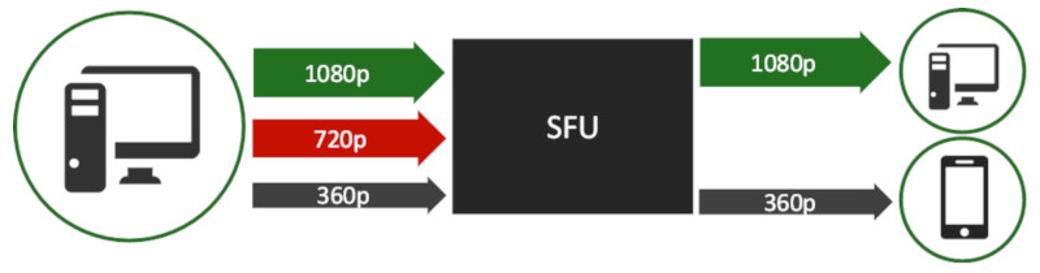
基于SFU架构的视频会议系统中,Simulcast是最主流的带宽自适应方案。发布端(Publisher)同时编码并发送多路不同分辨率的流(通常为小、中、大三路),订阅端(Subscriber)则根据自身网络带宽、设备性能、窗口大小等因素,选择订阅最合适的单路流。这种设计发布端与订阅端互不干扰: 发布端仅受自身上行带宽和编码负载影响 订阅端仅受自身下行带宽,解码能力,显示窗口影响 但在实际生产环境中,某些核心场景却需要订阅端能够“反向影响”发布端,即实现backpressure(反压)机制。 反压需求场景 按需推流 当会议中所有订阅端都处于小窗口显示(如宫格数较多、缩略图模式)时,大家只会订阅小流。此时发布端若仍持续推送大流,就会造成巨大的上行带宽浪费和服务器转发压力。理想状态是:订阅端集体选择小流 → SFU 通知发布端自动降档,只推小流即可。 SFU模拟点对点(P2P)通话 用SFU统一实现1对1通话(便于后续扩展多人)。此时必须达到原生P2P(ICE直连)的体验。 订阅端网络恶化时,不能仅靠切换Simulcast层(因为只有一层流),而应直接让发布端降低编码码率/分辨率 订阅端网络恢复后,发布端也要快速回升 在传统Simulcast中做不到这样的“端到端拥塞控制”。 SFU如何实现订阅端反压 核心思路:在SFU内部为每个发布源(Source)和每个订阅接收器(Sink) 建立反馈通道,让订阅客户端的带宽估计结果能够传递到发布客户端。 下面是实现原理图: 发布客户端 → RTP → SFU Source(发布源) SFU Sink(订阅接收器)收到订阅端发来的 Transport-CC报文,进行下行带宽估计 Sink通过onFeedback接口将估计带宽值传递给对应的Source Source封装REMB(Receiver Estimated Maximum Bitrate)RTCP报文,传回到发布客户端 发布客户端收到REMB后,强制限制自身带宽估计值 这样就实现了订阅端 → SFU → 发布端的完整反压闭环。 REMB RTCP报文复用 WebRTC早期就内置了REMB RTCP,用在最早的接收端带宽估计中,接收端的带宽估计就是通过REMB反馈到发布端。虽然现在是Transport-CC + Sendside BWE,但REMB仍然被支持。这里可以看下REMB报文格式: [crayon-69d80de346928221430448/] 对于SFU,带宽反馈处理只需在 Source 侧调用: [crayon-69d80de346936154863675/] 发布客户端中WebRTC收到REMB后的处理如下: [crayon-69d80de34693a068191795/] 至此我们完成初步的反压实现。 遗留问题:弱网解除后带宽恢复速度慢 前面实现后还有个问题,就是订阅端弱网恢复后,恢复之前码率较慢。原因如下: 订阅端之前带宽差 → SFU反馈低REMB → 发布端码率被压得很低 订阅端网络恢复 → 其BWE想提升,但实际收到的码率仍然很低(受发布端限制) 订阅端BWE探测不到更高带宽 → 继续反馈低REMB → 发布端无法提升 → 形成“死循环” 这就像“受制于人”,恢复速度远慢于原生的P2P实现。 这时候我们可以在SFU的Sink(下行)侧中,主动注入探测流量,也就是引入探测(Padding)包。让订阅端能够获得额外码率进行更大带宽探测,打破死循环,加快恢复到之前码率。 总结 通过以上机制,SFU不仅保留了Simulcast的灵活性,还具备了端到端拥塞控制能力,让视频会议在复杂网络环境下也能提供接近原生P2P的流畅体验。
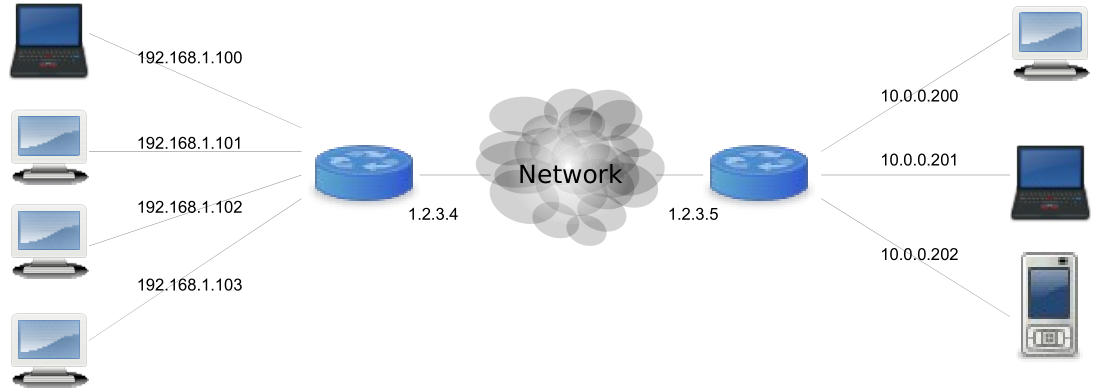
