Conda 环境
|
1 2 |
conda create -n graphrag-local python=3.10 #Python 3.10-3.12 conda activate graphrag-local |
Ollama配置
|
1 2 |
curl -fsSL https://ollama.com/install.sh | sh #ollama for linux pip install ollama |
通过Ollama下载需要的大语言模型以及嵌入模型,这里用的阿里千问以及nomic。
|
1 2 |
ollama pull qwen:7b #llm ollama pull nomic-embed-text #embedding |
代码下载以及依赖安装
|
1 2 3 |
git clone https://github.com/microsoft/graphrag.git cd graphrag pip install -e . |
环境配置
创建一个目录用于存放输入的文本数据集,例如txt,csv文档。
|
1 |
mkdir -p ./ragtest/input |
初始化./ragtest目录用于生成默认环境配置文件。
|
1 |
python -m graphrag.index --init --root ./ragtest |
./ragtest目录下settings.yaml为默认配置文件,配的是Chatgpt模型,由于我们通过Ollama使用本地大模型,所以需要修改配置,可以使用如下内容直接替换settings.yaml中的配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 |
encoding_model: cl100k_base skip_workflows: [] llm: api_key: ${GRAPHRAG_API_KEY} type: openai_chat # or azure_openai_chat model: qwen2:7b-instruct model_supports_json: true # recommended if this is available for your model. # max_tokens: 4000 # request_timeout: 180.0 api_base: http://127.0.0.1:11434/v1 # api_version: 2024-02-15-preview # organization: # deployment_name: # tokens_per_minute: 150_000 # set a leaky bucket throttle # requests_per_minute: 10_000 # set a leaky bucket throttle # max_retries: 10 # max_retry_wait: 10.0 # sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times # concurrent_requests: 25 # the number of parallel inflight requests that may be made # temperature: 0 # temperature for sampling # top_p: 1 # top-p sampling # n: 1 # Number of completions to generate parallelization: stagger: 0.3 # num_threads: 50 # the number of threads to use for parallel processing async_mode: threaded # or asyncio embeddings: ## parallelization: override the global parallelization settings for embeddings async_mode: threaded # or asyncio llm: api_key: ${GRAPHRAG_API_KEY} type: openai_embedding # or azure_openai_embedding model: nomic-embed-text api_base: http://127.0.0.1:11434/v1 # api_version: 2024-02-15-preview # organization: # deployment_name: # tokens_per_minute: 150_000 # set a leaky bucket throttle # requests_per_minute: 10_000 # set a leaky bucket throttle # max_retries: 10 # max_retry_wait: 10.0 # sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times # concurrent_requests: 25 # the number of parallel inflight requests that may be made # batch_size: 16 # the number of documents to send in a single request # batch_max_tokens: 8191 # the maximum number of tokens to send in a single request # target: required # or optional chunks: size: 300 overlap: 100 group_by_columns: [id] # by default, we don't allow chunks to cross documents input: type: file # or blob file_type: text # or csv base_dir: "input" file_encoding: utf-8 file_pattern: ".