买的主机停了将近10天,以前一些文章排名都没了。垃圾主机商,被攻击了,要快10天才能搞好,又不给取出数据,恒创主机,垃圾。


elst全称Edit List Box,mp4文件中不一定都含有这个box。该box作用是使某个track的时间戳产生偏移。 结构 在ISO_IEC_14496-12中,elst结构定义如下: segment_duration:表示该edit段的时长,以Movie Header Box(mvhd)中的timescale为单位。 media_time:表示该edit段的起始时间,以track中Media Header Box(mdhd)中的timescale为单位。如果值为-1,表示是空edit,一个track中最后一个edit不能为空。 media_rate:edit段的速率为0的话,edit段相当于一个"dwell",即画面停止。画面会在media_time点上停止segment_duration时间。否则这个值始终为1。 例子 现在我们手里有个mp4文件,我们要让封装的视频延迟10秒才开始显示,封装的音频不变,这个可以通过修改视频的时间戳实现,将视频的所有时间戳都加上10秒,但是一个个改太麻烦了,此时elst就派上用场了,我们要通过它让视频时间戳偏移10秒。 下面我们先动手操作番,了解elst如何起作用。 1)找一个没有elst box的mp4文件:test.mp4,假设我放在D:\\bin目录下。至于mp4有没有包含elst可以用文章末尾链接提供的mp4分析工具Mp4Reader分析下。用mediainfo查看该视频的信息: 该mp4音视频时长都为3分32秒。 2)得到带elst的mp4。到https://gpac.wp.mines-telecom.fr/mp4box/ 下载windows下的mp4box,按提示一步步安装。 打开windows cmd命令行,cd到test.mp4目录,然后敲入Mp4Box的命令: [crayon-69ea0e1ef3936615205474/] 得到: 由此可知test.mp4中,视频的track id 为1,音频track id为2。 3)接着我们敲如下命令: [crayon-69ea0e1ef3942601557443/] 由于我们只对视频操作,视频track id是1,所以是#1:delay=10000。得到: 此时在bin目录下会生成一个delay_10s.mp4,该mp4中视频track延迟了10秒,音频track不变。mediainfo查看delay_10s.mp4信息: 可以看到视频的时长多了10秒 4)打开mp4reader查看视频track的elst信息: 也就是: [crayon-69ea0e1ef3946158485676/] 可以看到有两个elst entry,第一个为空,Segment-duration为6000,由于timescale为600(该timescale在mvhd中获 得),6000除以timescale刚好为10秒。由此可知我们要延迟播放某个track,可以在elst中插入一个空的entry,Segment-duration设置为需要延迟播放的时间,Media-Time设置为-1,然后在插入一个entry,Segment-duration设置为正常播放时间,Media-Time也就是起始时间设置为0。 5)播放器验证。我们使用vlc播放器打开delay_10s.mp4: 前10秒视频没有播放,而声音正常播放,到第10秒时视频才开始播放,等声音播放结束后,视频还会播放10秒,可以看出视频确实是推迟了10秒播放,此时音视频已经不同步了。 不是所有的播放器都支持elst的,我测试了下,vlc与potplayer支持,windows自带播放器就不支持。 ffmpeg相关代码分析 下面结合ffmpeg中相关代码以及上面的视频延迟10秒的例子分析,看ffmpeg中对elst数据如何处理。