
gpt-image-2玩了下,比之前玩过的那些图像大模型强多了,真的到可以以假乱真底部,感觉这样子进步下去,真真假假难以区分。 测试用例1: 提示词 [crayon-69e935bb4bb4f297431908/] 生成图像 测试用例2 提示词 [crayon-69e935bb4bb5b925257446/] 生成图像 在实际测试过程中,对比以前图像生成模型,一个比较明显的感受是,gpt-image-2 并不只是“更会画图”,而是对“结构化视觉信息”的理解能力更强。例如在快递面单、体检报告这类高密度排版场景中,它不仅能还原元素,还能较好地处理层级关系、信息分区以及视觉噪声(如折痕、模糊、打印质感)。这说明模型在训练中不仅学习了图像风格,还一定程度上学习了“版式语义”,这对于生成拟真文档类图像非常关键。 另外,从提示词设计角度来看,gpt-image-2 对“约束条件”的响应明显优于传统文生图模型。像“标注 Demo Label”“局部模糊”“可扫描风格条码”这类细粒度要求,如果表达清晰且结构合理,模型大概率可以正确执行。这意味着在使用时,与其堆砌形容词,不如将提示词拆成“内容 + 结构 + 视觉约束”三层,会更容易得到稳定且可控的结果。
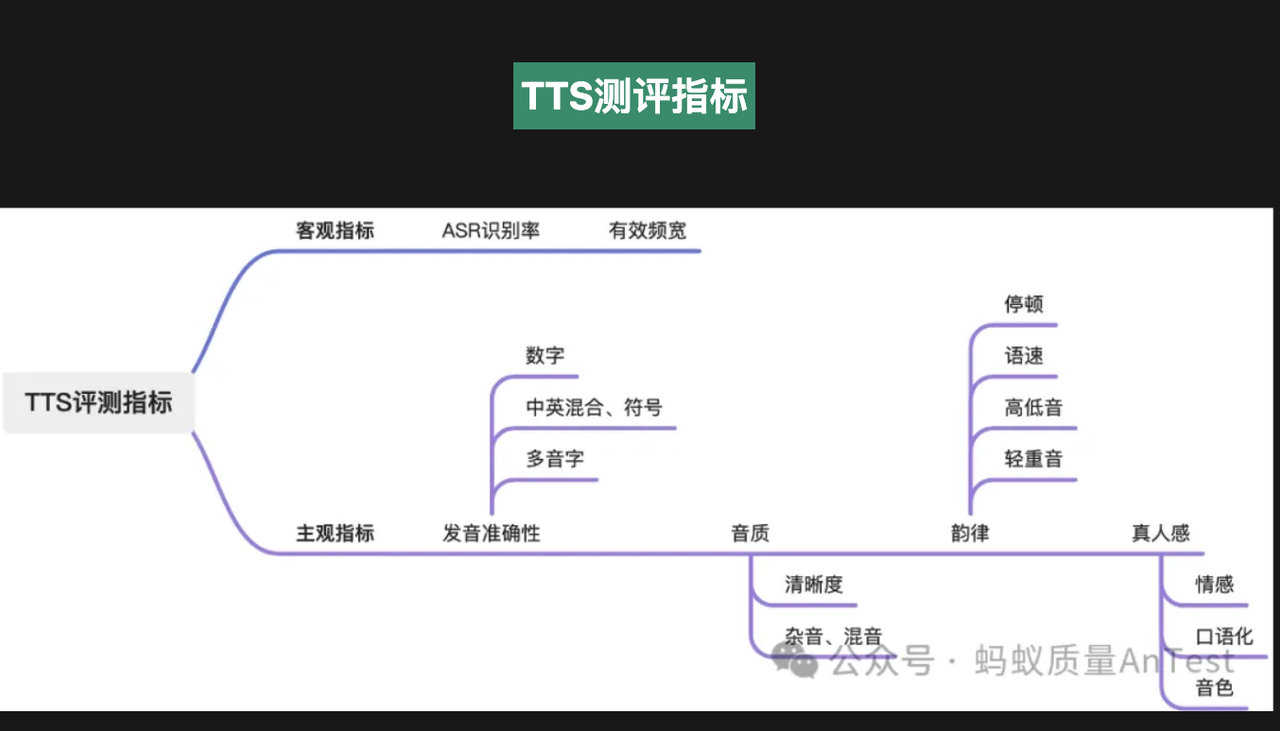
Preface With the arrival of the era of large-model voice conversations (ChatGPT-4o, Gemini Live, Doubao, etc.), high-naturalness, zero/few-shot voice cloning has become one of the core pain points for AI application deployment. Whether it’s AI short-drama dubbing, personalized digital humans, voice customer service, podcast/audiobook production, or localized private deployment, the quality, latency, VRAM usage, and cross-language capabilities of voice-clone TTS directly determine the user experience. This article is a record of evaluating and comparing more than a dozen open-source TTS solutions in early 2025. TTS Evaluation Survey (Basic Tools) Before comparing specific models, here is a brief list of commonly used objective and subjective evaluation methods to help verify results. TTS Evaluation Practices in the Era of Large-Model Voice