
Google C++ Style Guide的官方完整文本可在GitHub博客上获取。由于从事WebRTC开发,所以代码规范遵循这个,个人觉得很简洁紧凑,还好看。 如下图片是该代码规范的总结图,收藏用:

今天是6月8号,转眼高考过去十年了,今年因为疫情,高考推迟到7月。十年前的选择真的是改变了命运,选择了感兴趣的计算机类专业,工作后也一直从事感兴趣的方向,现在的自己真要感谢过去十年努力的自己。点一首陈奕迅的《十年》送给自己,希望下一个十年依旧精彩。

之前有个网友问基于时延的带宽预测代码中如下时间转换什么含义: [crayon-69ea46a9175cb048149377/] 那时因为工作比较忙,没去细看,没回答上。最近重新看了下这个问题,我想现在应该能回答上了(现在看起来其实很简单)。所以本文分析下如上时间转换代码为什么这么写。 绝对发送时间 在WebRTC使用绝对发送时间(Absolute Send Time)记录RTP包发送出去的时间。在GCC拥塞控制中的带宽预测,通过这个发送时间,以及包接收时间,计算带宽增长趋势。在基于接收端的带宽预测中,会在RTP包报头扩展中记录这个发送时间,从而在接收端进行带宽预测计算。在基于发送端的带宽预测中,这个发送时间由发送端另外记录。 WebRTC中使用3字节标识这个绝对发送时间,单位为秒。其中使用6bit标识整数部分,18bit标识小数部分。 保留N位小数 这里我们讲下如何进行N位小数的保留,知道后前面的代码就非常easy了。 假设我们有一个十进制数256.2562要处理,但是程序中某函数小数点取值范围只有0~100,也就是0~10^2,所以我们要对256.256进行保留小数点后两位的处理。一般这么处理:(256.2562x10^2+0.5)/10^2=256.26,+0.5操作是为了对保留的最后一位小数进行四舍五入。 代码导读 看完前面我想代码就很好理解了,只不过现在换成处理二进制数了,这里再贴下代码: [crayon-69ea46a9175d7738467085/] 首先获取以ms为单位的发送时间send_time.ms,大小为64bit 左移kAbsSendTimeFraction(18)bit,也就是乘以2^18,因为绝对发送时间使用18bit标识小数部分,所以需要进行小数点后有效数字的保留 除以1000将时间单位转换为s,加500是为了四舍五入操作 接着&0x00FFFFFF得到后24bit时间值 send_time_24bits左移kAbsSendTimeInterArrivalUpshift(8bit),得到32bit大小的发送时间timestamp 是不是很简单,其实就是个简单的数学处理。所以为了学好WebRTC很多基本的数学处理还是不能忘的。 本文已收录到大话WebRTC专栏,更多精彩请访问《大话WebRTC》。
整理归纳写过的WebRTC系列研究文章。本系列文章专注WebRTC底层技术研究。 版权声明:本系列文章全部原创。欢迎指正文章中的错误。 基础入门 音视频开发入门:音频基础 音视频开发入门:视频基础 WebRTC音视频传输基础:NAT穿透 基础概念 WebRTC研究:MediaStream概念以及定义 Webrtc Glossary:查阅各种WebRTC相关概念 开始放弃。。。 编译 Windows平台WebRTC编译(持续更新) Windows平台WebRTC编译-VS2017 Linux平台WebRTC编译 WebRTC安卓编译 Mac平台WebRTC编译 网络参数 WebRTC研究:统计参数之丢包率 WebRTC研究:统计参数之抖动 WebRTC研究:统计参数之往返时延 WebRTC研究:码率计算 RTP/RTCP WebRTC研究:Transport-cc之RTP及RTCP(TransportFeedback) WebRTC研究:关键帧请求(PLI以及FIR) WebRTC研究:FEC之RED封装 WebRTC研究:RTP报头扩展 WebRTC研究:RTP时间戳的产生 WebRTC研究:Audio level WebRTC研究:H264 RTP包解析 WebRTC研究:H264 RTP包封装 WebRTC研究:RTP包组帧 QoS/QoE优化 WebRTC研究:RTP中的序列号以及时间戳比较 WebRTC研究:丢包判断 WebRTC研究:丢包重传机制-NACK WebRTC研究:视频FEC编码 WebRTC研究:视频FEC解码 