ffmpeg中elst entry数据存放在MOVElst 结构体中: [crayon-69ea0e1ef3949792217193/] duration对应mp4标准中的segment_duration time对应mp4标准中的media_time 在ffmpeg源码libavformat\mov.c中的mov_build_index函数中有如下代码: [crayon-69ea0e1ef394c306352688/] 第8行代码中可以知道,如果e->time == -1,也就是第一个elst为空,此时得到empty_duration,按前面的例 子该值为10*timescale,下一个for循环得到start_time =e->time,值为0。 在第26行代码中,可知sc->time_offset =0 -10*timescale = -10timescale,然后所有dts都要减去该sc->time_offse,最后结果是都加上10timescale,与原来时间戳比相当于延迟了10s。所以当mp4存在elst时,dts要按如下计算: 1.参考上述ffmpeg代码得到time_offset 2.解码时间戳dts = sample_delta * n – time_offset,其中sample_delta在stts中获得,如果存在B帧,还要从ctts中获得sample_offset,此时: 显示时间戳pts= dts+ sample_offset 否则pts = dts。 接下来我们使用ffmpeg验证下,打印出所有viedeo packet的dts与pts: 可以看到所有时间戳都偏移了230000,也就是10timescale,在video track的mdhd中可知timescale为23000,刚好是10timescale = 23000*10: 由此可知elst的作用就是使某个track时间戳偏移,达到延迟播放的效果。在我们解析mp4文件时,如果存在elst,一定要解析,然后配合stts与ctts,这样才可以得到正确的时间戳。 相关下载 Mp4Reader:https://pan.baidu.com/s/1cBC_yRR-BUfMGpUnC2LN8g
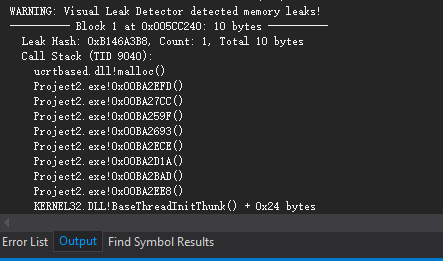
在测试自己写的程序时,我们一般都会去任务管理器查看程序内存状况,看内存是否随着时间一直增长,如果一直增长,那恭喜了,程序内存泄露了。 编写程序时要养成良好习惯,申请的内存要记得释放,遇到内存泄露时要认真查看申请的内存释放了没,除此之外,我们也可以通过第三方帮助我们发现程序内存泄露状况。 _CrtDumpMemoryLeaks函数 系统自带的 C Run-Time (CRT)库可以帮助我们检测内存泄露,使用很简单。 1)包含相应头文件 [crayon-69ea0e1f015da038149826/] 2)在程序退出地方,加上: [crayon-69ea0e1f015e4096051808/] 在调用_CrtDumpMemoryLeaks函数前我们要确保释放了该释放的内存,最后程序结束后在Output窗口就会打印出内存泄露信息。 3)如果我们程序有多个退出点,需要都添加上_CrtDumpMemoryLeaks函数,比较麻烦,此刻_CrtSetDbgFlag 函数就比较方便了。在程序初始化地方加上: [crayon-69ea0e1f015e7714215814/] 这个函数会在我们程序每个退出点自动执行_CrtDumpMemoryLeaks 函数。 对于如何定位内存泄露代码以及其他使用,可以看下MSDN上的介绍:https://msdn.microsoft.com/en-us/library/x98tx3cf.aspx。 Visual Leak Detector(VLD)插件 给我们的VS装上该插件,下载地址:https://vld.codeplex.com/,使用方法很简单,安装完插件后,在我们要检测的文件加上 [crayon-69ea0e1f015eb083806306/] 然后在debug模式下运行,在Output窗口即可查看详细泄露信息,其实该插件原理就是上一节说到的CRT库。比如我们下面一段测试代码: [crayon-69ea0e1f015ef488553392/] 上述代码我们注释掉了delete部分,debug运行结束后我们可以看到Output窗口显示泄露了10字节,同时打印出泄露的堆栈,如果程序复杂的话,我们可以在Output窗口双击泄露的堆栈定位到相应代码。 