使用RTP协议封装数据时,我们可以通过RTP报头的序列号连续性判断是否丢包。但由于RTP报头序列号只有两字节表示,值范围[0,65535],存在回绕问题(参考之前文章:WebRTC研究:RTP中的序列号以及时间戳比较,建议先阅读一遍此文章)。所以判断序列号连续性时得考虑回绕问题。下面我们就结合WebRTC这相关源码,讲下如何有效地根据序列号进行丢包判断。 首先看下这块代码,代码位于jitter_buffer.cc中: [crayon-69e9aef756276026728834/] IsNewerSequenceNumber函数以及latest_received_sequence_number_介绍在之前文章说过,读者可参考前面给的文字链接。上述代码丢包判断用到的相关定义如下: IsNewerSequenceNumber:判断是否是最新的序列号 sequence_number:当前收到的包序列号 latest_received_sequence_number_:上一次收到的最新RTP包序列号 missing_sequence_numbers_:存储丢包序列号 丢包判断流程如下: 首先IsNewerSequenceNumber传入当前收到的包序列号sequence_number以及之前收到的最新RTP包序列号latest_received_sequence_number_,判断当前RTP包是否是新的数据包,而不是重传包或者乱序包 在for循环中,从latest_received_sequence_number_ + 1开始判断(因为如果丢包了,两个包序列号间隔大于1),满足IsNewerSequenceNumber(sequence_number, i)则说明i为丢失的RTP包序列号,插入missing_sequence_numbers_中,接着++i继续判断,否则退出 通过如上方法,我们就可以获取那些丢失的包序列号,是不是很简单。

什么是声音 介质振动在听觉系统中产生的反应。是一种波。因为是一种波,所以我们可以用频率、振幅等描述。 图1.蚊子翅膀振动产生声音传到人耳 频率与振幅 有两个基本的物理属性:频率与振幅。声音的振幅就是音量,也叫作响度,频率是单位时间振动次数,频率的高低就是指音调,频率用赫兹(Hz)作单位。 图2.声音波形 人耳只能听到20Hz到20kHz范围的声音。小于20HZ的叫次声波,大于20kHz的叫做超声波。超声波在现实中有很多应用,例如洗牙,测距,成像等。 图3.声音按频率分类 分贝 因为人耳的特性,我们对声音的大小感知呈对数关系。所以我们通常用分贝描述声音大小,分贝(decibel)是量度两个相同单位之数量比例的单位,主要用于度量声音强度,常用dB表示。声学中,声音的强度定义为声压。计算分贝值时采用20微帕斯卡为参考值(通常被认为是人类的最少听觉响应值,大约是3米以外飞行的蚊子声音)。这一参考值是人类对声音能够感知的阈值下限。声压是场量,因此使用声压计算分贝时使用如下公式: 图4.分贝计算(Pref是标准参考声压值20微帕) 由上述公式可知,当声音强度等于Pref时,db=0,也就是说0分贝时声音最小。 模拟音频与数字音频 模拟音频(Analogous Audio),用连续的电流或电压表示的音频信号,在时间和振幅上是连续。在过去记录声音记录的都是模拟音频,比如机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式。 数字音频(Digital Audio),通过采样和量化技术获得的离散性(数字化)音频数据。计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。 图5.典型的音频采集并转换成计算机处理的数字音频信号流程 采样频率 声音以模拟波形的形式存在。数字音频片段以足够快的速率对模拟波的振幅进行采样,模仿波的固有频率,达到高度接近这种模拟波的效果。 采样频率(Sampling Rate),单位时间内采集的样本数,是采样周期的倒数,指两个采样之间的时间间隔。采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号,这其实就是著名的香农采样定理。例如,要表示人类听觉范围 (20-20000 Hz) 内的音频,数字音频格式必须至少每秒采样 40000 次(CD 音频使用 44100 Hz 的采样率,部分原因也在于此)。 图6.采样频率 CD音质采样率为 44.1 kHz,其他常用采样率:22.05KHz,11.025KHz,一般网络和移动通信的音频采样率:8KHz。