WebRTC研究:NACK与FEC机制的配合 WebRTC研究:流畅模式与清晰模式 WebRTC研究:基于卡尔曼滤波的抖动估计 WebRTC研究:音频带内FEC WebRTC研究:基于Transport Feedback的早期丢包检测 浅谈基于SFU实现一对一效果 拥塞控制 WebRTC研究:包组时间差计算-InterArrival WebRTC研究:Trendline滤波器-TrendlineEstimator WebRTC研究:码率控制器-AimdRateControl WebRTC研究:应用受限区域探测器-AlrDetector WebRTC研究:DelayBasedBwe中绝对发送时间转换 WebRTC研究:带宽估计中的稳定估计值 WebRTC研究:Pacing机制 音视频引擎 WebRTC研究:Simulcast层数变化 WebRTC研究:Encoded Transform 基础库 WebRTC研究:线程模型 常见开源SFU源码分析 Licode研究:Pipeline架构 茶余饭后闲谈 WebRTC研究:WebRTC M89关键更新 WebRTC研究:记一次音频带宽估计引入的异常分析 小技巧 Chrome查看WebRTC日志 常用RFC RFC3550.RTP:A Transport Protocol for Real-Time Applications RFC2198.RTP Payload for Redundant Audio Data RFC5109.RTP Payload Format for Generic Forward Error Correction RFC5104.Codec Control Messages in the RTP Audio-Visual Profile with Feedback (AVPF) RFC5285.A General Mechanism for RTP Header Extensions RFC8285.A General Mechanism for RTP Header Extensions RFC3984.RTP Payload Format for H.264 Video A Google Congestion Control Algorithm for Real-Time Communication draft-ietf-rmcat-gcc-02 RFC4585.Extended RTP Profile for Real-time Transport Control Protocol (RTCP)-Based Feedback (RTP/AVPF) Transport CC.RTP Extensions for Transport-wide Congestion Control draft-holmer-rmcat-transport-wide-cc-extensions-01
很多时候Native应用调用WebRTC C++接口时需要查看底层详细日志,目前有两种方法: 编译Debug版本Webrtc 在应用程序入口(例如构造函数中)调用rtc::LogMessage::LogToDebug(rtc::LS_INFO); 对于Windows以及Linux应用,日志将输出到stderr。
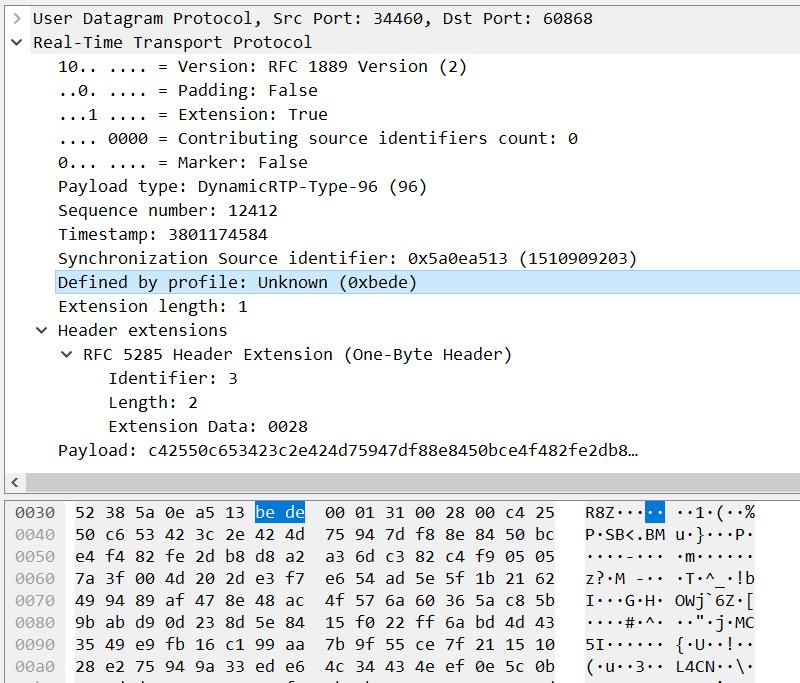
Transport-cc指的是Transport-wide Congestion Control。WebRTC最新的拥塞控制算法(Sendside BWE)基于Transport-cc,接收端记录数据包到达时间,构造相关RTCP包,然后反馈给发送端,在发送端做带宽估计,从而进行拥塞控制。之所以基于Transport-cc,放到发送端进行带宽估计,除了方便维护,也增加了相关算法的灵活性,因为大多数处理逻辑都放到了发送端。WebRTC中为了使用Transport-cc,需要RTP报头扩展以及相关RTCP的配套支持。这里我们介绍下支撑Transport-cc的RTP以及RTCP。 RTP Header扩展 Transport sequence number 首先我们先来复习下RTP固定报头结构: [crayon-69ea46a919714031396475/] 可以看到有一个sequence number字段,用于记录RTP包的序列号。