VS2015内存快照 在VS2015引入了强大的内存查看工具,在程序运行时,右侧窗口我们可以查看程序内存状况。通过截取某两个不同时刻的内存快照,进行对比,可以快速找到泄露部分。同样还是上面的测试代码,不过得注释掉include vld头文件这一行,我们按如下步骤定位泄露部分。 1)在LeakTest处打个断点,debug运行,在右侧窗口->Memory Usage标签页中启用Heap Profiling。 2)点击Take Snapshot,相当于一次拍照(这图标就是一个相机),此刻下面即可显示当前分配的内存大小,堆大小。 3)执行完测试函数后,我们再次点击Take Snapshot按钮,此刻提示了与上一次快照的变化。 4)点击括号处(+1)或(+0.04KB)变化部分链接。 5)在左侧窗口查看与前一次快照对比,具体什么数据造成内存变化。 6)双击后查看定义为char类型数据的具体实例,我们程序中只定义了一个char类型数据,所以只有一个实例,再双击某个实例可以定位到具体代码,同时查看相应堆栈调用,由于测试程序太简单了,所以这里看不到。 拿我以前写的一个复杂程序举例,程序中我定义了多个CString类型数据,点击查看CString数据具体实例。 我们可以看到多个CString数据实例,点击某个实例就可以看到堆栈调用了,双击具体的堆栈调用可以定位到具体代码。 详细使用可以参考微软官方博客:https://blogs.msdn.microsoft.com/vcblog/2015/10/21/memory-profiling-in-visual-c-2015/,我就不细说了。
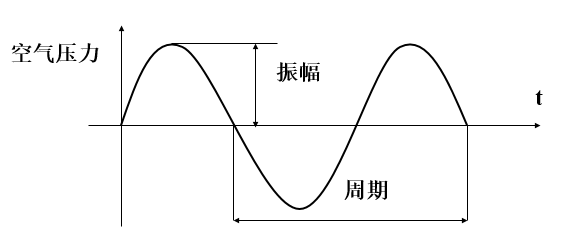
一、声音的相关概念 声音是介质振动在听觉系统中产生的反应。声音总可以被分解为不同频率不同强度正弦波的叠加(傅里叶变换)。 声音有两个基本的物理属性:频率与振幅。声音的振幅就是音量,频率的高低就是指音调,频率用赫兹(Hz)作单位。人耳只能听到20Hz到20khz范围的声音。 模拟音频(Analogous Audio),用连续的电流或电压表示的音频信号,在时间和振幅上是连续。在过去记录声音记录的都是模拟音频,比如机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式。 数字音频(Digital Audio),通过采样和量化技术获得的离散性(数字化)音频数据。计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。 采样频率(Sampling Rate),单位时间内采集的样本数,是采样周期的倒数,指两个采样之间的时间间隔。采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号,这其实就是著名的香农采样定理。CD音质采样率为 44.1 kHz,其他常用采样率:22.05KHz,11.025KHz,一般网络和移动通信的音频采样率:8KHz。 量化深度,表示一个样本的二进制的位数,即样本的比特数。量化是将经过采样得到的离散数据转换成二进制数的过程,量化深度表示每个采样点用多少比特表示,在计算机中音频的量化深度一般为4、8、16、32位(bit)等。例如:量化深度为8bit时,每个采样点可以表示256个不同的量化值,而量化深度为16bit时,每个采样点可以表示65536个不同的量化值。量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。CD音质采用的是16 bits,移动通信 8bits。 声道数,记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。使用双声道记录声音,能够在一定程度上再现声音的方位,反映人耳的听觉特性。 数字音频存储大小。采样频率、量化深度数越高,声音质量也越高,保存这段声音所用的空间也就越大。立体声(双声道)存储大小是单声道文件的两倍。