采样频率越高,声音质量越好。一般我们语音通信中(VOIP,例如微信,QQ语音聊天),我们对声音质量要求没那么高,能听清讲的什么即可,所以常采用8KHz采样率。 图7.CD以及VOIP采样频率对比 量化 量化(Quantization )是将经过采样得到的离散数据转换成二进制数的过程。量化的过程是先将整个幅度划分成有限个小幅度(量化阶距)的集合,把落入某个阶距内的样值归为一类,并赋予相同的量化值。 量化深度,表示一个样本的二进制的位数,即每个采样点用多少比特表示,在计算机中音频的量化深度一般为4、8、16、32位(bit)等。例如:量化深度为8bit时,每个采样点可以表示256个不同的量化值,而量化深度为16bit时,每个采样点可以表示65536个不同的量化值。量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多,位数越少,声音的质量越低,需要的存储空间越少。CD音质采用的是16 bits,移动通信 8bits。 图8.量化信号 存储大小 声道数。记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。使用双声道记录声音,能够在一定程度上再现声音的方位,反映人耳的听觉特性。 数字音频存储大小。采样频率、量化深度数越高,声音质量也越高,保存这段声音所用的空间也就越大。立体声(双声道)存储大小是单声道文件的两倍。即: 文件大小(B)=采样频率(Hz)×录音时间(S)×(量化深度/8)×声道数(单声道为1,双声道为2) 如:录制1分钟采样频率为44.1KHz,量化深度为16位,立体声的声音(CD音质),文件大小为: 44.1×1000×60×(16/8)×2=10584000B≈10.09M 可以看到数字音频信号如果不加压缩地直接进行传送或者存储,将会占用极大的带宽以及磁盘空间,这也是后面讲到的音频要进行压缩的原因。 声音编码压缩 压缩基础 音频数据通常会进行压缩,以便更易于存储和传输。通过采样以及量化得到的数字音频信号中存在着大量冗余。数字音频压缩编码保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩。数字音频压缩编码采取去除声音信号中冗余成分的方法来实现。所谓冗余成分指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为20Hz~20KHz,范围外的其它频率人耳无法察觉,都可视为冗余信号。此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应。 有损压缩与无损压缩 无损压缩。无损压缩虽然缩小音频的储存大小,但可以保留原始文件的所有信息。无损压缩是一个可逆的过程,利用信息冗余进行数据压缩,类似我们平时用的rar,zip等文件压缩。常见无损压缩格式有:APE,FLAC等。 有损压缩。有损压缩是一个不可逆的过程。有损数据压缩利用人类听觉特性,将不重要的声音信息舍弃,虽然有损压缩在理论上对原始文件造成损失,但这种损失不一定能被人耳分辨出来。常见有损压缩格式有:MP3,AAC,OGG等。
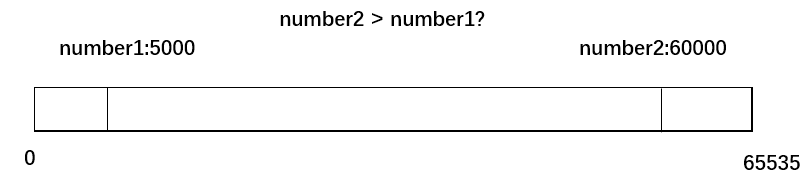
在使用RTP协议时,如果需要网络对抗,保障QoS(Quality of Service,服务质量),我们需要通过序列号以及时间戳的比较,进行丢包判断。但是有个问题,比如一个RTP包,序列号为number1:5000,另一个RTP包序列号为number2:60000,可以说60000一定比5000大,是个更新的RTP包吗? 当然不是了,首先我们先重温下RTP数据包的结构。 在RFC3550中RTP固定报头结构按如下定义: [crayon-69e9aef7580c0246320090/] 可以看到,RTP序列号sequence number用两字节表示,时间戳timestamp用四字节表示。所以序列号以及时间戳就存在一个取值范围。由于是无符号数,所以序列号范围为:[0,2^16-1],时间戳范围为:[0,2^32-1]。当达到最大值时,将发生所谓的回绕。例如,序列号到了2^16-1,下个包序列号就将是0。所以我们不能直接根据数学意义上的大小进行序列号以及时间戳的比较。 在WebRTC中定义了一个大小比较算法,包含数字回绕处理,判断是否是更新的数字。