如今越来越多的音视频应用场景采用WebRTC技术,例如视频会议,在线教育,云游戏等。WebRTC包含一套强大的点对点(P2P)通信技术方案,用于音视频传输,本文我们来了解下背后的NAT穿透技术。 什么是NAT NAT(Network Address Translation)指的是网络地址转换,常部署在一个组织的网络出口位置。网络分为私网和公网两个部分,NAT网关设置在私网到公网的路由出口位置,私网与公网间的双向数据必须都要经过NAT网关。位于NAT后的是私网IP地址,分配给NAT的是公网IP地址。NAT通过将私网IP地址映射为公网IP地址,实现私网设备访问外部互联网的能力。组织内部的大量设备,通过NAT就可以共享一个公网IP地址,解决了IPv4地址不足的问题。同时NAT也起到隐藏内部设备,安全防护的作用。 如下图所示,有两个组织,每个组织的NAT分配一个公网IP,分别是1.2.3.4以及1.2.3.5。每个组织私网设备通过NAT将内网地址转换为公网地址,然后加入互联网。通过NAT每个私网设备就不必都需要分配公网IP了,就像图中,一个组织配一个公网IP即可。 NAT问题 虽然NAT解决了IPv4地址耗尽的问题,但是也存在一些问题。首先我们先说下不存在NAT时设备间点对点(P2P)通信情况: 1)位于同一个私网内,可以直接通过内网IP地址通信(例如192.168开头IP地址); 2)通信双方都有独立的公网IP地址,可以直接通过公网IP地址通信。 但是NAT的存在就不能这样处理了,增加了点对点通信的复杂度。如下图所示: 左边私网地址为192.168.1.100的设备要跟右边组织内的设备进行通信,由于右边组织多台设备共享一个公网IP,所以不能直接通过公网IP地址端口号进行通信,数据发过去了,根本不知道送到哪台设备,这样两个组织内的设备就不具有点对点通信的能力。既然这样,数据要怎么穿过NAT到达私网内,NAT网关要如何转发数据到指定设备呢? NAT穿透技术 现实生活中,大多数设备都位于NAT后。比如连着同一个基站的移动设备,同一个小区的宽带用户等。NAT的存在使得设备间不能直接进行点对点通信。有时候为了流量节省,以及安全等原因考虑,我们希望不同NAT后的设备也能进行点对点通信,不需要经过第三方的数据转发。为了进行设备间的点对点通信,我们需要使用相关技术检测设备间是否有点对点通信的可能性,以及如何进行点对点通信。这些相关技术就是NAT穿透(NAT traversal)。NAT穿透是为了解决使用了NAT后的私有网络中设备之间建立连接的问题。目前常见的NAT穿越技术、方法主要有: 应用层网关; 中间件技术; 打洞技术(Hole Punching); Relay(服务器中转)技术。 没有一种完美的NAT穿透,常常是多种技术互相配合,最常见的一种方案是打洞配合中转,例如后面说到的ICE方案。 NAT打洞技术 工作在传输层,最为常见。下面说下基本原理。 NAT网关维护着一张关联表,进行公网/私网地址端口的转换,结构如下所示: 私网IP 公网IP 192.168.1.100:5566 1.2.3.4:9200 192.168.1.101:80 1.2.3.4:9201 192.168.1.102:4465 1.2.3.4:9202 如下图,左边组织的公网IP为1.2.3.4NAT网关收到发到1.2.3.4:1234的数据,假如关联表中还未存在映射关系,NAT对外部发来的数据包直接丢掉。 所以网络访问只能先由私网侧发起,公网无法主动访问私网主机,既然这样,就由私网侧主动点。如下图: 私网地址10.0.0.100的设备发送数据包到公网。NAT网关关联表中创建了该设备私网地址:端口到公网地址:端口的映射,即上图中的10.0.0.100:1234到1.2.3.4:1234。这相当于在NAT上打了一个洞,其它人就可以通过这个“洞”把数据传进来,这就是为什么叫打洞技术了。 接下来,通过某种方式将打好的洞信息:NAT映射后的公网地址:端口告诉要通信那方,要通信那方就向该洞:1.2.3.4:1234发数据。NAT收到发到1.2.3.4:1234的数据,NAT网关在关联表中找到映射,然后转发数据到对应私网设备(10.0.0.100:1234)。 这里我们总结下打洞技术: 1)首先位于NAT后的Peer1节点需要向外发送数据包,以便让NAT建立起私网Endpoint1(IP1:PORT1)和公网Endpoint2(IP2:PORT2)的映射关系; 2)然后通过某种方式将映射后的公网Endpoint2通知给对端节点Peer2; 3)最后Peer2往收到的公网Endpoint2发送数据包,然后该数据包就会被NAT转发给私网的Peer1。 