即:文件大小(B)=采样频率(Hz)×录音时间(S)×(量化深度/8)×声道数(单声道为1,立体声为2) 如:录制1分钟采样频率为44.1KHz,量化深度为16位,立体声的声音(CD音质),文件大小为: 44.1×1000×60×(16/8)×2=10584000B≈10.09M 二、PCM 音频编码,指将模拟音频转换成数字音频并以某种格式存储的技术或过程。 PCM(Pulse Code Modulation)编码,即通过脉冲编码调制方法生成数字音频数据的技术或格式,是一种无损编码格式,是音频模拟信号数字化的一种方法,需要经过采样、量化和编码过程,以实现音频模拟信号数字化。 首先从6个方面描述PCM: 1)采样率; 2)符号:表示样本数据是否是有符号位,比如用一字节表示的样本数据,有符号的话表示范围为-128~127,无符号就是0~255,; 3)字节序:字节序分为大端与小端; 4)样本大小:决定了每个样本由多少位组成,即前面说到的量化深度,一般16位是最常见的; 5)声道数:分为单声道与双声道。 6)整形或浮点型:大多数格式的PCM样本数据使用整形表示,然而在一些对精度要求高的应用方面,使用浮点类型表示PCM样本数据。 打开ffmpeg,敲:ffmpeg -formats命令,获取ffmpeg支持的音视频格式,在这当中我们可以找到支持的PCM格式 [crayon-69ea0e1f02611071766930/] 比如DE s16be,就表示一个样本用16bits有符号的整形数据表示,字节序为大端。 假设我们有一个PCM signed 16-bit little-endian,双声道的PCM文件。如下是文件中前9个样本: [crayon-69ea0e1f0261a357247463/] 每个样本2字节,总共18字节,每个样本取值范围:-32768 ~ 32767。 三、PCM音量控制 通过前面描述我们对PCM有了个了解,知道了在PCM流中数据如何存储。下面我们先看一个真正的音频样本波形: 如果我们放大5倍波形,也就是振幅乘以5,此时我们听到了更大的声音,此时样本波形如下: 假如我们有2048bytesPCM数据,样本大小两个字节,共有1024个样本,我们要放大两倍声音,代码可以按如下写: [crayon-69ea0e1f0261e575646578/] 这是不是很简单,但是接下来我们还需要考虑两个方面的问题。 数据溢出 因为每个样本取值范围是有限制的,调节音量时不可能随便增大,比如一个signed 16 bits的样本,值为5000,我们放大10倍,由于有符号位16bits数据取值范围为-32768~32767,5000乘以10得到的50000超过了32767,数据溢出了,最后值可能变为-15536,不是我们期望的。此时我们就需要裁剪了,确保数值在正确范围内。如下代码对前面说到的放大两倍声音做了裁剪处理: [crayon-69ea0e1f02622074615418/] 对数描述 平时表示声音强度我们都是用分贝(db)作单位的,声学领域中,分贝的定义是声源功率与基准声功率比值的对数乘以10的数值。根据人耳的心理声学模型,人耳对声音感知程度是对数关系,而不是线性关系。人类的听觉反应是基于声音的相对变化而非绝对的变化。对数标度正好能模仿人类耳朵对声音的反应。所以用分贝作单位描述声音强度更符合人类对声音强度的感知。前面我们直接将声音乘以某个值,也就是线性调节,调节音量时会感觉到刚开始音量变化很快,后面调的话好像都没啥变化,使用对数关系调节音量的话声音听起来就会均匀增大。 如下图,横轴表示音量调节滑块,纵坐标表示人耳感知到的音量,图中取了两块横轴变化相同的区域,音量滑块滑动变化一样, 但是人耳感觉到的音量变化是不一样的,在左侧也就是较安静的地方,感觉到音量变化大,在右侧声音较大区域人耳感觉到的音量变化较小。 下面我们讲下音量值乘数取值,这里我只简单的用tan函数模拟,效果也不错,至于使用对数如何调整请参考文末链接: [crayon-69ea0e1f02625809733629/] 上面代码中音量乘数取值为tan (some_level / 100.0 ),最后实现代码如下: [crayon-69ea0e1f02629974333362/] 其中level取值需要具体测试实现,一般使用时level取值为某个范围的几个数,比如取10个数,这样音量就有10个阶跃可以调节。 如下图,最后声音音量近似按对数关系增长了: 如果想了解利用对数关系调节音量的具体实现,请参考: PCM音量控制(高级篇)
