前面文章WebRTC研究:包组时间差计算-InterArrival讲到了相关包组时间差计算,输出包组发送时间差,到达时间差等参数。本篇文章主要介绍下这些参数在判断网络拥塞情况方面的应用。
到达时间模型
在WebRTC研究:包组时间差计算-InterArrival说到了到达时间模型,主要包含几个包组时间差计算的概念:
- 到达时间差:\(t_{i} - t_{i-1}\)
- 发送时间差:\(T_{i} - T_{i-1}\)
- 时延变化:\(d_{i} = t_{i} - t_{i-1} - (T_{i} - T_{i-1})\)
这个时延变化用于评估时延增长趋势,判断网络拥塞状况。在[1]中,这个时延变化叫做单向时延梯度(one way delay gradient)。那这个时延梯度为什么可以判断网络拥塞情况呢?
时延梯度计算
首先我们通过一张图看下时延梯度的计算:
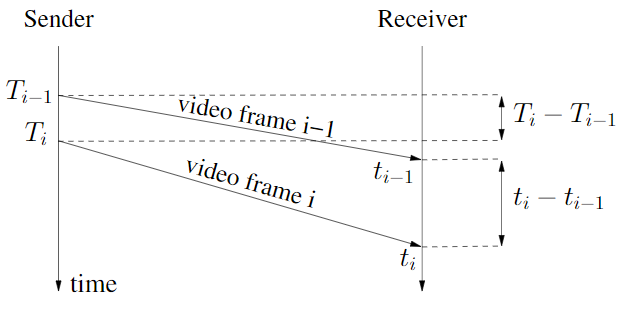
对于两个包组:\(i\)以及\(i-1\),它们的时延梯度:
\[ d_{i} = t_{i} - t_{i-1} - (T_{i} - T_{i-1}) \tag{1}\]
判断依据
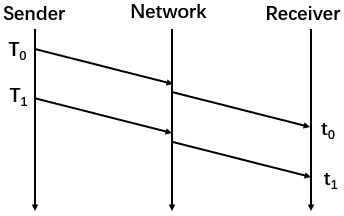
网络无拥塞的正常情况下:
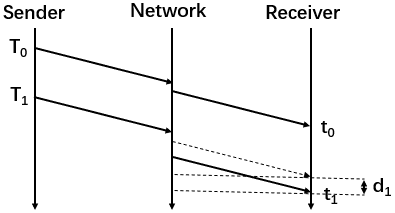
网络拥塞情况下:
第一张图是没有任何拥塞下的网络传输,时延梯度
\[d_{1} = t_{1} - t_{0} - (T_{1} - T_{0}) = 0\]
第二张图是存在拥塞时的网络传输,包在\(t_{1}\)时刻到达,因为网络发生拥塞,导致到达时间比原本要晚,原本应在虚线箭头处时刻到达,时延梯度
\[d_{1} = t_{1} - t_{0} - (T_{1} - T_{0}) > 0\]
由上可知,正常无拥塞情况下,包组间时延梯度等于0,拥塞时大于0,我们可以通过数学方法估计这个时延梯度的变化情况评估当前网络的拥塞情况,这个就是WebRTC基于时延的带宽估计的理论基础。
线性回归
WebRTC用到了线性回归这个数学方法进行时延梯度趋势预测。通过最小二乘法求得拟合直线斜率,根据斜率判断增长趋势。
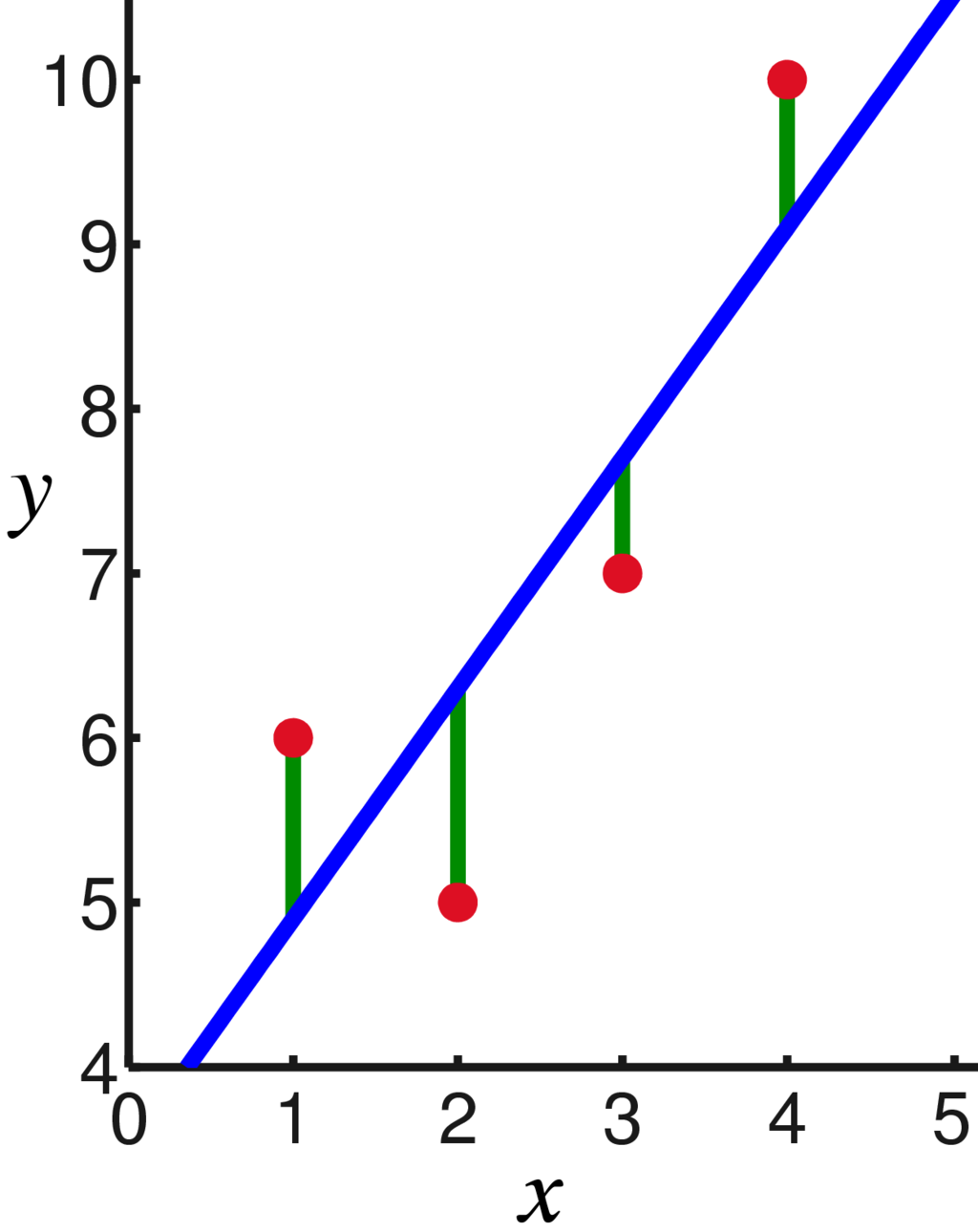
对于一堆样本点\((x,y)\),拟合直线方程\(y=bx+a\)的斜率\(b\)按如下公式计算:
\[b= \frac{\sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{\sum_{i=1}^{n}(x_{i}-\bar{x})^{2}}\tag{2} \]
网络状态
在WebRTC中,定义了三种网络状态:normal,overuse,underuse,用于表示当前带宽的使用情况,具体含义跟单词本身含义一样。
例如如果是overuse状态,表示带宽使用过载了,从而判断网络发生拥塞,如果是underuse状态,表示当前带宽未充分利用。后面会介绍如何根据时延梯度增长趋势得到当前的网络状态。
代码导读
由TrendlineEstimator类实现。主要接口就一个:UpdateTrendline。传入包组时间差,时间,包大小等参数,判断当前网络状态。
|
1 2 3 4 5 |
void UpdateTrendline(double recv_delta_ms, double send_delta_ms, int64_t send_time_ms, int64_t arrival_time_ms, size_t packet_size); |
说下输入的各个参数的含义:
recv_delta_ms:包组接收时间差send_delta_ms:包组发送时间差send_time_ms:当前处理的RTP的包发送时间arrival_time_ms:当前处理的RTP的包到达时间packet_size:当前处理的RTP包的大小