一般情况下我们一个传输通道(PeerConnection)只包含一路视频流,这个sequence number能满足大多数需求。但是在一些情况下,我们一个连接可能传输多个视频流,这些视频流复用一个传输通道,例如simulcast或者single PC场景,一个PeerConnection可能包含多个不同的视频流。在这些视频流中,RTP报头的sequence number是单独计数的。 这里举个例子,假设同一个PeerConnection下,我们传输两个视频流A与B,它们的RTP包记为Ra(n),Rb(n),n表示sequence number,这样我们观察同一个PeerConnection下,视频流按如下形式传输: Ra(1),Ra(2),Rb(1),Rb(2),Ra(3),Ra(4),Rb(3),Rb(4) 在对某条PeerConnection进行带宽估计时,我们需要估计整条PeerConnection下所有视频流,而不是单独某个流。这样为了做一个RTP session(传输层)级别的带宽估计,原有各个流的sequence number就不能满足我们需要了。 为此Transport-cc中,使用了RTP报头扩展,用于记录transport sequence number,同一个PeerConnection连接下的所有流的transport sequence number,使用统一的计数器进行计数,方便进行同一个PeerConnection下的带宽估计。 这里我们使用前面的例子,视频流A与B,它们的RTP包记为Ra(n,m),Rb(n,m),n表示sequence number,m表示transport sequence number,这样同一个PeerConnection下,视频流按如下形式传输: Ra(1,1),Ra(2,2),Rb(1,3),Rb(2,4),Ra(3,5),Ra(4,6),Rb(3,7),Rb(4,8) 这样进行带宽估计时,通过transport sequence number我们就能关心到这条传输通道下所有数据包的情况了。 RTP transport sequence number报头定义如下: [crayon-69ea46a91971e069031421/] 由于属于RTP报头扩展,所以可以看到以0xBEDE固定字段开头,表示One-Byte Header类型的扩展。 One-Byte Header相关知识请参考:WebRTC研究:RTP报头扩展 transport sequence number占两个字节,存储在One-Byte Header的Extension data字段。由于按4字节对齐,所以还有值为0的填充数据。 对于同一个PeerConnection下的每个包,这个transport sequence number是从1开始递增的。这里我们看下Wireshark中对带transport sequence numberRTP报头扩展的解析: One-Byte Header中Extension data字段为0x0028,可知该RTP包的transport sequence number为0x0028。 代码导读 WebRTC中,要发送的数据都会经过Pacing模块,用于平滑发送处理,要发送数据会送到pacer thread,在pacer thread中的PacketRouter::SendPacket,对要发送的RTP数据包打上统一计数的TransportSequenceNumber扩展。 [crayon-69ea46a919723892532139/] TransportFeedback RTCP 允许接收端向发送端传递有关媒体流传输质量的信息,包括到达时间,丢包信息。 报文格式 Transport-cc中,收流客户端通过TransportFeedback RTCP向发送端反馈收到的各个RTP包的到达时间,丢包信息。首先我们看下TransportFeedback包格式定义: [crayon-69ea46a919727871878711/] FMT:5bits。Feedback message type(FMT)固定为15 PT:8bits。