下面说下算法原理: 1)假设有两个U类型的无符号整数:value, prev_value; 2)定义一个常量kBreakpoint,为U类型取值范围的一半; 3)value > prev_value,满足value - prev_value = kBreakpoint时,value大于prev_value; 4)value与prev_value不相等,满足(U)(valude - prev_value) < kBreakpoint时,value大于prev_value。 总结起来就是value与prev_value距离小于取值范围的一半且不相等或者value与prev_value距离等于取值范围的一半,value大于prev_value,就可以说明value大于prev_value。 在modules\include\module_common_types_public.h,相应代码如下: [crayon-69e9aef7580ca864910681/] 顺便也说下如上函数的一个应用。在WebRTC丢包重传判断中(jitter_buffer模块),需要保存上一次收到的最新RTP序列号latest_received_sequence_number_,以便用于丢包判断(请参考:WebRTC研究:丢包判断),这个RTP包必须是新的数据,不能是重传的旧数据。所以每来一个RTP包时,可以将该RTP包序列号传入如上函数,与之前收到的最新RTP序列号进行对比,从而判断当前RTP包是不是最新的。相应代码如下: [crayon-69e9aef7580cf703344760/] 参考 [1].rfc1982.https://tools.ietf.org/html/rfc1982

去年写过FireBreath插件的文章,那时刚到新公司,独自开发一款传统的视频播放器插件。后面基于Firebreath框架开发,支持IE以及Firefox。转眼一年多了,播放器插件已经成功部署在公司多个项目中,无论特色功能点,性能,稳定性,都达到令人满意的程度。最近一个项目要在IE11浏览器上跑,由于之前都是在Firefox上跑,IE上没怎么测过,所以在IE上跑时出现了个问题:接口传入的中文字符乱码。 播放器插件多个接口需要传入带中文字符参数,比如视频OSD水印,抓图位置以及图片水印,下载录像保存位置,下载录像添加的水印等等。Firebreath JSAPI接口支持std::string以及std:wstring两种类型的字符串,在Firefox上,相应接口参数设置为std:wstring即可满足传入参数带中文字符问题,但是IE11上却不行,传入的中文字符一直都是乱码。由于只支持这两种类型字符串,传入的都是乱码,所以插件内部怎么处理都不行,只能从外部入手了。 后面灵光闪现,想到对中文字符做处理,想到浏览器怎么对地址栏输入地址的处理。所以前端使用encodeURI函数编码传入的带中文参数,插件内部再解码即可,这样就可以顺利地传入带中文的参数。经测试,在IE与Firefox上,这种方法都正常运行。插件内部用到的UriDecode函数如下: [crayon-69e9aef7592de061137436/]

WebRTC采用UDP传输流媒体数据,不可避免存在丢包情况。WebRTC主要采用FEC(Forward Error Correction,前向纠错)以及NACK(negative-acknowledge character,否定应答)对抗网络丢包。对于NACK,遇到丢包了才通知发送端重传对应数据包,但不是所有情况下某个包丢了就一定重传该包,有些场景下,重传该包会带来其它问题,例如增大延时,缓存过大,同时也可能发送端没有该数据包缓存,导致无法重传,此时会放弃重传该包。由于关键帧可以单独解码出图像,不参考前后视频帧,所以会采取请求关键帧这种更便捷的方式替代重传该数据包,使解码端能立刻刷新出新图像,避免丢包过多,长时间等待重传数据包导致的画面停顿问题,以及获取不到重传包导致后续数据解码花屏问题。除了丢包,在WebRTC还存在其他请求关键帧的场景。 关键帧请求场景 下面结合代码列举几种常见场景。 H264解码无sps,pps信息 解码H264时无法获取sps,pps,导致无法解码,此时就需要请求获取关键帧,在H264SpsPpsTracker中,相关处理代码如下: [crayon-69e9aef759b9a283195464/] 丢失包过多 在非常高的丢包率情况下,丢失的包太多,若都一一重传,将造成延时增大(等帧数据完整了才会去解码渲染),此时新来的数据也只能一直缓存,所以jitterbuffer大小也会不断增大,此时不如直接请求发送一个关键帧来得实际,以前丢的那些包都不管了,由于关键帧可以单独解码,所以不会造成解码端花屏马赛克现象。