Relay(服务器中转)技术 在有些情况下,打洞会失败(下节介绍),此时只能通过部署在公网的第三方服务器进行数据转发,间接实现通信。 NAT类型 由于存在不同的NAT部署方式,所以产生了不同类型的NAT。 完全圆锥型NAT(Full cone NAT),即一对一(one-to-one)NAT。 一旦一个内部地址(iAddr:port)映射到外部地址(eAddr:port),所有发自iAddr:port的包都经由eAddr:port向外发送。任意外部主机都能通过给eAddr:port发包到达iAddr:port(注:port不需要一样) 受限圆锥型NAT(Address-Restricted cone NAT) 内部客户端必须首先发送数据包到对方(IP=X.X.X.X),然后才能接收来自X.X.X.X的数据包。在限制方面,唯一的要求是数据包是来自X.X.X.X。 内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。外部主机(hostAddr:any)能通过给eAddr:port2发包到达iAddr:port1。(注:any指外部主机源端口不受限制,但是目的端口必须是port2。只有外部主机数据包的目的IP 为 内部客户端的所映射的外部ip,且目的端口为port2时数据包才被放行。) 端口受限圆锥型NAT(Port-Restricted cone NAT)。类似受限制锥形NAT(Restricted cone NAT),但是还有端口限制。 一旦一个内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。 在受限圆锥型NAT基础上增加了外部主机源端口必须是固定的。 对称NAT(Symmetric NAT) 每一个来自相同内部IP与端口,到一个特定目的地地址和端口的请求,都映射到一个独特的外部IP地址和端口。 同一内部IP与端口发到不同的目的地和端口的信息包,都使用不同的映射 只有曾经收到过内部主机数据的外部主机,才能够把数据包发回 如果NAT是完全圆锥型的,那么双方中的任何一方都可以发起通信。如果NAT是受限圆锥型或端口受限圆锥型,双方必须一起开始传输。若有一方位于对称NAT后,就无法打洞成功。由前面说明可知,对于对称NAT来说,客户端向STUN服务器(下节介绍,用于协助打洞)发包映射的公网IP:端口与向其它客户端发包映射的公网IP:端口是不一样的,一个连接创建一个公网的映射,也就是说其它客户端无法使用之前通过STUN服务器打好的洞,所以客户端双方无法成功打洞,只能使用中转方案。 ICE STUN STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序),是基于UDP的完整的穿透NAT的解决方案,属于我们前面说到的打洞技术。它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的NAT之后以及NAT为某一个本地端口所绑定的公网端端口。这些信息被用来在两个同时处于NAT路由器之后的主机之间创建UDP通信。STUN是一种Client/Server的协议,也是一种Request/Response的协议,默认端口号是3478。 下面我们通过Wireshark抓包看下是如何Request/Response的。 如下图所示,首先客户端向地址为216.93.246.18的STUN服务器发送Binding Request。 服务器回了Binding Response: 接着我们向地址为216.93.246.15的STUN服务器执行同样操作: 我们看到Binding Response包MAPPED-ADDRESS属性里包含了客户端映射到公网的IP地址以及端口。上图可知两个STUN服务器返回的客户端映射到公网的端口不一样,说明客户端现在位于对称型NAT后,无法进行打洞。 四种主要NAT类型中有三种是可以使用STUN进行穿透:完全圆锥型NAT、受限圆锥型NAT和端口受限圆锥型NAT,对称型NAT则不能使用,原因前面也说到了。 TURN TURN(Traversal Using Relay NAT,通过Relay方式穿越NAT),是一种数据传输协议。