由于属于传输层的Feedback Messages,所以payload type(PT)为205 base sequence number:2字节,TransportFeedback包中记录的第一个RTP包的transport sequence number,在反馈的各个TransportFeedback RTCP包中,这个字段不一定是递增的,也有可能比之前的RTCP包小 packet status count:2字节,表示这个TransportFeedback包记录了多少个RTP包信息,这些RTP的transport sequence number以base sequence number为基准 ,比如记录的第一个RTP包的transport sequence number为base sequence number,那么记录的第二个RTP包transport sequence number为base sequence number+1 reference time:3字节,表示参考时间,以64ms为单位,RTCP包记录的RTP包到达时间信息以这个reference time为基准进行计算 feedback packet count:1字节,用于计数发送的每个TransportFeedback包,相当于RTCP包的序列号。可用于检测TransportFeedback包的丢包情况 packet chunk:2字节,记录RTP包的到达状态,记录的这些RTP包transport sequence number通过base sequence number计算得到 recv delta: 8bits,对于"packet received"状态的包,也就是收到的RTP包,在recv delta列表中添加对应的的到达时间间隔信息,用于记录RTP包到达时间信息。通过前面的reference time以及recv delta信息,我们就可以得到RTP包到达时间 packet chunk 首先先了解下RTP包状态,目前定义了如下四种状态,每个状态值2bits,用来标识RTP包的到达状态,以及与前面RTP包的时间间隔大小信息: 00-Packet not received 01-Packet received, small delta 10-Packet received, large or negative delta 11-[Reserved] packet chunk有两种类型,Run length chunk(行程长度编码数据块)与Status vector chunk(状态矢量编码数据块),对应packet chunk结构的两种编码方式。packet chunk的第一bit标识chunk类型。 Run length chunk 这里先来了解下Run length(行程长度)编码。Run length编码是一种简单的数据压缩算法,其基本思想是将重复且连续出现多次的字符使用“连续出现次数+字符”来描述,例如:aaabbbcdddd通过Run length编码就可以压缩为3a3bc4d。Run length chunk中就使用了Run length编码标识连续多个相同状态的包。 Run length chunk第一bit为0,后面跟着packet status以及run length。格式如下: [crayon-69ea46a91972a192258677/] chunk type (T):1 bit,值为0 packet status symbol (S):2 bits,标识包状态 run length (L):13 bits,行程长度,标识有多少个连续包为相同状态 下面举例子说明下。 [crayon-69ea46a91972e263346507/] packet status为00,由前面包状态可知为"Packet not received"状态,run lengh为221(11011101),说明连续有221个包为"Packet not received"状态。 Status Vector Chunk 第一bit为1,后面跟着symbol size以及symbol list。格式如下: [crayon-69ea46a919731894131862/] chunk type (T):1 bit,值为1 symbol size(S):1 bit,为0表示只包含"packet not received" (0)以及"packet received"(1)状态,每个状态使用1bit表示,这样后面14bits的symbol list能标识14个包的状态。为1表示使用2bits来标识包状态,这样symbol list中我们只能标识7个包的状态 symbol list:14 bits,标识一系列包的状态, 总共能标识7或14个包的状态 下面举例子说明下。 