但是由于前面那些视频帧都丢弃了,此时生成的关键帧会与之前播放的视频存在不连贯性,所以画面变化大时会有轻微卡顿现象,相当于跳帧了。NackModule中相关处理代码如下: [crayon-69e9aef759ba3163455036/] 上面代码中,要重传的包数量nack_list_.size()在进行RemovePacketsUntilKeyFrame()操作后若还超过规定大小,就开始清空要重传的数据包列表:nack_list_.clear(),然后请求关键帧。 丢失包过旧 发送端默认缓存600个RTP包,如果丢失的包太旧,超出缓存范围,此时发送端就没有该数据包的缓存,就无法重传该包。在VCMJitterBuffer中,相关处理代码如下: [crayon-69e9aef759ba7917140354/] 获取帧数据超时 要解码的帧数据存放在FrameBuffer中,解码器解码时如果超过规定时间一直无法从FrameBuffer中获取解码数据,此时就会请求关键帧。相关处理代码如下: [crayon-69e9aef759baa304735636/] 解码出错 当解码器返回解码失败,或者解码器返回请求关键帧结果时,需要请求关键帧。相关处理代码如下: [crayon-69e9aef759bad652422341/] 在上面我们列举了几种需要关键帧请求的情况,我们只需要规定好RTCP报文格式,就能通知编码发送端发送关键帧。关键帧请求RTCP报文格式比较简单,在RFC4585(RTP/AVPF)以及RFC5104(AVPF)规定了两种不同的关键帧请求报文格式:Picture Loss Indication (PLI)、Full Intra Request (FIR)。WebRTC中关键帧请求也只用到了这两种消息,相关代码如下: [crayon-69e9aef759bb1353580082/] Picture Loss Indication (PLI) 在RFC4585中定义,属于RTCP反馈消息中的一种。RTCP反馈消息数据包格式按如下规定: [crayon-69e9aef759bb5125550649/] 其中PT字段按如下规定: [crayon-69e9aef759bb8141601348/] 对于PLI,由于只需要通知发送关键帧,无需携带其他消息,所以FCI部分为空。对于FMT规定为1,PT规定为PSFB。 在WebRTC源码中,PLI相关解析封装代码位于webrtc::Pli中。相关代码如下: [crayon-69e9aef759bbb286576511/] PLI消息用于解码端通知编码端我要解码的图像的编码数据丢失了。对于基于帧间预测的视频编码类型,编码端收到PLI消息就要知道视频数据丢失了,由于帧间预测需要基于前后完整的视频帧才能解码(例如H264中,存在B帧,需要参考前后帧才能解码),前面的数据丢失了,后面的视频帧不能正常解码出图像,此时编码端可以直接生成一个关键帧,然后发送给解码端。 Full Intra Request (FIR) 在RFC5104中定义。参照上一小节RTCP反馈消息数据包格式,对于FMT规定为4,PT规定为PSFB。由于FIR可用于通知多个编码发送端(例如多点视频会议情况),所以用到了FCI部分,填充多个发送端的ssrc信息。具体包格式如下: [crayon-69e9aef759bbe808074568/] 在WebRTC源码中,FIR相关解析封装代码位于webrtc::Fir中。相关处理代码就不贴出来了,类似PLI处理,除了FCI部分要填充一些信息。 当解码端需要刷新时,可以发送FIR消息给编码端,编码端此时发送关键帧,刷新解码端。这有点类似PLI消息,但是PLI消息是用于丢包情况下的通知,而FIR却不是,在有些非丢包情况下,FIR就要用到。举两个例子: 1)解码端需要切换到另一路不同视频时,由于需要新的解码参数,所以可通过发送FIR消息,通知编码端生成关键帧,获取新的解码参数,刷新视频解码器; 2)在视频会议中,新用户随机时刻加入,各个编码端发送的视频不一定都是关键帧,所以新用户不一定能正常解码。此时该新加入用户发送FIR消息,通知各个编码端给它发关键帧,获取关键帧后即可正常解码。 总结 本文主要介绍了几种关键帧请求场景,讲了AVPF中定义的两种关键帧请求消息,虽然这两种消息获取的结果一样,但是表达的意义却不一样,用于不同场景,使用时需要区分下。