允许通过TCP或UDP方式穿透NAT或防火墙。TURN是一个Client/Server协议。TURN的NAT穿透方法与STUN类似,都是通过取得应用层中的公网地址达到NAT穿透。但实现TURN client的终端必须在通讯开始前与TURN server进行交互,并要求TURN server产生"relay port",也就是relayed-transport-address。这时TURN server会建立peer,即远端端点(remote endpoints),开始进行中继(relay)的动作,TURN client利用relay port将数据传送至peer,再由peer转传到另一方的TURN client。 TURN主要用在使用STUN无法穿透的场景下,例如前面说到的对称型NAT,只能通过TURN server进行数据中转。 ICE ICE(Interactive Connectivity Establishment,互动式连接建立)。ICE定义了穿越方法而不是协议。ICE整合了STUN与TURN。ICE使得两个NAT后的端点通信更加便捷。ICE使用STUN进行打洞,若失败,则使用TURN进行中转。 下面我们举个应用场景,说下ICE的大概流程。 场景 如下图的应用场景,用户Alice要与Bob进行通信,这两个用户都位于NAT后,公网部署了STUN与TURN服务器。 收集候选地址(candidate) 首先客户端要收集candidate。candidate表示候选地址,由IP地址与端口组成。收集的candidate要与对方的candidate组成candidate pair,进行连通性检查。candidate主要有三种: Host candidate(host):从本地网卡上获取的地址 Server reflexive candidate(srflx):STUN server 观察的该客户端的地址 Relay reflexive candidate(relay):TURN server 为该客户端分配的中继地址 客户端通过向STUN服务器发送STUN数据包,STUN服务器做出回应,告知其在数据包中监测到的IP地址以及端口。 下图中,Alice与Bob通过STUN以及TURN服务器收集了三种类型的candidate。 连通性检查 收集candidate后把通过信令offer与answer方式双方交换candidate,进行candidate两两配对,然后ICE连通性检查。这个连通性检查按一定规则的。 本地的candidate与远端candidate构成的每一对都有一定的优先级,按优先级排序进行连通性检查。 数据传输 最后从有效的candidate组合中选择优先级最高的作为传输地址,用于数据传输。 Trickle ICE 在WebRTC中使用ICE框架进行P2P通信。前面说到ICE中第一步是收集candidate,需要遍历STUN以及TURN服务器,这一步需要耗费很多时间,导致双方建立通信时间很慢。为了解决这一问题,WebRTC引入了Trickle ICE,这样candidate收集以及连通性检查可以同时进行,加快双方建立通信的速度。 libnice库 若要让我们的程序支持ICE,我们可以借助第三方库。常见的支持ICE的库有Libjingle,Libnice。Libjingle集成在WebRTC里,不方便独立使用,这里我们推荐使用Libnice,常见的WebRTC服务器,例如janus,licode都是使用libnice进行P2P通信,具体可访问Libnice官网了解。 总结 本文主要介绍了NAT穿透技术,几种NAT类型,最后介绍了NAT穿透最常用的方案:ICE。通过本文,希望大家对音视频P2P传输中的NAT穿透有一定了解。 参考 [1] P2P技术详解(一):NAT详解——详细原理、P2P简介.http://www.52im.net/forum.php?mod=viewthread&tid=50&highlight=p2p. [2] 网络地址转换.https://zh.wikipedia.org/zh-hans/网络地址转换. [3] Trickle ICE.https://tools.ietf.org/html/draft-ietf-ice-trickle-21.