*\\.txt$" cache: type: file # or blob base_dir: "cache" # connection_string: # container_name: storage: type: file # or blob base_dir: "output/${timestamp}/artifacts" # connection_string: # container_name: reporting: type: file # or console, blob base_dir: "output/${timestamp}/reports" # connection_string: # container_name: entity_extraction: ## llm: override the global llm settings for this task ## parallelization: override the global parallelization settings for this task ## async_mode: override the global async_mode settings for this task prompt: "prompts/entity_extraction.txt" entity_types: [organization,person,geo,event] max_gleanings: 0 summarize_descriptions: ## llm: override the global llm settings for this task ## parallelization: override the global parallelization settings for this task ## async_mode: override the global async_mode settings for this task prompt: "prompts/summarize_descriptions.txt" max_length: 500 claim_extraction: ## llm: override the global llm settings for this task ## parallelization: override the global parallelization settings for this task ## async_mode: override the global async_mode settings for this task # enabled: true prompt: "prompts/claim_extraction.txt" description: "Any claims or facts that could be relevant to information discovery." max_gleanings: 0 community_report: ## llm: override the global llm settings for this task ## parallelization: override the global parallelization settings for this task ## async_mode: override the global async_mode settings for this task prompt: "prompts/community_report.txt" max_length: 2000 max_input_length: 8000 cluster_graph: max_cluster_size: 10 embed_graph: enabled: false # if true, will generate node2vec embeddings for nodes # num_walks: 10 # walk_length: 40 # window_size: 2 # iterations: 3 # random_seed: 597832 umap: enabled: false # if true, will generate UMAP embeddings for nodes snapshots: graphml: yes raw_entities: yes top_level_nodes: yes local_search: # text_unit_prop: 0.5 # community_prop: 0.1 # conversation_history_max_turns: 5 # top_k_mapped_entities: 10 # top_k_relationships: 10 # llm_temperature: 0 # temperature for sampling # llm_top_p: 1 # top-p sampling # llm_n: 1 # Number of completions to generate # max_tokens: 12000 global_search: # llm_temperature: 0 # temperature for sampling # llm_top_p: 1 # top-p sampling # llm_n: 1 # Number of completions to generate # max_tokens: 12000 # data_max_tokens: 12000 # map_max_tokens: 1000 # reduce_max_tokens: 2000 # concurrency: 32 |
修改内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
