基于SFU架构的视频会议系统中,Simulcast是最主流的带宽自适应方案。发布端(Publisher)同时编码并发送多路不同分辨率的流(通常为小、中、大三路),订阅端(Subscriber)则根据自身网络带宽、设备性能、窗口大小等因素,选择订阅最合适的单路流。这种设计发布端与订阅端互不干扰:
- 发布端仅受自身上行带宽和编码负载影响
- 订阅端仅受自身下行带宽,解码能力,显示窗口影响
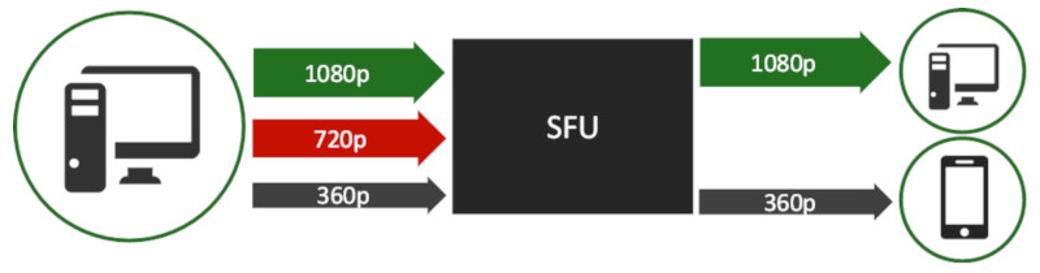
但在实际生产环境中,某些核心场景却需要订阅端能够“反向影响”发布端,即实现backpressure(反压)机制。
反压需求场景
按需推流
当会议中所有订阅端都处于小窗口显示(如宫格数较多、缩略图模式)时,大家只会订阅小流。此时发布端若仍持续推送大流,就会造成巨大的上行带宽浪费和服务器转发压力。理想状态是:订阅端集体选择小流 → SFU 通知发布端自动降档,只推小流即可。
SFU模拟点对点(P2P)通话
用SFU统一实现1对1通话(便于后续扩展多人)。此时必须达到原生P2P(ICE直连)的体验。
- 订阅端网络恶化时,不能仅靠切换Simulcast层(因为只有一层流),而应直接让发布端降低编码码率/分辨率
- 订阅端网络恢复后,发布端也要快速回升
在传统Simulcast中做不到这样的“端到端拥塞控制”。
SFU如何实现订阅端反压
核心思路:在SFU内部为每个发布源(Source)和每个订阅接收器(Sink) 建立反馈通道,让订阅客户端的带宽估计结果能够传递到发布客户端。
下面是实现原理图:
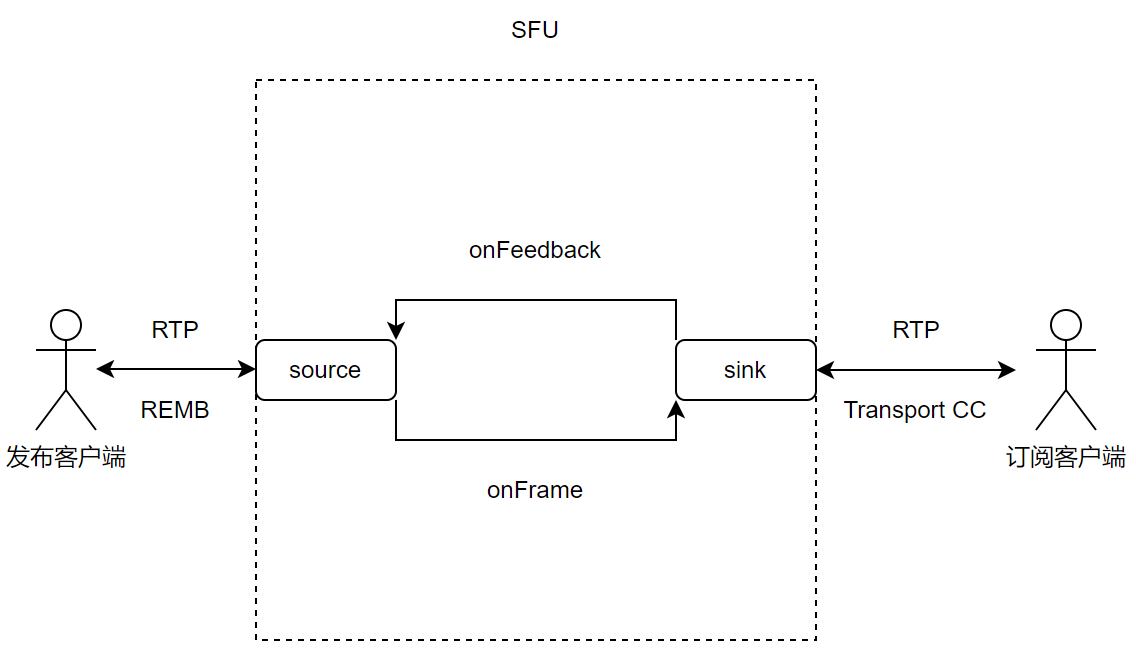
- 发布客户端 → RTP → SFU Source(发布源)
- SFU Sink(订阅接收器)收到订阅端发来的 Transport-CC报文,进行下行带宽估计
- Sink通过
onFeedback接口将估计带宽值传递给对应的Source - Source封装REMB(Receiver Estimated Maximum Bitrate)RTCP报文,传回到发布客户端
- 发布客户端收到REMB后,强制限制自身带宽估计值
这样就实现了订阅端 → SFU → 发布端的完整反压闭环。
REMB RTCP报文复用
WebRTC早期就内置了REMB RTCP,用在最早的接收端带宽估计中,接收端的带宽估计就是通过REMB反馈到发布端。虽然现在是Transport-CC + Sendside BWE,但REMB仍然被支持。这里可以看下REMB报文格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Receiver Estimated Max Bitrate (REMB) (draft-alvestrand-rmcat-remb). // // 0 1 2 3 // 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 // +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ // |V=2|P| FMT=15 | PT=206 | length | // +=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+ // 0 | SSRC of