有时候我们开发一个流媒体系统,做完了却不知道如何用数字描述我们的系统,体现我们的优势,作为客户来说,可以描述这套系统的数字指标是最直观的,尤其在网络性能这块。在流媒体网络中,影响流媒体服务质量(QOS)的因素有很多,而这些因素可以作为我们衡量流媒体网络性能的指标。
衡量流媒体网络性能的常见指标主要有:
- 带宽
- 吞吐量
- 延时
- 抖动
- 丢包率
本篇文章主要讲下抖动(jitter),以及如何处理抖动,本文主要针对语音通信。在网络中,每个包从发送端到接收端的时延是不相同的,而jitter就是用来衡量这种不同。在发送端数据包发送时间间隔是相同的,也就是均匀发送数据,但是由于各种情况,例如拥塞,因为网络错误导致的丢包等,接受端收到数据包间隔就会不一样了,可能一会大,一会小,这就是所谓的抖动,严重影响音质。

下面先了解下传统学术上的相关定义。
- 延时:记
s(i),r(i)分别为第i个包的发送、接收时间戳,延时d(i) = r(i) – s(i) - 抖动:
jitter(i) = d(i+1) – d(i)
传统定义中,抖动仅能描述某个时刻的情况,而流媒体是持续的,我们更关注某个时间段上的情况,对比某时刻情况更实用。
为了更好描述某个时间段的抖动,我们按如下定义更实用的抖动指标(参考声网):
1)记s(i), r(i)为第i个包的发送与接收时间戳,延时d(i) = r(i) – s(i);
2)t秒为一个统计周期,集合D = {d(i) | i ∈ t秒内收到的包序号集合 };
3)对集合D做从小到大排序,得到D(sorted);
4)对D(sorted)中每个元素,减去D中最小值min(D),得到新的集合 D(jitter)。
现在D(jitter)中元素含义就是,t秒内所有语音数据包传输延时,相对最快那个数据包的偏移,原来抖动定义是相对前一个包延时偏移。可知D(jitter)中最大元素表示传输延时最大的。
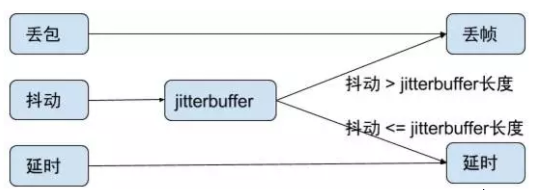
为了消除抖动,接收端要么丢帧,要么延时。一般都会引入一个缓冲区,也就是抖动缓冲(jitterbuffer)。引入了抖动缓冲后,我们可以这样处理抖动:
1)jitter > jitterbuffer length,丢帧处理;
2) jitter <= jitterbuffer length,延时处理。
所以现在D(jitter)中最大元素表示:如果jitterbuffer大小拉长到这个值,就能成功播放t秒内收到的语音数据。按这个定义,我们就可以动态设置我们的jitterbuffer大小,每一个t时间周期调整一次jitterbuffer。
如果想对抖动缓冲有更深入学习,可以参考WebRTC源码以及谷歌学术上相关论文,相关研究很多。

Comments
这样虽然可以处理部分的情况,但一旦出现了输入端的错误,就会导致累计误差的出现了,就是原本的输入里面在某些摄像机上回出现pts或者dts混乱,这个问题会出现,累计误差出现。
@zoring
这个主要针对语音通信的,视频肯定不能这么处理。还有摄像机一般没有B帧,pts与dts是一样的,只要确保时间戳是递增的就可以。接收端这边肯定会有个缓存,你push进缓存时,按照时间戳排序就可以了,就不会受输入端错误影响。
香川県さぬき市長尾 ルーちゃん餃子のフジフーヅは入ったばかりのバイトにパワハラの末指切断の大けがを負わせた犯罪企業.中卒社員岸下守(現在 鏡急配勤務)の犯行.
记s(i), r(i)为第i个包的发送与接收时间戳,延时d(i) = r(i) – s(i);
这个发送和接收时间戳来自于不同的时钟,怎么计算的d(i) 结果准确性?
好厉害