例子1: [crayon-69ea46a919735000807804/] symbol size为0,这样能标识14个包的状态。第一个包状态为"packet not received"(0),接着后面5个包状态为"packet received"(1),再接着三个包状态为"packet not received",再接着三个包状态为"packet received",最后两个包状态为"packet not received"。 例子2: [crayon-69ea46a919738924955254/] symbol size为1,这样只能标识7个包的状态。第一个包为"packet not received"(00)状态,第二个包为 "packet received, w/o timestamp"(11)状态,再接着三个包为"packet received"(01)状态,最后两个包为"packet not received"(00)状态。 Receive Delta 以250us(0.25ms)为单位,表示RTP包到达时间与前面一个RTP包到达时间的间隔,对于记录的第一个RTP包,该包的时间间隔是相对reference time的。 如果在packet chunk记录了一个"Packet received, small delta"状态的包,那么就会在receive delta列表中添加一个无符号1字节长度receive delta,无符号1字节取值范围[0,255],由于Receive Delta以0.25ms为单位,故此时Receive Delta取值范围[0, 63.75]ms 如果在packet chunk记录了一个"Packet received, large or negative delta"状态的包,那么就会在receive delta列表中添加一个有符号2字节长度的receive delta,范围[-8192.0, 8191.75] ms 如果时间间隔超过了最大限制,那么就会构建一个新的TransportFeedback RTCP包,由于reference time长度为3字节,所以目前的包中3字节长度能够覆盖很大范围了 以上说明总结起来就是:对于收到的RTP包在TransportFeedback…
今天周末稍微放松下,看了下最近很火的龙岭迷窟,由于是腾讯视频独家,所以打开了N年没碰过的腾讯视频,平常都是B站以及Youtube上的多。由于之前联通办了个王卡套餐,送了会员,所以选择1080P画质播放,可是没看多久,画面就出现我再熟悉不过的花屏马赛克了。 我想,这腾讯视频点播难道不是传统的基于TCP的RTMP或者HLS吗,怎么可能花屏,难道基于WebRTC?打开Wireshark看了下,全是加密的UDP数据包,然后打开浏览器的:chrome://webrtc-internals/,可以看到用的是WebRTC中的DataChannel,按这播放体验,应该是配置为不可靠传输了,具体我就不分析了。 没想到腾讯把WebRTC DataChannel不可靠配置那套用在传统的视频点播上,但是播放体验极差,弱网丢包严重的情况下,一直花屏,我调到最低分辨率才勉强能看。后来下了客户端看,虽然不花屏了,但是会卡,卡一会儿重新播放之前画面,之前画面循环播放了好几次,我想此时丢包太严重了,新的视频帧还没拼完整,只能一直重播之前缓存数据。 说实话在浏览器端,还是传统的基于TCP的点播方式好点,我宁愿缓冲界面,也不希望满屏的马赛克花屏。而且腾讯视频当前不能自动调整分辨率,下行这块没有带宽估计(这也是我目前的研究),花屏了得自己手动调整分辨率,对于普通用户来说,可能都不知道这满屏马赛克什么原因,也许还以为电脑出问题了,毕竟对普通用户的传统直觉来说,网络不行就应该是对应缓冲画面。
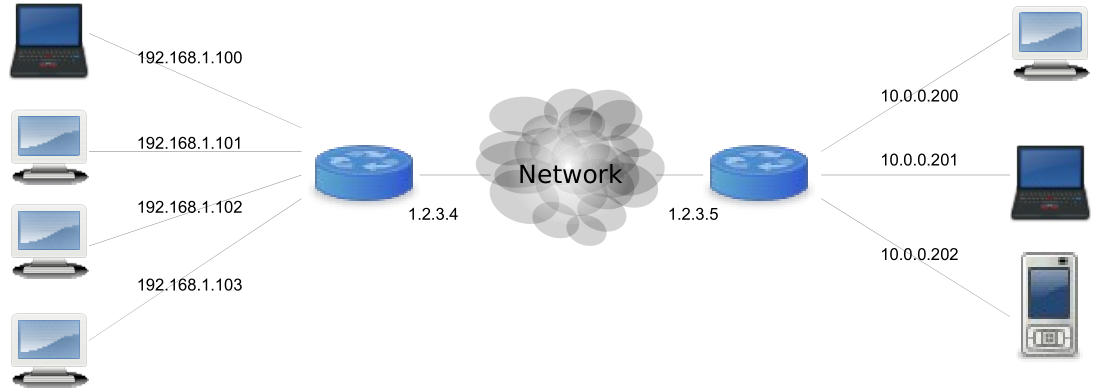
