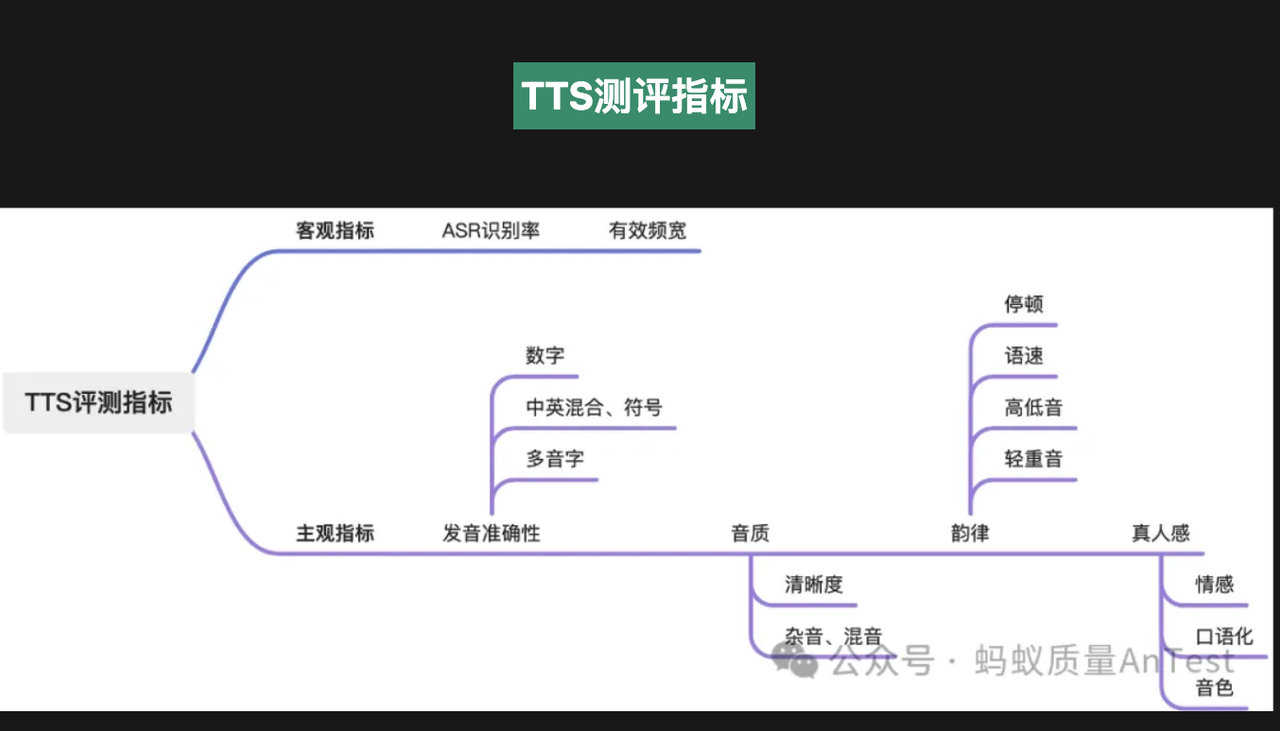
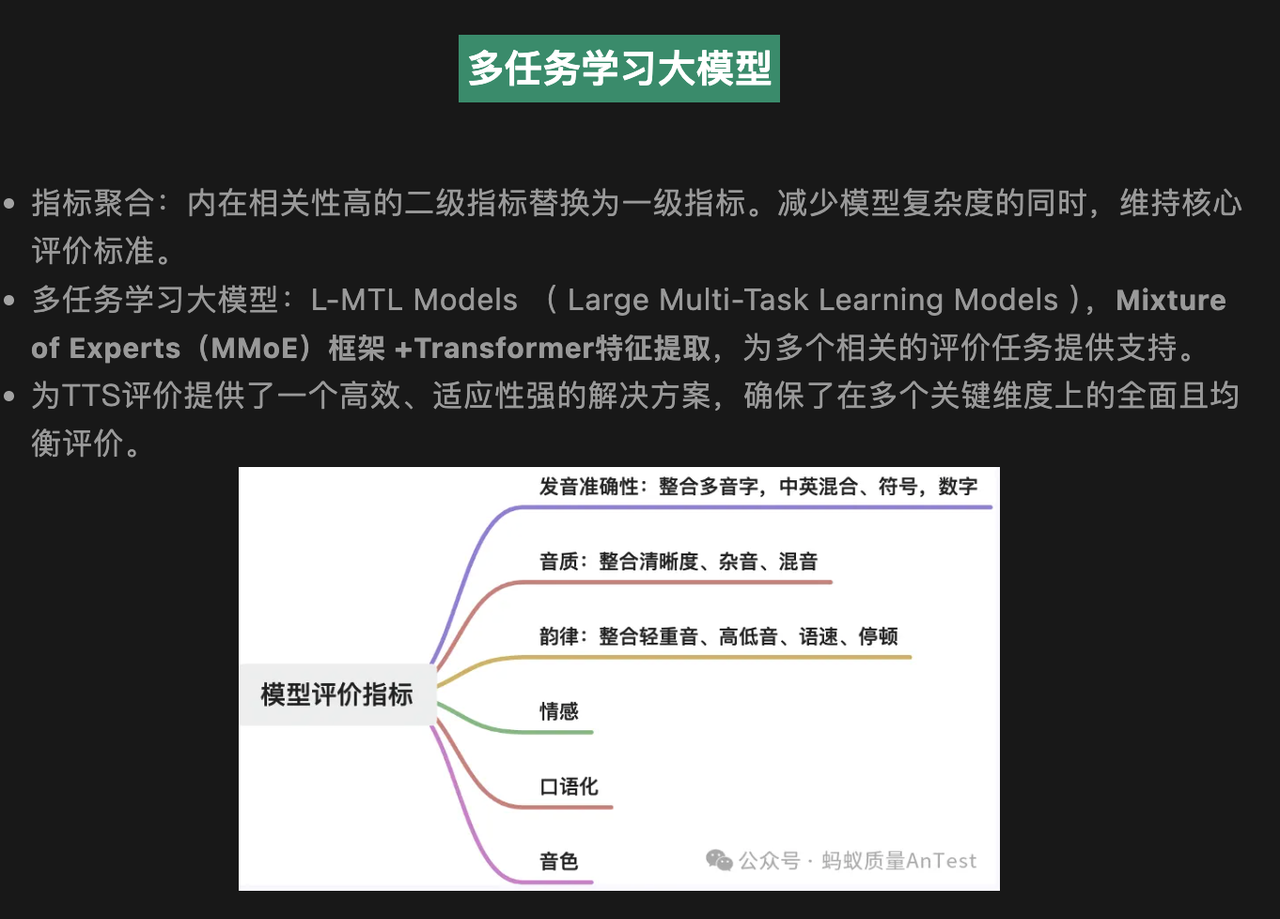
TTS Evaluation Survey (Basic Tools)
Before comparing specific models, here is a brief list of commonly used objective and subjective evaluation methods to help verify results.
TTS Evaluation Practices in the Era of Large-Model Voice Conversations
Link:QECon Tech Sharing – TTS Evaluation Practices in the Era of Large-Model Voice Conversations

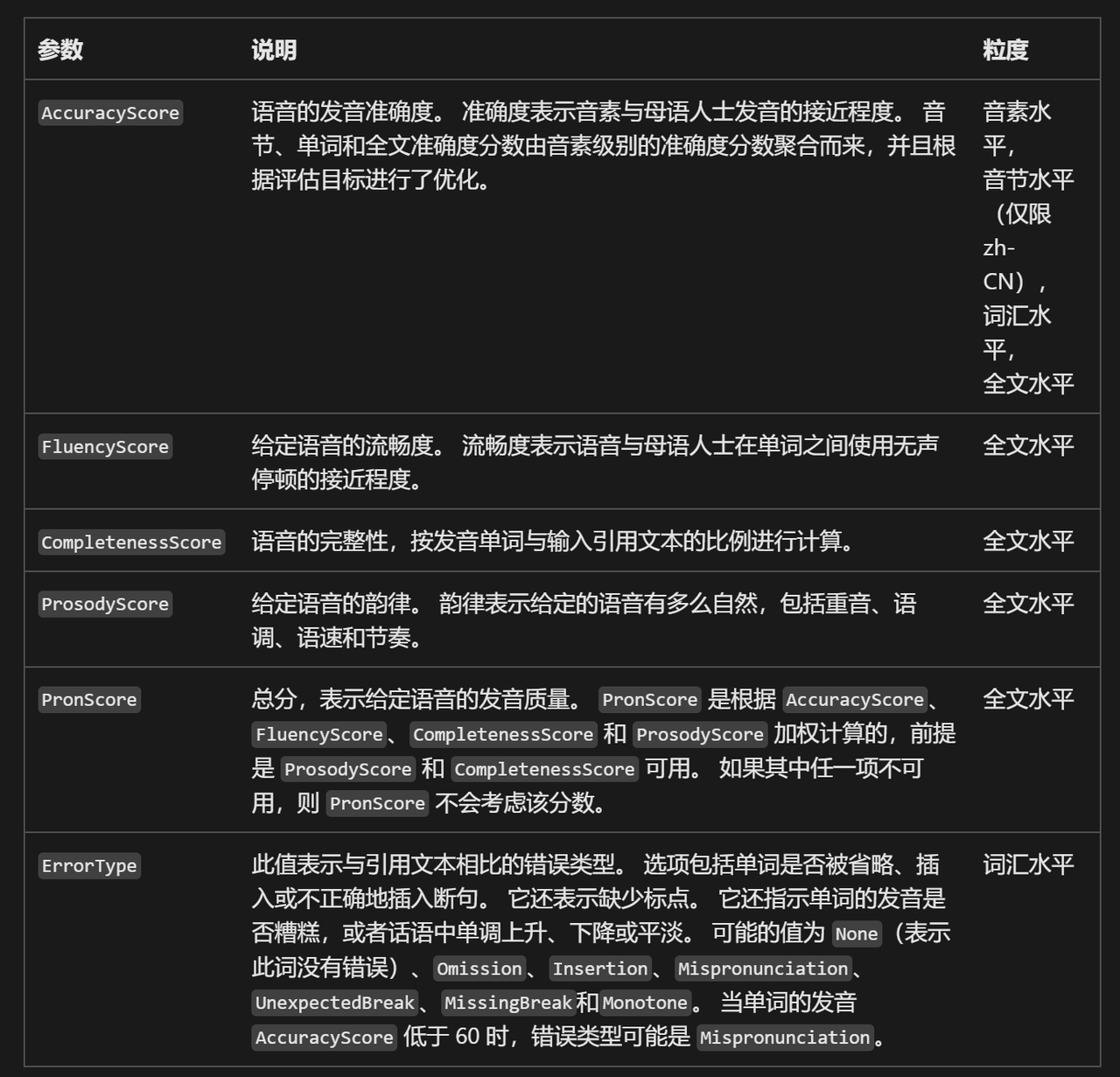
Microsoft Pronunciation Assessment Service
Link:Using Pronunciation Assessment
This introduces how to use Azure Speech Service’s pronunciation assessment feature to automatically evaluate user pronunciation through programming. It can analyze metrics such as accuracy, fluency, and completeness, and is suitable for language learning, speech training, and similar scenarios.
seed-tts-eval (Most Commonly Used Objective Metrics)
Link:https://github.com/BytedanceSpeech/seed-tts-eval
