开此文章用于记录自己编译WebRTC安卓Native code遇到的问题。 问题0x01 错误提示如下: [crayon-69e9a3fa757ef058085138/] 这个是在我执行build_aar.py --build-dir out --arch "armeabi-v7a" "arm64-v8a"命令编译生成aar文件遇到的。看了下目录, sdk/android/AndroidManifest.xml是存在的。后来发现是路径问题。得切到WebRTC源码/src目录下执行: [crayon-69e9a3fa757fb976765295/] 而我原来是在/tools_webrtc/android/里直接执行build_aar.py。 问题0x02 编译支持H264软编软解报的问题,之前编译都没问题,编译错误打印如下: [crayon-69e9a3fa75800544605913/] 问题出在generate_licenses.py里,WebRTC安卓H264启用openh264编码,ffmepg解码,很多地方得自己手动加进去,generate_licenses.py里openh264以及ffmpeg的license路径我之前没加,导致编译报如上错误,按如下修改即可: [crayon-69e9a3fa75803662386927/] 问题0x03 切换WebRTC到去年11月某个日期版本,同时也切换depot_toos到对应日期,执行gclient sync,然后重新执行build_aar.py编译出现如下错误: [crayon-69e9a3fa75807893140889/] 说无法创建Java Virtual Machine,解决方法,下面两个方法都试了,然后编译通过。也不知道哪个起作用,懒得折腾去验证了: [crayon-69e9a3fa7580b042487508/] [crayon-69e9a3fa7580e741846764/]

记录下今天编译WebRTC 安卓Native code遇到的一个问题。相关错误提示如下: [crayon-69e9a3fa777c7070591778/] 执行gclient sync命令后过一会儿报Failed to download错误,我用浏览器或者wget命令去下载一点问题都没。之前都没遇到过这问题。谷歌搜了下,发现有人遇到过类似问题,还都是国人,问题出在代理上,在有些代理环境下,gclient sync下的某些命令连接会失败。以前用SS(IP封得太厉害放弃了现在)就没遇到过,现在用的VPN走全局就遇到了,但是用其他方式是可以正常访问下载链接的。 后来换到国外的VPS上编译,一点问题都没。所以想顺利编译WebRTC安卓源码或Linux源码的话,最好买个国外的VPS编译,时间就是生命。
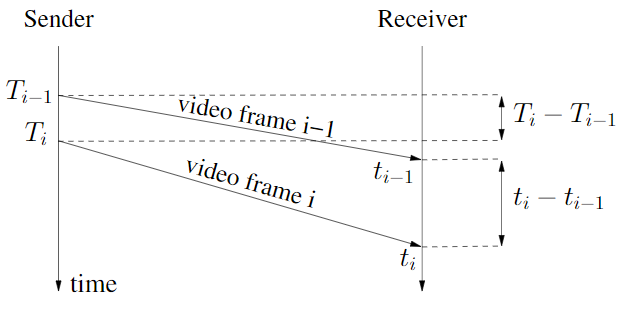
前面文章WebRTC研究:包组时间差计算-InterArrival讲到了相关包组时间差计算,输出包组发送时间差,到达时间差等参数。本篇文章主要介绍下这些参数在判断网络拥塞情况方面的应用。 到达时间模型 在WebRTC研究:包组时间差计算-InterArrival说到了到达时间模型,主要包含几个包组时间差计算的概念: 到达时间差:\(t_{i} - t_{i-1}\) 发送时间差:\(T_{i} - T_{i-1}\) 时延变化:\(d_{i} = t_{i} - t_{i-1} - (T_{i} - T_{i-1})\) 这个时延变化用于评估时延增长趋势,判断网络拥塞状况。在[1]中,这个时延变化叫做单向时延梯度(one way delay gradient)。那这个时延梯度为什么可以判断网络拥塞情况呢? 时延梯度计算 首先我们通过一张图看下时延梯度的计算: 对于两个包组:\(i\)以及\(i-1\),它们的时延梯度: 判断依据 网络无拥塞的正常情况下: 网络拥塞情况下: 第一张图是没有任何拥塞下的网络传输,时延梯度 第二张图是存在拥塞时的网络传输,包在\(t_{1}\)时刻到达,因为网络发生拥塞,导致到达时间比原本要晚,原本应在虚线箭头处时刻到达,时延梯度 由上可知,正常无拥塞情况下,包组间时延梯度等于0,拥塞时大于0,我们可以通过数学方法估计这个时延梯度的变化情况评估当前网络的拥塞情况,这个就是WebRTC基于时延的带宽估计的理论基础。 线性回归 WebRTC用到了线性回归这个数学方法进行时延梯度趋势预测。通过最小二乘法求得拟合直线斜率,根据斜率判断增长趋势。 对于一堆样本点\((x,y)\),拟合直线方程\(y=bx+a\)的斜率\(b\)按如下公式计算: 网络状态 在WebRTC中,定义了三种网络状态:normal,overuse,underuse,用于表示当前带宽的使用情况,具体含义跟单词本身含义一样。 例如如果是overuse状态,表示带宽使用过载了,从而判断网络发生拥塞,如果是underuse状态,表示当前带宽未充分利用。后面会介绍如何根据时延梯度增长趋势得到当前的网络状态。 代码导读 由TrendlineEstimator类实现。主要接口就一个:UpdateTrendline。传入包组时间差,时间,包大小等参数,判断当前网络状态。 [crayon-69e9a3fa7815f394999044/] 说下输入的各个参数的含义: recv_delta_ms:包组接收时间差 send_delta_ms:包组发送时间差 send_time_ms:当前处理的RTP的包发送时间 arrival_time_ms:当前处理的RTP的包到达时间 packet_size:当前处理的RTP包的大小 内部相关函数调用如下: [crayon-69e9a3fa78169309334415/] 下面结合代码说下UpdateTrendline函数内部计算过程。 1)计算时延变化累积值: [crayon-69e9a3fa7816d585863290/] 2)根据1)中的时延累积值计算得到平滑后的时延: [crayon-69e9a3fa78171450550785/] 3)将从第一个包到达至当前RTP包到达的经历时间,平滑时延值存到双端队列delay_hist_中: [crayon-69e9a3fa78174856746404/] 4)当队列delay_hist_大小等于设定的窗口大小时,开始进行时延变化趋势计算,得到直线斜率,直线横坐标为经历时间,纵坐标为平滑时延值: [crayon-69e9a3fa78177204134560/] 5)通过计算得到的时延变化趋势拟合直线斜率,发送时间差,到达时间判断网络状态: [crayon-69e9a3fa7817a400311717/] LinearFitSlope函数 使用最小二乘法求解线性回归,得到时延变化增长趋势的拟合直线斜率。 看下内部代码实现: [crayon-69e9a3fa78186854586589/] Detect函数 该函数主要根据时延变化增长趋势计算当前网络状态,在WebRTC旧版GCC算法,接收端基于时延的带宽预测代码中,这部分属于过载检测器的内容,跟在卡尔曼滤波后面,我们不做讨论,我们讨论的全部是最新代码,全部在发送端进行带宽预测。 在Detect函数内部,会根据前面计算得到的斜率得到一个调整后的斜率值:modified_trend: [crayon-69e9a3fa7818a330171592/] 然后与一个动态阈值threshold_做对比,从而得到网络状态 modified_trend > threshold_,且持续一段时间,同时这段时间内,modified_trend没有变小趋势,认为处于overuse状态 modified_trend < -threshold_,认为处于underuse状态 -threshold_ <= modified_trend <= threshold_,认为处于normal状态 如下图所示,上下两条红色曲线表示动态阈值,蓝色曲线表示调整后的斜率值,阈值随时间动态变化,调整后的斜率值也动态变化,这样网络状态也动态变化。 本图截取自文末参考[1],倒数第三个状态应为normal,不是overuse 相关实现代码如下: [crayon-69e9a3fa7818d179769106/] 这个阈值threshold_是动态调整的,代码实现在UpdateThreshold函数中。 UpdateThreshold函数 阈值threshold_动态调整为了改变算法对时延梯度的敏感度。根据[1]主要有以下两方面原因: 1)时延梯度是变化的,有时很大,有时很小,如果阈值是固定的,对于时延梯度来说可能太大或者太小,这样就会出现检测不够敏感,无法检测到网络拥塞,或者过于敏感,导致一直检测为网络拥塞; 2)固定的阈值会导致与TCP(采用基于丢包的拥塞控制)的竞争中被饿死。 这个阈值根据如下公式计算: 每处理一个新包组信息,就会更新一次阈值,其中\(\Delta T\)表示距离上次阈值更新经历的时间,\(m(t_{i})\)是前面说到的调整后的斜率值modified_trend。 \(k_{\gamma }(t_{i})\)按如下定义: \(k_{d}\)与\(k_{u}\)分别决定阈值增加以及减小的速度。 具体实现代码如下: [crayon-69e9a3fa78191223828090/] 总结 本文主要介绍了如何根据时延梯度得到网络状态,判断网络拥塞状况,并结合WebRTC相关源码进行分析。当我们得到当前网络拥塞状况后,就要对发送码率进行调节,以适应当前网络。后续文章我们将研究如何根据网络状态进行相应码率调整。 参考 [1] Analysis and Design of the Google Congestion Control for Web Real-time Communication (WebRTC).http://dl.acm.org/ft_gateway.cfm?id=2910605&ftid=1722453&dwn=1&CFID=649873557&CFTOKEN=47458294. [2] A Google Congestion Control Algorithm for Real-Time Communication draft-ietf-rmcat-gcc-02.https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02.