最近群里有人问:NV12格式,怎么对应AVFrame中的data[0],data[1],data[2]。其实ffmpeg视频编码,YUV与AVFrame对应关系很简单。 在视频编码时,我们需要把YUV数据拷贝到AVFrame.data中,视频编码有硬件加速以及非硬件加速两种,所以对应关系也有两种。 硬件加速编码 指通过显卡进行硬件加速编码,例如指定vaapi进行编码。使用硬件加速编码时,YUV输入格式一般都是NV12,我做过的Intel以及Nvidia编码都是这样。之所以使用NV12格式,在Intel开发文档有这样说明: [crayon-69e9aef75af98384432051/] 因为ffmpeg底层也是调用相关显卡SDK做硬件加速编码,所以我们把YUV数据拷贝给AVFrame时,也得按NV12格式。对于NV12格式,Y数据在最前,接着是UV交错排布,类似这样:YYYYYYYY UVUV,所以对于AVFrame,我们得把Y数据拷贝data[0],UV数据拷贝给data[1]。 [crayon-69e9aef75afa1839054034/] 非硬件加速编码 指通过CPU进行编码,例如指定libx264,libx265进行编码。对应关系就比较简单了,YUV三个分量数据依次对应data[0],data[1],data[2]。 [crayon-69e9aef75afa5677422484/]
在音视频领域,想深入研究的话,必定会接触WebRTC。WebRTC是一个庞大的工程,就像是音视频领域的百科全书,音视频采集,编解码,传输,渲染等一条龙在WebRTC里都有,而且WebRTC还有很多先进的音视频处理算法。由于WebRTC代码过于庞大,所以最好单步调试跟踪代码运行,这样才可以更好地学习WebRTC,否则很难有头绪。工欲善其事必先利其器,作为调试神器,宇宙第一IDE Visual Studio必不可少。所以本篇文章主要讲下如何在Windows上编译WebRTC,同时得到VS工程,然后调试。 本文内容截止2020.04.01,最新代码测试编译通过。最新VS2017以上版本编译见文末。 系统要求 Win7及以上64位系统。 内存至少8G,当然越大越好。 至少50G磁盘空间(NTFS格式),不能是FAT32,因为会生成大于4G的文件。 Visual Studio安装 WebRTC用到了很多C++最新特性,所以编译最新WebRTC代码VS要求为2017(>=15.7.2) 版本。我用的是VS2017社区版(VS新老版本下载)。VS最好安装在C盘,按默认路径安装,否则可能遇到问题(见问题0x02)。安装VS2017时选择自定义安装,必须勾选如下几项: Desktop development with C++组件中10.0.18362或以上的Win10 SDK,后面还要安装调试工具 Desktop development with C++组件中MFC以及ATL这两项 2020.04.01更新:由于最新WebRTC源码要求10.0.18362及以上Win10 SDK。所以请下载10.0.18362 或以上的Win10 SDK。本文写于2019年,那时VS2019还没发布。由于10.0.18362 Win10 SDK存在于VS2019安装选项中,VS2017安装选项不带有该SDK,所以使用VS2017得从Win10 SDK下载另外下载最新Win10 SDK,或者再装个VS2019选择安装该SDK 安装完VS2017后,必须安装SDK调试工具。打开控制面板->程序与功能,找到刚才安装的最新Windows Software Development Kit,鼠标右键->change。 勾选Debugging Tools For Windows,然后点击change。 depot_tools安装 下载depot_tools然后解压到某个目录,比我的解压到E盘根目录。接着将该depot_tools目录的路径加到系统环境变量Path里,然后把该路径移到最前面(避免已安装的python与git造成影响)。 获取WebRTC源码 由于WebRTC的源码地址被墙了,所以需要通过代理或者vpn才能得到源码。后面都是命令行操作,打开cmd窗口,由于我用的是ss代理,在cmd窗口我按如下设置: [crayon-69e9aef75c108827016061/] 设置当前cmd窗口代理上网,如果cmd窗口关闭了重开得重新设置。当然了,也可以设置系统全局代理上网。其他代理方法也类似。