如今越来越多的音视频应用场景采用WebRTC技术,例如视频会议,在线教育,云游戏等。WebRTC包含一套强大的点对点(P2P)通信技术方案,用于音视频传输,本文我们来了解下背后的NAT穿透技术。 什么是NAT NAT(Network Address Translation)指的是网络地址转换,常部署在一个组织的网络出口位置。网络分为私网和公网两个部分,NAT网关设置在私网到公网的路由出口位置,私网与公网间的双向数据必须都要经过NAT网关。位于NAT后的是私网IP地址,分配给NAT的是公网IP地址。NAT通过将私网IP地址映射为公网IP地址,实现私网设备访问外部互联网的能力。组织内部的大量设备,通过NAT就可以共享一个公网IP地址,解决了IPv4地址不足的问题。同时NAT也起到隐藏内部设备,安全防护的作用。 如下图所示,有两个组织,每个组织的NAT分配一个公网IP,分别是1.2.3.4以及1.2.3.5。每个组织私网设备通过NAT将内网地址转换为公网地址,然后加入互联网。通过NAT每个私网设备就不必都需要分配公网IP了,就像图中,一个组织配一个公网IP即可。 NAT问题 虽然NAT解决了IPv4地址耗尽的问题,但是也存在一些问题。首先我们先说下不存在NAT时设备间点对点(P2P)通信情况: 1)位于同一个私网内,可以直接通过内网IP地址通信(例如192.168开头IP地址); 2)通信双方都有独立的公网IP地址,可以直接通过公网IP地址通信。 但是NAT的存在就不能这样处理了,增加了点对点通信的复杂度。如下图所示: 左边私网地址为192.168.1.100的设备要跟右边组织内的设备进行通信,由于右边组织多台设备共享一个公网IP,所以不能直接通过公网IP地址端口号进行通信,数据发过去了,根本不知道送到哪台设备,这样两个组织内的设备就不具有点对点通信的能力。既然这样,数据要怎么穿过NAT到达私网内,NAT网关要如何转发数据到指定设备呢? NAT穿透技术 现实生活中,大多数设备都位于NAT后。比如连着同一个基站的移动设备,同一个小区的宽带用户等。NAT的存在使得设备间不能直接进行点对点通信。有时候为了流量节省,以及安全等原因考虑,我们希望不同NAT后的设备也能进行点对点通信,不需要经过第三方的数据转发。为了进行设备间的点对点通信,我们需要使用相关技术检测设备间是否有点对点通信的可能性,以及如何进行点对点通信。这些相关技术就是NAT穿透(NAT traversal)。NAT穿透是为了解决使用了NAT后的私有网络中设备之间建立连接的问题。目前常见的NAT穿越技术、方法主要有: 应用层网关; 中间件技术; 打洞技术(Hole Punching); Relay(服务器中转)技术。 没有一种完美的NAT穿透,常常是多种技术互相配合,最常见的一种方案是打洞配合中转,例如后面说到的ICE方案。 NAT打洞技术 工作在传输层,最为常见。下面说下基本原理。 NAT网关维护着一张关联表,进行公网/私网地址端口的转换,结构如下所示: 私网IP 公网IP 192.168.1.100:5566 1.2.3.4:9200 192.168.1.101:80 1.2.3.4:9201 192.168.1.102:4465 1.2.3.4:9202 如下图,左边组织的公网IP为1.2.3.4NAT网关收到发到1.2.3.4:1234的数据,假如关联表中还未存在映射关系,NAT对外部发来的数据包直接丢掉。 所以网络访问只能先由私网侧发起,公网无法主动访问私网主机,既然这样,就由私网侧主动点。如下图: 私网地址10.0.0.100的设备发送数据包到公网。NAT网关关联表中创建了该设备私网地址:端口到公网地址:端口的映射,即上图中的10.0.0.100:1234到1.2.3.4:1234。这相当于在NAT上打了一个洞,其它人就可以通过这个“洞”把数据传进来,这就是为什么叫打洞技术了。 接下来,通过某种方式将打好的洞信息:NAT映射后的公网地址:端口告诉要通信那方,要通信那方就向该洞:1.2.3.4:1234发数据。NAT收到发到1.2.3.4:1234的数据,NAT网关在关联表中找到映射,然后转发数据到对应私网设备(10.0.0.100:1234)。 这里我们总结下打洞技术: 1)首先位于NAT后的Peer1节点需要向外发送数据包,以便让NAT建立起私网Endpoint1(IP1:PORT1)和公网Endpoint2(IP2:PORT2)的映射关系; 2)然后通过某种方式将映射后的公网Endpoint2通知给对端节点Peer2; 3)最后Peer2往收到的公网Endpoint2发送数据包,然后该数据包就会被NAT转发给私网的Peer1。 Relay(服务器中转)技术 在有些情况下,打洞会失败(下节介绍),此时只能通过部署在公网的第三方服务器进行数据转发,间接实现通信。 NAT类型 由于存在不同的NAT部署方式,所以产生了不同类型的NAT。 完全圆锥型NAT(Full cone NAT),即一对一(one-to-one)NAT。 