This is used for the most basic evaluations. Almost every TTS model paper provides these two metrics:
Word Error Rate(WER)and Speaker Similarity(SIM)。
- For WER, Whisper-large-v3 is used for English and Paraformer-zh for Chinese as the automatic speech recognition (ASR) engines.
- For speaker similarity, a WavLM-large model fine-tuned on speaker verification tasks is used to extract speaker embeddings, and cosine similarity is calculated between each test speech sample and the reference speech sample.
Mainstream Open-Source Voice Clone TTS Solutions
F5-TTS
Introduction
Official repo:https://github.com/SWivid/F5-TTS
F5-TTS is an open-source text-to-speech (TTS) system jointly developed by Shanghai Jiao Tong University, the University of Cambridge, and Geely Auto Research Institute. Its core innovation lies in combining a non-autoregressive generation framework with Flow Matching technology to achieve efficient and high-quality speech synthesis. The project is based on the Diffusion Transformer (DiT) and ConvNeXt V2 architecture. By optimizing the generation path with Flow Matching, it significantly improves the naturalness and generation speed of speech, with inference efficiency several times higher than traditional autoregressive models.
Key technical highlights include:
- Non-autoregressive parallel generation: Uses parallel data processing to break the traditional frame-by-frame generation limitation, supporting fast synthesis of long text (over 30 seconds of speech) while reducing VRAM usage.
- Zero-shot voice cloning: No training data from the target speaker is required; only a reference audio clip under 15 seconds is needed to replicate the speaker’s timbre, supporting multi-role voice switching.
- Multi-modal control capabilities: Integrated emotion expression adjustment and speech rate control modules that can dynamically adjust emotional intensity and rhythm based on text semantics.