diff --git a/settings.yaml b/settings.yaml index 0a7f255..ffb4fbe 100644 --- a/settings.yaml +++ b/settings.yaml @@ -4,11 +4,11 @@ skip_workflows: [] llm: api_key: ${GRAPHRAG_API_KEY} type: openai_chat # or azure_openai_chat - model: gpt-4-turbo-preview + model: qwen2:7b-instruct model_supports_json: true # recommended if this is available for your model. # max_tokens: 4000 # request_timeout: 180.0 - # api_base: https://.openai.azure.com + api_base: http://127.0.0.1:11434/v1 # api_version: 2024-02-15-preview # organization: # deployment_name: @@ -34,8 +34,8 @@ embeddings: llm: api_key: ${GRAPHRAG_API_KEY} type: openai_embedding # or azure_openai_embedding - model: text-embedding-3-small - # api_base: https://.openai.azure.com + model: nomic-embed-text + api_base: http://127.0.0.1:11434/v1 # api_version: 2024-02-15-preview # organization: # deployment_name: @@ -52,7 +52,7 @@ embeddings: chunks: - size: 1200 + size: 300 overlap: 100 group_by_columns: [id] # by default, we don't allow chunks to cross documents @@ -87,7 +87,7 @@ entity_extraction: ## async_mode: override the global async_mode settings for this task prompt: "prompts/entity_extraction.txt" entity_types: [organization,person,geo,event] - max_gleanings: 1 + max_gleanings: 0 summarize_descriptions: ## llm: override the global llm settings for this task @@ -103,9 +103,9 @@ claim_extraction: # enabled: true prompt: "prompts/claim_extraction.txt" description: "Any claims or facts that could be relevant to information discovery." - max_gleanings: 1 + max_gleanings: 0 -community_reports: +community_report: ## llm: override the global llm settings for this task ## parallelization: override the global parallelization settings for this task ## async_mode: override the global async_mode settings for this task @@ -128,9 +128,9 @@ umap: enabled: false # if true, will generate UMAP embeddings for nodes snapshots: - graphml: false - raw_entities: false - top_level_nodes: false + graphml: yes + raw_entities: yes + top_level_nodes: yes local_search: # text_unit_prop: 0.5 |
配置文件参数说明参考:https://microsoft.github.io/graphrag/posts/config/json_yaml/
提示词微调
在当前工作目录ragtest下,用于大模型提取实体以及关系等的提示词默认存放在prompts子目录下,可通过settings.yaml修改提示词目录。对于特定领域,默认提示词模板表现不佳。这里我们可以通过官方提供的方法进行提示词微调,替换默认提示词模板,从而提高在特定领域上的表现。
自动模板
可以通过配置domain,language等参数,生成符合我们要求的提示词模板,如下是针对某电影拍摄书籍的一个自动模板提示词微调示例。这样就会在prompt目录下生成新的提示词模板,更符合拍摄领域。
|
1 |
python -m graphrag.prompt_tune --config CONFIG --root ./ragtest --domain "a book about how to shoot a film" --language Chinese --chunk-size 300 --output prompt |
详细参数配置可以参考:https://microsoft.github.io/graphrag/posts/prompt_tuning/auto_prompt_tuning/
手动提示词微调
按照规范自己写一个提示词模板,参考:https://microsoft.github.io/graphrag/posts/prompt_tuning/manual_prompt_tuning/
执行索引
这一步会通过大模型提取实体,关系等,构建知识图谱,耗时较久。
|
1 |
python -m graphrag.index --root ./ragtest |
搜索
索引阶段提取的结构被用来提供材料,作为LLM的context来回答问题。查询模式包括本地和全局的搜索:
- 本地搜索:通过图谱中实体关联信息和原始文档相关文本块来推理关于特定实体的问题
- 全局搜索:通过社区的总结来推理关于语料库整体问题的答案
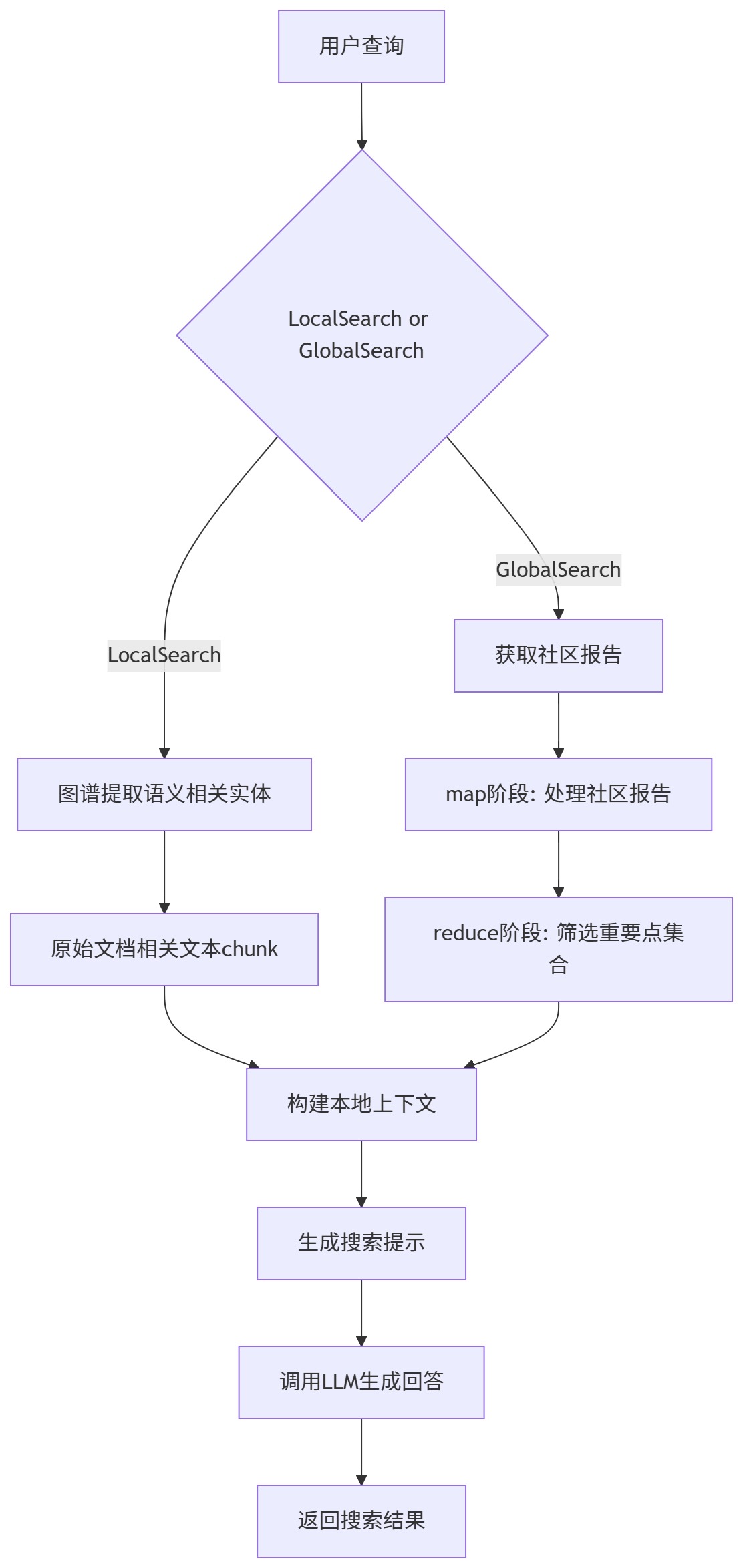
本地搜索
|
1 |
python -m graphrag.query --root ./ragtest --method local "test test" |
全局搜索
|
1 |
python -m graphrag.query --root ./ragtest --method global "test test" |
参考
[1] https://microsoft.github.io/graphrag/posts/query/overview/

Comments