一旦一个内部地址(iAddr:port)映射到外部地址(eAddr:port),所有发自iAddr:port的包都经由eAddr:port向外发送。任意外部主机都能通过给eAddr:port发包到达iAddr:port(注:port不需要一样) 受限圆锥型NAT(Address-Restricted cone NAT) 内部客户端必须首先发送数据包到对方(IP=X.X.X.X),然后才能接收来自X.X.X.X的数据包。在限制方面,唯一的要求是数据包是来自X.X.X.X。 内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。外部主机(hostAddr:any)能通过给eAddr:port2发包到达iAddr:port1。(注:any指外部主机源端口不受限制,但是目的端口必须是port2。只有外部主机数据包的目的IP 为 内部客户端的所映射的外部ip,且目的端口为port2时数据包才被放行。) 端口受限圆锥型NAT(Port-Restricted cone NAT)。类似受限制锥形NAT(Restricted cone NAT),但是还有端口限制。 一旦一个内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。 在受限圆锥型NAT基础上增加了外部主机源端口必须是固定的。 对称NAT(Symmetric NAT) 每一个来自相同内部IP与端口,到一个特定目的地地址和端口的请求,都映射到一个独特的外部IP地址和端口。 同一内部IP与端口发到不同的目的地和端口的信息包,都使用不同的映射 只有曾经收到过内部主机数据的外部主机,才能够把数据包发回 如果NAT是完全圆锥型的,那么双方中的任何一方都可以发起通信。如果NAT是受限圆锥型或端口受限圆锥型,双方必须一起开始传输。若有一方位于对称NAT后,就无法打洞成功。由前面说明可知,对于对称NAT来说,客户端向STUN服务器(下节介绍,用于协助打洞)发包映射的公网IP:端口与向其它客户端发包映射的公网IP:端口是不一样的,一个连接创建一个公网的映射,也就是说其它客户端无法使用之前通过STUN服务器打好的洞,所以客户端双方无法成功打洞,只能使用中转方案。 ICE STUN STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序),是基于UDP的完整的穿透NAT的解决方案,属于我们前面说到的打洞技术。它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的NAT之后以及NAT为某一个本地端口所绑定的公网端端口。这些信息被用来在两个同时处于NAT路由器之后的主机之间创建UDP通信。STUN是一种Client/Server的协议,也是一种Request/Response的协议,默认端口号是3478。 下面我们通过Wireshark抓包看下是如何Request/Response的。 如下图所示,首先客户端向地址为216.93.246.18的STUN服务器发送Binding Request。 服务器回了Binding Response: 接着我们向地址为216.93.246.15的STUN服务器执行同样操作: 我们看到Binding Response包MAPPED-ADDRESS属性里包含了客户端映射到公网的IP地址以及端口。上图可知两个STUN服务器返回的客户端映射到公网的端口不一样,说明客户端现在位于对称型NAT后,无法进行打洞。 四种主要NAT类型中有三种是可以使用STUN进行穿透:完全圆锥型NAT、受限圆锥型NAT和端口受限圆锥型NAT,对称型NAT则不能使用,原因前面也说到了。 TURN TURN(Traversal Using Relay NAT,通过Relay方式穿越NAT),是一种数据传输协议。允许通过TCP或UDP方式穿透NAT或防火墙。TURN是一个Client/Server协议。TURN的NAT穿透方法与STUN类似,都是通过取得应用层中的公网地址达到NAT穿透。但实现TURN client的终端必须在通讯开始前与TURN server进行交互,并要求TURN server产生"relay port",也就是relayed-transport-address。