- Multi-language and robustness: Trained on a 100,000-hour mixed Chinese-English dataset, it has cross-language synthesis capabilities and can effectively handle complex punctuation and special symbols (e.g., automatic conversion of Chinese colons).
Demo
Online demo:https://huggingface.co/spaces/mrfakename/E2-F5-TTS
CosyVoice
Introduction
Official repo:https://github.com/FunAudioLLM/CosyVoice
CosyVoice is an open-source speech synthesis large model developed by Alibaba’s Tongyi Lab, focusing on high-fidelity speech generation in natural language interaction scenarios. The project is based on supervised discrete speech token technology and deeply integrates multi-language support, timbre cloning, and emotion control. Its architecture supports unified offline and streaming modeling.
Core highlights include:
- Timbre cloning can be completed with only a 3-second audio sample (base model CosyVoice-300M), supporting cross-language synthesis in Chinese, English, Japanese, Cantonese, etc.
- Fine-grained control of prosody and emotion through rich text or natural language instructions (Instruct model version).
- Significant improvements in pronunciation accuracy and stability compared to previous generations, with a MOS score of 5.53, approaching commercial product levels.
Demo
Online demo:https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
Step-Audio-TTS-3B
Introduction
Official repo:https://github.com/stepfun-ai/Step-Audio
StepFun (阶跃星辰) has open-sourced a 130B-parameter speech-text multimodal unified understanding and generation model: Step-Audio. Through its generative speech data engine, Step-Audio can perform high-quality voice cloning at lower cost. Using “distillation” technology, the model has been simplified into a lighter version — Step-Audio-TTS-3B — which has also been open-sourced, meaning anyone can use and improve it.
Step-Audio combines speech understanding and generation capabilities, providing a multimodal solution that effectively supports various speech interaction scenarios.
The model aims to address the limitations of existing open-source speech models in speech data collection, dynamic control, and intelligence.
- It is a single model that integrates speech recognition, semantic understanding, dialogue generation, voice cloning, audio editing, and speech synthesis. Through multimodal training, speech understanding and generation are seamlessly connected.
- The Step-Audio-Chat version has been open-sourced and supports high-quality dialogue generation.
- Through its generative speech data engine, Step-Audio eliminates the reliance of traditional TTS systems on manual speech data collection. It can generate high-quality speech data and, using its 130B-parameter model, has trained the resource-efficient Step-Audio-TTS-3B model with enhanced instruction-following capabilities.
Demo
Online demo:https://www.modelscope.cn/studios/Swarmeta_AI/Step-Audio-TTS-3B
Voice Cloning in ChatTTS-UI
Introduction
Official repo:https://github.com/jianchang512/clone-voice
The model used is xtts_v from coqui.ai.
ChatTTS-UI is an end-to-end toolchain that integrates voice cloning and video translation, supporting fully offline deployment. clone-voice is one of its voice cloning tools. It can take any human voice timbre, synthesize a given text into speech using that timbre, or convert one voice into another using the target timbre.
Demo
Demo download:https://pyvideotrans.com/
fish-speech
Introduction
Official repo:https://github.com/fishaudio/fish-speech
Fish Speech is a brand-new text-to-speech (TTS) solution developed by fishaudio. The current model was trained on approximately 150,000 hours of trilingual data and offers excellent support for Chinese. It can proficiently handle and generate speech in Chinese, Japanese, and English, with language processing capabilities approaching human levels and rich, varied voice expressions.
- DualAR architecture: Dual autoregressive Transformer design. The main Transformer runs at 21Hz, and the secondary Transformer converts latent states into acoustic features. Both computational efficiency and output quality are superior to traditional cascaded methods.
- Training data: 1 million hours of multilingual training data.
- High accuracy: English WER 3.5%, English CER 1.2%, Chinese CER 1.3%.
- Low latency: Voice cloning latency under 150 milliseconds.
- Strong generalization: Abandons traditional phoneme dependency and directly understands and processes text without relying on complex speech rule libraries.
Demo
Online demo:https://fish.audio/train/new-model/
OpenVoice
Introduction
OpenVoice is a free and open-source instant voice cloning project launched by MyShell AI. It can replicate the timbre of a reference speaker using only a short audio clip, while supporting multi-dimensional style control such as emotion, accent, and prosody. The project achieves zero-shot cross-language voice cloning without the need to collect large-scale speaker data for each language.
Technical highlights:
- Fine-grained style control (emotion, speech rate, pauses, etc.)