Conversations Link:QECon Tech Sharing – TTS Evaluation Practices in the Era of Large-Model Voice Conversations Microsoft Pronunciation Assessment Service Link:Using Pronunciation Assessment This introduces how to use Azure Speech Service’s pronunciation assessment feature to automatically evaluate user pronunciation through programming. It can analyze metrics such as accuracy, fluency, and completeness, and is suitable for language learning, speech training, and similar scenarios. seed-tts-eval (Most Commonly Used Objective Metrics) Link:https://github.com/BytedanceSpeech/seed-tts-eval This is used for the most basic evaluations. Almost every TTS model paper provides these two metrics: Word Error Rate(WER)and Speaker Similarity(SIM)。 For WER, Whisper-large-v3 is used for English and Paraformer-zh for Chinese as the automatic speech recognition (ASR) engines. For speaker similarity, a WavLM-large model fine-tuned on speaker verification tasks is used to extract speaker embeddings, and cosine similarity is calculated between each test speech sample and the reference speech sample. Mainstream…
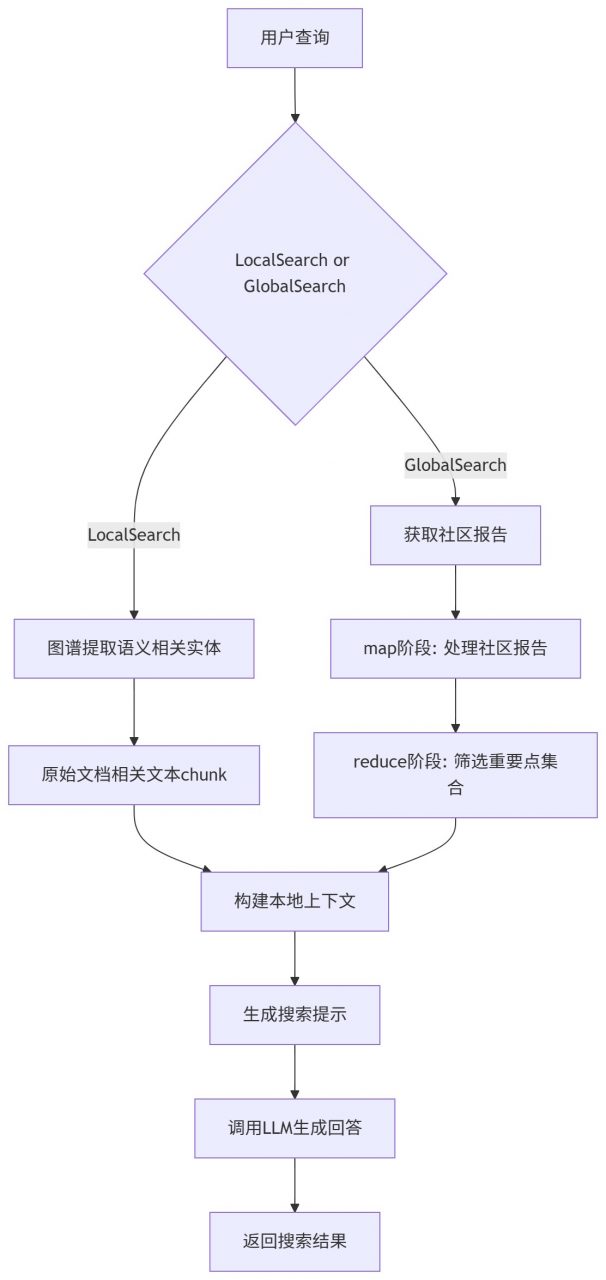
Conda 环境 [crayon-69e935bb4ce1f899626436/] Ollama配置 [crayon-69e935bb4ce29565730128/] 通过Ollama下载需要的大语言模型以及嵌入模型,这里用的阿里千问以及nomic。 [crayon-69e935bb4ce2d706611232/] 代码下载以及依赖安装 [crayon-69e935bb4ce30487813725/] 环境配置 创建一个目录用于存放输入的文本数据集,例如txt,csv文档。 [crayon-69e935bb4ce34189824159/] 初始化./ragtest目录用于生成默认环境配置文件。 [crayon-69e935bb4ce38936836376/] ./ragtest目录下settings.yaml为默认配置文件,配的是Chatgpt模型,由于我们通过Ollama使用本地大模型,所以需要修改配置,可以使用如下内容直接替换settings.yaml中的配置: [crayon-69e935bb4ce3c133874803/] 修改内容如下: [crayon-69e935bb4ce40046611211/] 配置文件参数说明参考:https://microsoft.github.io/graphrag/posts/config/json_yaml/ 提示词微调 在当前工作目录ragtest下,用于大模型提取实体以及关系等的提示词默认存放在prompts子目录下,可通过settings.yaml修改提示词目录。对于特定领域,默认提示词模板表现不佳。这里我们可以通过官方提供的方法进行提示词微调,替换默认提示词模板,从而提高在特定领域上的表现。 自动模板 可以通过配置domain,language等参数,生成符合我们要求的提示词模板,如下是针对某电影拍摄书籍的一个自动模板提示词微调示例。这样就会在prompt目录下生成新的提示词模板,更符合拍摄领域。 [crayon-69e935bb4ce46231943233/] 详细参数配置可以参考:https://microsoft.github.io/graphrag/posts/prompt_tuning/auto_prompt_tuning/ 手动提示词微调 按照规范自己写一个提示词模板,参考:https://microsoft.github.io/graphrag/posts/prompt_tuning/manual_prompt_tuning/ 执行索引 这一步会通过大模型提取实体,关系等,构建知识图谱,耗时较久。 [crayon-69e935bb4ce49191355625/] 搜索 索引阶段提取的结构被用来提供材料,作为LLM的context来回答问题。查询模式包括本地和全局的搜索: 本地搜索:通过图谱中实体关联信息和原始文档相关文本块来推理关于特定实体的问题 全局搜索:通过社区的总结来推理关于语料库整体问题的答案 本地搜索 [crayon-69e935bb4ce4c351214914/] 全局搜索 [crayon-69e935bb4ce4f157801120/] 参考 [1] https://microsoft.github.io/graphrag/posts/query/overview/
Recent Comments
Miles0u Published at 8 hours ago(04 04202643009 22 22pm26)
Addiea9 Published at 2 weeks ago(04 04202643001 08 08am26)
snail Published at 4 weeks ago(03 03202633105 27 27pm26)
dongxuh Published at 9 months ago(07 07202573103 27 27pm25)
南南 Published at 9 months ago(07 07202573103 15 15pm25)