这时TURN server会建立peer,即远端端点(remote endpoints),开始进行中继(relay)的动作,TURN client利用relay port将数据传送至peer,再由peer转传到另一方的TURN client。 TURN主要用在使用STUN无法穿透的场景下,例如前面说到的对称型NAT,只能通过TURN server进行数据中转。 ICE ICE(Interactive Connectivity Establishment,互动式连接建立)。ICE定义了穿越方法而不是协议。ICE整合了STUN与TURN。ICE使得两个NAT后的端点通信更加便捷。ICE使用STUN进行打洞,若失败,则使用TURN进行中转。 下面我们举个应用场景,说下ICE的大概流程。 场景 如下图的应用场景,用户Alice要与Bob进行通信,这两个用户都位于NAT后,公网部署了STUN与TURN服务器。 收集候选地址(candidate) 首先客户端要收集candidate。candidate表示候选地址,由IP地址与端口组成。收集的candidate要与对方的candidate组成candidate pair,进行连通性检查。candidate主要有三种: Host candidate(host):从本地网卡上获取的地址 Server reflexive candidate(srflx):STUN server 观察的该客户端的地址 Relay reflexive candidate(relay):TURN server 为该客户端分配的中继地址 客户端通过向STUN服务器发送STUN数据包,STUN服务器做出回应,告知其在数据包中监测到的IP地址以及端口。 下图中,Alice与Bob通过STUN以及TURN服务器收集了三种类型的candidate。 连通性检查 收集candidate后把通过信令offer与answer方式双方交换candidate,进行candidate两两配对,然后ICE连通性检查。这个连通性检查按一定规则的。 本地的candidate与远端candidate构成的每一对都有一定的优先级,按优先级排序进行连通性检查。 数据传输 最后从有效的candidate组合中选择优先级最高的作为传输地址,用于数据传输。 Trickle ICE 在WebRTC中使用ICE框架进行P2P通信。前面说到ICE中第一步是收集candidate,需要遍历STUN以及TURN服务器,这一步需要耗费很多时间,导致双方建立通信时间很慢。为了解决这一问题,WebRTC引入了Trickle ICE,这样candidate收集以及连通性检查可以同时进行,加快双方建立通信的速度。 libnice库 若要让我们的程序支持ICE,我们可以借助第三方库。常见的支持ICE的库有Libjingle,Libnice。Libjingle集成在WebRTC里,不方便独立使用,这里我们推荐使用Libnice,常见的WebRTC服务器,例如janus,licode都是使用libnice进行P2P通信,具体可访问Libnice官网了解。 总结 本文主要介绍了NAT穿透技术,几种NAT类型,最后介绍了NAT穿透最常用的方案:ICE。通过本文,希望大家对音视频P2P传输中的NAT穿透有一定了解。 参考 [1] P2P技术详解(一):NAT详解——详细原理、P2P简介.http://www.52im.net/forum.php?mod=viewthread&tid=50&highlight=p2p. [2] 网络地址转换.https://zh.wikipedia.org/zh-hans/网络地址转换. [3] Trickle ICE.https://tools.ietf.org/html/draft-ietf-ice-trickle-21.
Recent Comments
Miles0u Published at 1 days ago(04 04202643009 22 22pm26)
Addiea9 Published at 2 weeks ago(04 04202643001 08 08am26)
snail Published at 4 weeks ago(03 03202633105 27 27pm26)
dongxuh Published at 9 months ago(07 07202573103 27 27pm25)
南南 Published at 9 months ago(07 07202573103 15 15pm25)