- Zero-shot cross-language cloning, greatly reducing data requirements
- High computational efficiency, suitable for large-scale deployment
Demo
Online demo:https://huggingface.co/spaces/myshell-ai/OpenVoice
Spark-TTS
Introduction
Spark-TTS is a new text-to-speech (TTS) system whose core is BiCodec — a single-stream speech codec. This codec decomposes speech into two complementary “speech tokens”: one is a low-bitrate semantic token used to capture linguistic content; the other is a fixed-length global token used to capture speaker attributes such as timbre, pitch, etc. This decoupled representation, combined with the powerful Qwen2.5 language model and a “Chain-of-Thought” (CoT) generation method, enables Spark-TTS to achieve control ranging from coarse-grained (e.g., gender, speaking style) to fine-grained (e.g., precise pitch values, speaking speed).
Sesame Conversational Speech Model (CSM) — “No AI Flavor”
Introduction
In the development of speech synthesis technology, one long-standing challenge is the “Uncanny Valley” effect.
When artificially synthesized speech approaches real human voices but still has subtle differences, humans feel strange or uncomfortable — this is known as the Uncanny Valley effect.
Sesame’s goal is to develop a speech model that crosses this Uncanny Valley, making users feel that interacting with AI voices is as natural as conversing with a real person. They introduced the concept of “Voice Presence”, which refers to the qualities in voice interaction that make people feel real, understood, and valued. They hope that through technological innovation, AI voices not only sound human but also resonate with users emotionally and contextually.
The three core elements for achieving “Voice Presence” are:
- Emotional Intelligence: The model needs to perceive and respond to the user’s tone, emotions, and conversational context. For example, when the user shows happiness or frustration, the AI can adjust its tone and content accordingly.
- Low Latency: To make conversations flow naturally, the AI’s response time must be extremely short, approaching the instantaneous reaction in human dialogue.
- Voice Quality: The voice must be realistic and expressive, avoiding a mechanical feel while retaining subtle intonation variations.
To achieve these goals, Sesame developed the Conversational Speech Model (CSM). The model adopts an end-to-end multimodal learning approach, using a Transformer architecture and combining conversational history to generate more natural and coherent speech output. Unlike traditional text-to-speech (TTS) models, CSM not only focuses on high-quality audio generation but also emphasizes real-time understanding and adaptation to context, thereby addressing the shortcomings of traditional models in diversity and situational adaptability.
Sesame has demonstrated its latest research results. They trained a speech model on approximately 1 million hours of public audio data, which exhibits astonishing capabilities in personality, memory, expressiveness, and appropriateness.
The speech synthesis quality in Sesame’s demo has already surpassed OpenAI’s Advanced Voice Mode.
Currently, it only supports English. It is said that the model will be open-sourced later.
Demo
Online demo:https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo
GPT-SoVITS (Dark Horse for Few-Shot Cloning in Chinese/Cantonese)
Introduction
GPT-SoVITS is a powerful few-shot voice conversion and speech synthesis tool.
Official repo:https://github.com/RVC-Boss/GPT-SoVITS
- Extremely low-barrier cloning: Zero-shot requires only 5 seconds of reference audio to synthesize (similarity 80%+); after 1 minute of few-shot fine-tuning, similarity can reach 95%+, even approaching commercial-grade levels.
- Supports five languages: Chinese, Japanese, English, Korean, and Cantonese, with strong cross-language synthesis capabilities (especially outstanding in Cantonese, often called the “Cantonese ceiling”).
- Extremely user-friendly WebUI with one-click training and inference; Windows integrated package runs with a double-click.
- Versions v3/v4 significantly improve zero-shot similarity, emotional expressiveness, and fine-tuning results; v4 fixes the “electronic sound” issue, and native 48k output is more transparent and less muffled.
- Fast inference speed (RTX 4090 RTF ≈ 0.014; RTX 4060 Ti can also run in real time), moderate VRAM usage (v2 Pro / v4 offer performance close to v3 but more resource-efficient).
- Active community ecosystem, often combined with RVC and ComfyUI plugins for dubbing, singing, real-time voice changing, and other scenarios.
Demo
Hugging Face official/community demo (high-speed inference):
https://huggingface.co/spaces/lj1995/GPT-SoVITS-ProPlus (or search for “GPT-SoVITS” to find the latest forks)
Summary
Among the solutions mentioned above, after testing, the one with the most comprehensive support, the most convenient for subsequent fine-tuning, and the best overall performance is the GPT-SoVITS solution.

Comments