packet sender | // +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ // 4 | Unused = 0 | // +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ // 8 | Unique identifier 'R' 'E' 'M' 'B' | // +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ // 12 | Num SSRC | BR Exp | BR Mantissa | // +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ // 16 | SSRC feedback | // +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ // : ... |
对于SFU,带宽反馈处理只需在 Source 侧调用:
|
1 2 3 4 5 6 7 8 9 10 11 |
// Sink带宽估计后调用 void Sink::OnBandwidthEstimate(DataRate estimate) { source_->OnFeedback(estimate); // 通知对应的的Source } // Source收到后下发REMB void Source::OnFeedback(DataRate bandwidth) { if (publisher_session_) { publisher_session_->SendRtcpREMB(bandwidth); } } |
发布客户端中WebRTC收到REMB后的处理如下:
|
1 2 3 4 5 6 |
// Call when we receive a RTCP message with TMMBR or REMB. void SendSideBandwidthEstimation::UpdateReceiverEstimate(Timestamp at_time, DataRate bandwidth) { receiver_limit_ = bandwidth.IsZero() ? DataRate::PlusInfinity() : bandwidth; ApplyTargetLimits(at_time); } |
至此我们完成初步的反压实现。
遗留问题:弱网解除后带宽恢复速度慢
前面实现后还有个问题,就是订阅端弱网恢复后,恢复之前码率较慢。原因如下:
- 订阅端之前带宽差 → SFU反馈低REMB → 发布端码率被压得很低
- 订阅端网络恢复 → 其BWE想提升,但实际收到的码率仍然很低(受发布端限制)
- 订阅端BWE探测不到更高带宽 → 继续反馈低REMB → 发布端无法提升 → 形成“死循环”
这就像“受制于人”,恢复速度远慢于原生的P2P实现。
这时候我们可以在SFU的Sink(下行)侧中,主动注入探测流量,也就是引入探测(Padding)包。让订阅端能够获得额外码率进行更大带宽探测,打破死循环,加快恢复到之前码率。
总结
通过以上机制,SFU不仅保留了Simulcast的灵活性,还具备了端到端拥塞控制能力,让视频会议在复杂网络环境下也能提供接近原生P2P的流畅体验。

Comments