如果是VPN之类非代理,就不用这样设置了。 接着执行gclient命令,安装编译需要用到的一些工具,比如git以及python。 [crayon-69e9aef75c111022064981/] 再接着设置一些环境变量,设置下我们的VS安装路径。 [crayon-69e9aef75c115085994525/] 然后cd到要放源码的地方(要遵守前面说的磁盘要求),执行: [crayon-69e9aef75c119831384527/] 这一过程是个漫长的等待,要下的东西将近10G,包括源码以及一些测试的音视频文件资源等,如果因为网络等原因中断了,就再执行gclient sync。如果这一步一直卡着不动,可以执行ctrl+c,然后执行gclient sync。 使用gclient sync可能遇到的问题 问题0x01 [crayon-69e9aef75c11c849533431/] Unicode字符编码问题,python的一个bug,因为很多人系统语言都是中文的,所以得按如下设置,把系统区域改为英文,然后重启即可。 问题0x02 2019.04.01更新。去年的版本我编译时没报这个问题,我看到评论里有人提出来了,我下了今天的最新代码,编译时也碰到了,看了下是最新WebRTC windows相关脚本变化导致 报Exception: No supported Visual Studio can be found. Supported versions are: 16.0 (2019), 15.0 (2017)错误: [crayon-69e9aef75c11f586617040/] 解决方法为修改src\build目录下的vs_toolchain.py脚本,加了一行,直接写死我们的VS路径代码: [crayon-69e9aef75c122487302197/] 脚本中的代码默认以C盘处理的,如果我们的VS安装在C盘默认目录就不会报这个错,但我想很多人VS不会装在C盘。 执行:python src/build/vs_toolchain.py get_toolchain_dir验证修改,控制台打印如下: [crayon-69e9aef75c125025111985/] 说明修改成功。接着我们使用gclient sync会报如下问题: [crayon-69e9aef75c128879049562/] 因为我们修改了脚本,所以执行gclient sync --force即可。 gclient sync --force成功结束后,vs_toolchain.py文件会被还原,所以得按前面重新修改vs_toolchain.py。vs_toolchain.py中会优先选择高版本VS编译,由于本文使用VS2017编译,假如我们电脑安装有VS2019,需要按如下修改,把VS2017放前面,避免造成影响。 [crayon-69e9aef75c12c539012504/] 编译 生成VS2017工程文件: [crayon-69e9aef75c12f302400391/] 可以在src\out\Default\ 下得到 all.sln解决方案文件。 如果不想使用默认编译参数,可以使用gn args out/Default --list查看当前编译参数,通过类似如下方式设置: [crayon-69e9aef75c132413639057/] 接着执行编译命令: [crayon-69e9aef75c135855025311/] 用VS2017打开: 可以看到众多工程,到此算是完成了。找到我们感兴趣的,就可以用VS单步调试,跟踪代码运行了。这么多宝贝够研究很久了。 代码更新 [crayon-69e9aef75c138278950382/] 引用WebRTC库 WebRTC编译后会在src\out\Default\obj目录下生成整个WebRTC工程的静态库:webrtc.lib,链接下这个就可以了。 总结 总之WebRTC在Windows上的编译很考验耐心,也很苛刻,需要有个好的访问被墙地址工具。最新VS2019编译可以参考我的这篇文章: Windows平台WebRTC编译(持续更新),本文也不再更新。 参考 1. WebRTC Native code Development 2. Chromium’s build instructions for Windows