内部相关函数调用如下:
|
1 2 3 4 5 6 7 |
TrendlineEstimator::UpdateTrendline ↓ LinearFitSlope ↓ TrendlineEstimator::Detect ↓ TrendlineEstimator::UpdateThreshold |
下面结合代码说下UpdateTrendline函数内部计算过程。
1)计算时延变化累积值:
|
1 2 3 4 5 6 7 8 |
// 时延变化:接收时间差 - 发送时间差 const double delta_ms = recv_delta_ms - send_delta_ms; ++num_of_deltas_; num_of_deltas_ = std::min(num_of_deltas_, kDeltaCounterMax); if (first_arrival_time_ms_ == -1) first_arrival_time_ms_ = arrival_time_ms; // 累积时延变化 accumulated_delay_ += delta_ms; |
2)根据1)中的时延累积值计算得到平滑后的时延:
|
1 2 |
smoothed_delay_ = smoothing_coef_ * smoothed_delay_ + (1 - smoothing_coef_) * accumulated_delay_; |
3)将从第一个包到达至当前RTP包到达的经历时间,平滑时延值存到双端队列delay_hist_中:
|
1 2 3 |
delay_hist_.push_back(std::make_pair( static_cast<double>(arrival_time_ms - first_arrival_time_ms_), smoothed_delay_)); |
4)当队列delay_hist_大小等于设定的窗口大小时,开始进行时延变化趋势计算,得到直线斜率,直线横坐标为经历时间,纵坐标为平滑时延值:
|
1 2 3 4 5 6 |
if (delay_hist_.size() == window_size_) { // 0 < trend < 1 -> 时延梯度增加 // trend == 0 -> 时延梯度不变 // trend < 0 -> 时延梯度减小 trend = LinearFitSlope(delay_hist_).value_or(trend); } |
5)通过计算得到的时延变化趋势拟合直线斜率,发送时间差,到达时间判断网络状态:
|
1 |
Detect(trend, send_delta_ms, arrival_time_ms); |
LinearFitSlope函数
使用最小二乘法求解线性回归,得到时延变化增长趋势的拟合直线斜率。
看下内部代码实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
absl::optional<double> LinearFitSlope( const std::deque<std::pair<double, double>>& points) { RTC_DCHECK(points.size() >= 2); // 所有节点(x,y),x,y值分别求和 double sum_x = 0; double sum_y = 0; for (const auto& point : points) { sum_x += point.first; sum_y += point.second; } // 求平均值 double x_avg = sum_x / points.size(); double y_avg = sum_y / points.size(); // 根据公式:斜率 k = sum (x_i-x_avg)(y_i-y_avg) / sum (x_i-x_avg)^2 double numerator = 0; double denominator = 0; for (const auto& point : points) { numerator += (point.first - x_avg) * (point.second - y_avg); denominator += (point.first - x_avg) * (point.first - x_avg); } if (denominator == 0) return absl::nullopt; return numerator / denominator; } |
Detect函数
该函数主要根据时延变化增长趋势计算当前网络状态,在WebRTC旧版GCC算法,接收端基于时延的带宽预测代码中,这部分属于过载检测器的内容,跟在卡尔曼滤波后面,我们不做讨论,我们讨论的全部是最新代码,全部在发送端进行带宽预测。
在Detect函数内部,会根据前面计算得到的斜率得到一个调整后的斜率值:modified_trend:
|
1 2 3 |
// 乘以包组数量以及阈值增益,因为计算得到的trend常常是一个非常小的值 const double modified_trend = std::min(num_of_deltas_, kMinNumDeltas) * trend * threshold_gain_; |
然后与一个动态阈值threshold_做对比,从而得到网络状态
modified_trend > threshold_,且持续一段时间,同时这段时间内,modified_trend没有变小趋势,认为处于overuse状态modified_trend < -threshold_,认为处于underuse状态-threshold_ <= modified_trend <= threshold_,认为处于normal状态
如下图所示,上下两条红色曲线表示动态阈值,蓝色曲线表示调整后的斜率值,阈值随时间动态变化,调整后的斜率值也动态变化,这样网络状态也动态变化。
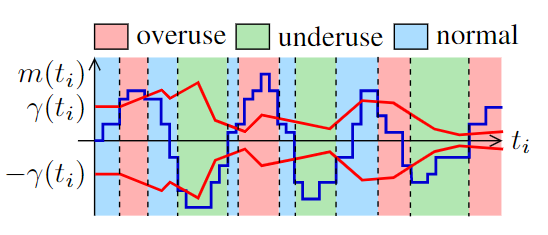
本图截取自文末参考[1],倒数第三个状态应为normal,不是overuse
相关实现代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
if (modified_trend > threshold_) { if (time_over_using_ == -1) { time_over_using_ = ts_delta / 2; } else { time_over_using_ += ts_delta; } overuse_counter_++; // 满足modified_trend > threshold_状态的持续时间必须大于overusing_time_threshold_ if (time_over_using_ > overusing_time_threshold_ && overuse_counter_ > 1) { // 当前计算得到的斜率值trend不能小于之前得到的的斜率值 // 斜率值变小说明overuse程度减轻,网络情况变好,不认为处于kBwOverusing if (trend >= prev_trend_) { time_over_using_ = 0; overuse_counter_ = 0; hypothesis_ = BandwidthUsage::kBwOverusing; } } // modified_trend < -threshold_,认为处于underuse状态 } else if (modified_trend < -threshold_) { time_over_using_ = -1; overuse_counter_ = 0; hypothesis_ = BandwidthUsage::kBwUnderusing; // threshold_ <= modified_trend <= threshold_,认为处于normal状态 } else { time_over_using_ = -1; overuse_counter_ = 0; hypothesis_ = BandwidthUsage::kBwNormal; } |