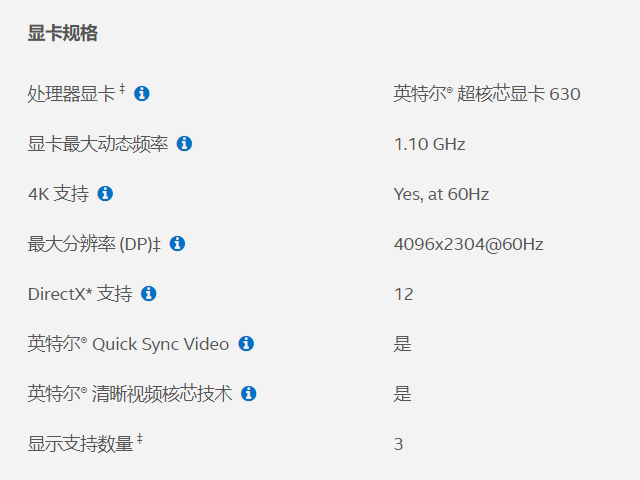
视频编解码分为硬件加速以及非硬件加速。硬件加速是指通过显卡,FPGA等硬件进行视频编解码,由于硬件有专门优化,所以性能高,能耗低,非硬件加速编解码是指通过CPU进行视频编解码,性能就没那么高(虽然有相关CPU指令优化),由于视频编解码计算量很大,所以能耗也很高。在PC平台上主流的硬件加速编解码有Intel集成显卡,Nvidia显卡。Nvidia平台的编解码用的比较多,网上资料也多,接口也很简单,但是相对成本会高些。Intel集显平台视频编解码成本就低很多了,只要是最近几年带集显的CPU基本都支持硬件加速编解码,但是开发复杂度相对高些,网上资料也少,主要是用的人少吧。自己做过Intel集显平台在Linux以及Windows下的编解码开发,也踩过很多坑,故特地写此文章,介绍下Intel集显平台的视频编解码开发,希望更多的人能加入Intel平台视频编解码,降低成本开销。 Quick Sync Video Intel Quick Sync Video(QSV)是Intel GPU上跟视频处理有关的一系列硬件特性的称呼。如下是Intel官网某款CPU带的显卡规格: 可以看到该显卡支持Intel Quick Sync Video。点击Quick Sync Video旁的Info提示: 英特尔® Quick Sync Video 技术可以快速转换便携式多媒体播放器的视频,还能提供在线共享、视频编辑及视频制作功能。 所以看到CPU带的集成显卡支持Quick Sync Video就表示支持硬件加速的视频编解码。 硬件支持 看下Intel不同代处理器对视频编码格式的支持情况。 Platform Name Graphics Adds support for... Ironlake gen5 MPEG-2, H.264 decode. Sandy Bridge gen6 VC-1 decode; H.264 encode. Ivy Bridge gen7 JPEG decode; MPEG-2 encode. Bay Trail gen7 - Haswell gen7.5 - Broadwell gen8 VP8 decode. Braswell gen8 H.265 decode; JPEG, VP8 encode. Skylake gen9 H.265 encode. Apollo Lake gen9 VP9, H.265 Main10 decode. Kaby Lake gen9.5 VP9 profile 2 decode; VP9, H.265 Main10 encode. Coffee Lake gen9.5 - Gemini Lake gen9.5 - Cannonlake gen10 - 可以看到从第五代开始就支持硬件加速视频编解码了,越往后支持的视频编码格式以及特性也逐渐增多。 API支持 在不同平台上可通过不同API使用Intel GPU的硬件加速能力。目前主要由两套API:VAAPI以及libmfx。 VAAPI (视频加速API,Video Acceleration API)包含一套开源的库(LibVA) 以及API规范, 用于硬件加速下的视频编解码以及处理,只有Linux上的驱动提供支持。 libmfx。Intel Media SDK中的API规范,支持视频编解码以及媒体处理。支持Windows以及Linux。 除了Intel自己的API,在Windows系统上还有其他API可使用Intel GPU的硬件加速能力,这些API属于Windows标准,由Intel显卡驱动实现。 DXVA2 / D3D11VA。标准Windows API,支持通过Intel显卡驱动进行视频编解码,FFmpeg有对应实现。 Media Foundation。标准Windows API,支持通过Intel显卡驱动进行视频编解码,FFmpeg不支持该API。 Intel媒体栈 基于Intel显卡技术,Intel媒体栈提供了一系列多媒体解决方案。例如:Intel Media driver(也称作iHD driver),Intel Media SDK, LibVA等。 下图为Intel媒体栈的各个组件示意图: 后面说下跟我们视频编解码关系比较大的。 VAAPI驱动 VAAPI驱动属于用户态驱动,用于支持LibVA,底层是i965/1915驱动。