本篇文章有些内容比较过时,最新请参考:https://blog.jianchihu.net/intel-gpu-hw-video-codec-develop.html。包含CentOS以及Ubuntu的开发环境搭建 最近要在Linux上做编解码开发,为了成本考虑,没用NVIDIA的方案,用了Intel编解码方案。大家都知道Intel在Windows上有个Intel Media SDK的方案,比较常用,支持的CPU型号也多,在Linux上也有类似方案,叫做Intel Media Server Studio。但是Intel Media Server Studio支持的型号比较少,如下是官方文档说明的支持型号: [crayon-69e9aef75eee8242506254/] 不过还有一个叫做VA API(Video Acceleration API) 的方案,VA API是一个统一的编解码规范,类似Windows上的Dxva方案,主要由各大显卡厂商在驱动中实现。目前主要Intel与AMD实现这个VA API方案,不过AMD上支持的编解码特性比较少,也只是部分支持。对于Intel来说,基本上带集显的都支持VA API。所以为了成本,通用性考虑,我选用了这个VA API做Linux上的编解码开发。 如果基于原生VA API开发的话,比较复杂点,好在ffmpeg支持VA API,所以我们只需要编译支持VA API的ffmpeg即可。本篇文章主要讲下VA API开发环境的搭建,主要针对H264编解码。开发系统为ubuntu18.04.2 LTS server版本。需要注意的是,目前没看到好的显卡直通(passthrough)以及虚拟化方案,我们还是老实在实体机Linux开发,不能在虚拟机里,要不就用不了显卡硬件加速了。 基本库安装 [crayon-69e9aef75eef1395830675/] VA API相关库驱动安装 Libva Libva是VA API的实现。 [crayon-69e9aef75eef5162499938/] intel-vaapi-driver 主要在我们的程序与Intel 集显之间起桥梁作用。传输打包的缓存以及命令到i965驱动(开源的intel集显驱动,已集成在Linux内核中),用于硬件加速的视频编解码,着色器处理等。 [crayon-69e9aef75eef9952792529/] libva-utils 提供一系列 VA API相关的测试。比如vainfo命令,可以用来检测我们的硬件支持哪些VA API编解码特性。 [crayon-69e9aef75ef06537209042/] 这一步安装完后,我们开始检测安装的成果,首先查看我们的显卡设备: [crayon-69e9aef75ef0a477691718/] 可以看到我的电脑有两张显卡,一张独显,一张集显。下面开始通过vainfo命令验证显卡支持情况: [crayon-69e9aef75ef0e996152698/] 可以看到我的AMD独显VA API支持很少,Intel集显基本都支持了。如果通过vainfo命令我们如上所示得到显卡支持情况,说明我们VA API相关驱动以及库安装成功了。下面介绍下支持VA API的ffmpeg的编译。 ffmpeg编译 参照官方编译,创建相关目录用于存放源码以及编译后的程序。 [crayon-69e9aef75ef12282593700/] 安装nasm与yasm。ffmpeg一些汇编程序用到。 [crayon-69e9aef75ef16322382737/] 编译安装libx264,用于软编H264。 [crayon-69e9aef75ef19029432772/] 下载最新的ffmepg源码,编译。 [crayon-69e9aef75ef1c528305739/] 最后编译生成的静态库文件都在主目录ffmpeg_build里,用于我们的开发。ffmepg可执行程序在主目录bin下。运行ffmpeg程序,执行如下命令: [crayon-69e9aef75ef1f451695170/] 可以看到我们编译的ffmppeg已经支持VA API了。 VA API编解码开发 ffmepg官方example有VA API使用教程,具体可以看官方示例代码。不过需要注意的是VA API编码时,输入的YUV格式必须是NV12,其他格式YUV得转为NV12格式。官方example:vaapi_encode.c有个AVFrame(sw_frame) ,用于存放我们输入的YUV数据,该AVFrame的data[0]用于存放Y数据,data[1]存放UV数据,由于输入格式是NV12,所以data[1]中UV数据的内存布局为:UVUVUVUV···UVUV。