这个阈值threshold_是动态调整的,代码实现在UpdateThreshold函数中。
UpdateThreshold函数
阈值threshold_动态调整为了改变算法对时延梯度的敏感度。根据[1]主要有以下两方面原因:
1)时延梯度是变化的,有时很大,有时很小,如果阈值是固定的,对于时延梯度来说可能太大或者太小,这样就会出现检测不够敏感,无法检测到网络拥塞,或者过于敏感,导致一直检测为网络拥塞;
2)固定的阈值会导致与TCP(采用基于丢包的拥塞控制)的竞争中被饿死。
这个阈值根据如下公式计算:
\[ \gamma(t_{i})=\gamma(t_{i-1})+\Delta T \cdot k_{\gamma }(t_{i})(|m(t_{i})|-\gamma (t_{i-1})) \tag{3}\]
每处理一个新包组信息,就会更新一次阈值,其中\(\Delta T\)表示距离上次阈值更新经历的时间,\(m(t_{i})\)是前面说到的调整后的斜率值modified_trend。
\(k_{\gamma }(t_{i})\)按如下定义:
\[
k_{\gamma }(t_{i}) =
\begin{cases}
k_{d}&|m(t_{i})|\lt\gamma (t_{i-1})\\
k_{u}&{\text{otherwise}}\\
\end{cases}\tag{4}
\]
\(k_{d}\)与\(k_{u}\)分别决定阈值增加以及减小的速度。
具体实现代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
void TrendlineEstimator::UpdateThreshold(double modified_trend, int64_t now_ms) { // kγ(ti)值:kd,ku const double k = fabs(modified_trend) < threshold_ ? k_down_ : k_up_; const int64_t kMaxTimeDeltaMs = 100; // 距离上一次阈值更新经过的时间∆T int64_t time_delta_ms = std::min(now_ms - last_update_ms_, kMaxTimeDeltaMs); threshold_ += k * (fabs(modified_trend) - threshold_) * time_delta_ms; threshold_ = rtc::SafeClamp(threshold_, 6.f, 600.f); last_update_ms_ = now_ms; } |
总结
本文主要介绍了如何根据时延梯度得到网络状态,判断网络拥塞状况,并结合WebRTC相关源码进行分析。当我们得到当前网络拥塞状况后,就要对发送码率进行调节,以适应当前网络。后续文章我们将研究如何根据网络状态进行相应码率调整。
参考
[1] Analysis and Design of the Google Congestion Control for Web Real-time Communication (WebRTC).http://dl.acm.org/ft_gateway.cfm?id=2910605&ftid=1722453&dwn=1&CFID=649873557&CFTOKEN=47458294.