在做视频文件解析开发时,经常需要进行网络字节到本地字节的转换。在视频文件中,相关数据是以网络字节存储的,比如视频的宽,定义为uint_32类型,读取时我们需要转换为本地字节序才可以得到正确结果。 操作系统自带api可以帮助我们进行字节序的转换,如下所示函数与具体平台无关: [crayon-69ea0e1f037be290866120/] 我们也可以用c++函数模板实现一个,方便使用,我一般都是用自己的函数模板的: [crayon-69ea0e1f037c6324023898/]
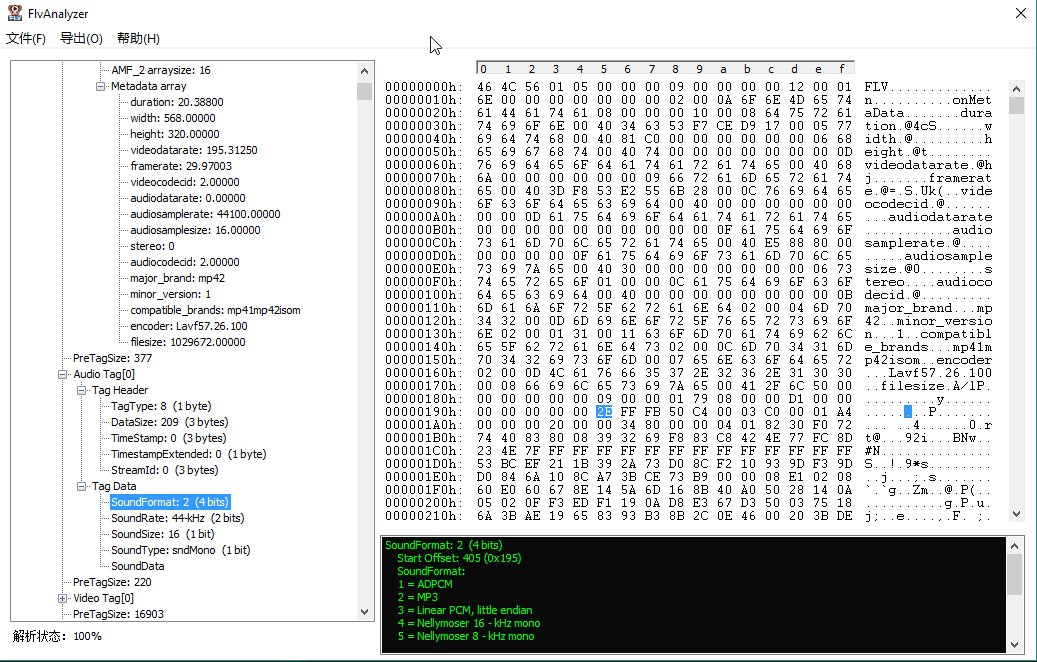
在学习视频文件的解析时,刚开始我都是用ultraedit配合标准文档查看,不是很方便,后来在网上看到了一个叫flvparse的程序,虽然做的很粗糙,但是为flv文件的学习提供了帮助。现在我自己对flv,avi,mp4文件都非常了解了。在业余时间也做了一个flv文件的分析程序,完全按照flv标准文档解析,每一个字段都清楚展示出来,可以说是网上最强大的一个flv分析工具了(应该是这样的,还没见过比这好的)。flv在流媒体领域应用很广泛的,想做流媒体,视频直播这一块的都得学习flv封装格式,所以希望这个工具对于那些初学者有所帮助。 为了不跟网上其他工具重名,就取了个FlvAnalyzer的名字,目前发布的是第一版。 FlvAnalyzer V1.0 目前支持如下功能: 1)左侧树状结构显示flv的文件结构信息,可以清楚了解flv文件的结构; 2)点击左侧节点,右侧显示对应hex与ascii信息,这样就不必打开二进制编辑器了; 3)详细显示audio tag与video tag各个字节(精确到bit)的详细信息,了解每个tag是如何构造的,同时右下角黑色输出框显示某个值的意义; 4)程序限制最大200M的文件内容显示,显示太多没必要。 如果遇到使用问题或希望改进的,欢迎提出,其他地方下载的遇到的问题概不负责。 -------------------------------------------------------------------------------------- FlvAnalyzer最新版下载地址:https://pan.baidu.com/s/1vmf6yuYAUh5nOk1CBXy8tQ 提取码: qiah 转眼4年多过去了,4年前业余时间写的工具发现用户挺多的,当然软件也有很多Bug,代码也有4年多没更新了,准备抽出时间开发第二版了,希望这款工具软件能帮助更多人。 -- 2020.08.17
现在VR是越来越火,VR全景视频在未来会有很大普及,颠覆人们传统看视频方式。目前VR视频都是将不同角度拍摄的视频进行拼接而成的,然后通过特定播放器播放。自己对这也很感兴趣,视频拼接目前还没实力搞,先打算做个全景视频播放器。目前思路如下: 1)获取拼接前的各个角度视频; 2)使用某个游戏引擎(比如unity)或者图像渲染引擎(OGRE,大学毕设用过)构造一个立体的物体,可以是球体,立方体,锥体等等; 3)解码之前获取的各个角度视频,然后映射到构造的立体物体上; 4)由于在游戏引擎的世界中我们可以360度浏览虚拟世界,我们将我们的相机放在前面构造的立体物体内,也就是从立体物体内部角度浏览,这样就可以浏览360度的全景视频了。
Recent Comments
Miles0u Published at 23 hours ago(04 04202643009 22 22pm26)
Addiea9 Published at 2 weeks ago(04 04202643001 08 08am26)
snail Published at 4 weeks ago(03 03202633105 27 27pm26)
dongxuh Published at 9 months ago(07 07202573103 27 27pm25)
南南 Published at 9 months ago(07 07202573103 15 15pm25)