[2] A Google Congestion Control Algorithm for Real-Time Communication draft-ietf-rmcat-gcc-02.https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02.

Comments
您好,想请教您三个问题:
1.我不太理解overuse_detect监测中,为什么过载的判断要有trend >= prev_trend_,也就是说即使过载时间超过阈值,但本次trend没有比上次大,也不认为是过载吗?按代码逻辑来看,是等于上一次的监测状态不变?
2.threshold_gain_是做什么用的,我看代码里是4.0,不太理解这个数是怎么来的……
3.您贴的这个overuse状态机变化图,倒数第三个颜色块(倒数第二个红块)为什么是overuse状态呀,不应该是normal吗?
如果您能解答一下我的疑惑,非常感谢呀,我总感觉自己半懂不懂的……
@doggie77 你这些问题问得非常好。针对你的问题,我完善了下文章内容。这里也顺便回答下:
1)本次trend没有比上次大,说明网络状况在变好,认定不是overuse
2) threshold_gain_应该翻译为阈值增益,相当于放大这个trend值,如果你跑过代码,你会发现这个trend一般都非常小
3)这图倒数第三个色块确实有误,我是从文末参考链接的那篇论文截的图,确实是normal状态
@Jeff 哈哈,谢谢解答。
你好,我这边看modified_trend的计算公式,这个参数计算过程中需要乘以num_of_deltas_是不是也是考虑到了时间意义上的变化?
@lingjzhang
std::min(num_of_deltas_, kMinNumDeltas),跟时间没关系,最后也相当于一个gain了我个人一直很好奇threshold_gain_参数为4的原因到底是什么?为什么不可以是其他的数字?单纯从kalman和trendline上的应用看,是不是和kalman的结果有关系?
@lingjzhang 请注意:
threshold_ = rtc::SafeClamp(threshold_, 6.f, 600.f),threshold_gain_配置为4,除了考虑到这个,也考虑到工程实践测试结果,当然你也可以配置为其他参数,可以不同网络仿真对比结果。WebRTC中很多参数都是大量工程实践得到的经验值。@jeff,理解了,谢谢。
这个modified_trend到底是啥,它后面的思想是什么,从表面上可以理解成一个预估的trend经过变换后和threashold进行比较吗,但是内里的思想是什么
我大致能够理解,这个modified_trend背后的设计了,我觉得是这样子的,有两个关键的地方:
(1) 在做trendline之前,会去计算delta,这个delta的取样点所属于一个group的时间范围是100ms,详见变量kMaxBurstDuration
(2) 后文thread_shold做更新的时候,更新过程是这样子的:
const double k = fabs(modified_trend) < threshold_ ? k_down_ : k_up_;
const int64_t kMaxTimeDeltaMs = 100;
int64_t time_delta_ms = std::min(now_ms - last_update_ms_, kMaxTimeDeltaMs);
threshold_ += (1- k*time_delta_ms) *threshold_ + k * time_delta_ms * fabs(modified_trend);
threshold_ 的更新过程乘以了一个系数time_delta_ms,这个值为(now_ms - last_update_ms_, kMaxTimeDeltaMs)两者中的最小值, kMaxTimeDeltaMs的值也是100,其实它就是代表一个BurstDuration的值,所以这个时候modify_trend就好理解了,因为threashold_的更新考虑到time_delta_ms这个因素,所以modify_trend要把num_of_deltas_给考虑上
modified_trend = std::min(num_of_deltas_, kMinNumDeltas) * trend * threshold_gain_;
@sshsu 没太明白 你得意思是一个负反馈意思么 ,因为阈值计算跟包组数有关系 ,所以修改后trend也需要乘以包组数? 这里面是个什么推论 k_down_ k_up得值实际工程中去调整 得化一般根据什么来调整 。
@5555 @5555 因为trend乘以包组数是认为以包组数为单位的延迟梯度去做比较能够平衡一些误差?阈值是果,是基于这样的设计而测试出来的工程值而已,然后朝着这个modified_trend收敛。k_down和k_up在Reference中的第一篇论文很详细的说了是怎么样测出来的,大概思路基于公平性和最大总码率做了一个凹函数,然后根据k_down, k_up做了一个梯度图,遍历得到目标函数的最大时的k_down和k_up
@sshsu 我也一直困惑于modified_trend的计算逻辑,现在还没弄清楚。
我的一点思路是:鉴于一旦检测出bandwidth usage的状态更新为overuse,那么发送码率会随之下调。因此GCC中对于overuse状态的检测做了一些脱敏处理,包括在modified_trend>threshold的基础上还附加了额外条件用于判定overuse状态。
因此,我觉得下面代码逻辑类似于一个low-pass filter,即低通滤波器,确保modified_trend一直处于低频状态,也相对于是一种脱敏操作。
modified_trend = std::min(num_of_deltas_, kMinNumDeltas) * trend * threshold_gain_;
当然,以上只是我的猜想而已,一起讨论。
在请教一个问题,为啥在做最小二乘法拟合的时候Y轴取值取的是累积延迟 smoothed_delay_ 而不是当前包组的时延变化delta_ms = recv_delta_ms - send_delta_ms 呢?
X轴的理解没有问题 每个包组的X轴坐标都是相对第一个包组的接收时间来算
@Jeffrey 我也有这个问题,不理解。
@yy @yy 这个我整明白了,X轴代表的是当前包组距离第一个包组的接收时间差,可以这么理解,将X轴看出是一个连续的时间T,Y轴代码单项延迟的累计值也就是用数学表达为S(位移或路程),斜率就是V,代码排队延迟的变化快慢程度
请教下,delay_hist_队列 是固定大小的哈?
大佬,请教下TransportFeedback一般是50ms-250ms发一次,但包组是5ms一个,我理解是只有部分包组参与带宽评估? 还是说TransportFeedback会把50ms内比如10个包的相关信息都反馈到发送端?
@Kincaid 自解了 packet status count会说有几个包的信息。
https://mp.weixin.qq.com/s?__biz=MzU3MTUyNDUzMA==&mid=2247483998&idx=1&sn=c1c9d26bc0fefe67b893790449015139&chksm=fcdf9683cba81f9573cab9ced0e271d6b1db4a0fbb04d12325bfdccf0e00dd32cdaa5bdff18d&scene=178&cur_album_id=1345116764509929473#rd
大佬我又来提问了,最近在看这个论文,原文中提到如下
Figure 9 (b) shows that, with the adaptive threshold, γ(t) follows m(t) with a slower time constant
and, when m(t) overshoots γ(t), the delay-based algorithm can decrease the sending rate. Moreover, since ku > kd the threshold is increased quicker than how it is decreased
我一直没整明白,为啥ku要大于kd,意图是啥,能否帮忙理解一下