Intel提供了两种开源的VAAPI驱动:intel-vaapi-driver以及intel-media-driver,intel-media-driver较intel-vaapi-driver新,维护更积极,所以目前更推荐使用intel-media-driver。 开发库以及SDK LibVA:VAAPI的开源库实现 LibVA-utils:VAAPI相关的一系列工具以及示例 Intel Media SDK:提供一套用于视频编解码以及处理(VPP)的API:libmfx,支持Linux/Windows,具体介绍可查看:Intel Media SDK 开发环境搭建 前面简单介绍了VAAPI以及Intel Media SDK,下面说下开发环境搭建。 Windows系统 只有Intel Media SDK支持。确保安装了集成显卡驱动,然后需要到Intel官网下载Intel Media SDK安装包。具体搭建请参考: Intel Media SDK环境搭建:https://blog.csdn.net/y601500359/article/details/87169715 Linux系统 包含Ubuntu以及CentOS。需要安装驱动以及相应的库。 FFmpeg VAAPI/QSV开发环境搭建 对于VAAPI以及Intel Media SDK,如果使用原生API开发的话比较麻烦,好在FFmpeg提供了对应的插件。我们可以通过FFmpeg间接使用这两套API。在FFmpeg中VAAPI还是叫做VAAPI,但是Intel Media SDK却叫做QSV(一脸懵逼)。 FFmpeg-vaapi插件:基于VAAPI接口 FFmpeg-qsv插件:基于Intel Media SDK FFmpeg VAAPI/QSV开发环境搭建我就不做搬运工了,大家可参考官网教程。 Linux FFmpeg VAAPI/QSV Installation Environment:https://01.org/linuxmedia/quickstart/ffmpeg-vaapi-qsv-installation-environment 不使用FFmpeg的开发环境搭建 有些人可能不想使用FFmpeg,对于Intel Media SDK还好,但是VAAPI就不行了,接口设计很底层,且复杂,所以对于想使用VAAPI的话,还是老老实实使用FFmpeg吧,时间就是金钱。 对于Intel Media SDK,除了可以编解码,还有可以进行视频的其他操作。2017年开始,Linux上才有开源的Intel Media SDK实现,之前Linux上的对应方案叫做Intel® Media Server Studio,现在已经不可用了。 Linux上的Intel Media SDK底层基于Libva。编译Intel Media SDK也是要安装VAAPI驱动等Intel媒体栈软件。 所以开发环境搭建还是参考上一小节的内容,只是可以选择不编译安装FFmpeg。 注意事项 安装的LibVA-utils包含一个vainfo工具,前面的开发环境搭建后,可以通过vainfo检查VAAPI的安装设置。 [crayon-69e9a3fa79a8c945034851/] 正常的输出类似上面,我们用到的是Intel iHD driver(即Intel Media driver),这个在设置: #export LIBVA_DRIVER_NAME=iHD时指定,设置iHD驱动在一些情况下能获得更高的编解码性能。VAEntrypointVLD 指的是显卡能够解码这个格式,VAEntrypointEncSlice 指的是显卡可以编码这个格式。 如果运行vainfo出现如下错误: [crayon-69e9a3fa79a96795594840/] 说明驱动没设置正确,确保驱动都正常编译到指定目录,且驱动名称及路径: [crayon-69e9a3fa79a9b294792536/] 设置正确。 示例代码 Intel Media SDK:https://github.com/Intel-Media-SDK/MediaSDK/tree/master/samples ffmpeg-VAAPI:FFmpeg源码目录doc\examples下的vaapi_encode.cpp与vaapi_transcode.c 1)示例代码中,avcodec_find_encoder_by_name输入参数得是FFmpeg注册的vaapi编码器名称,例如 h264的vaapi编码器是:h264_vaapi,可通过ffmpeg -codecs | grep vaapi命令查询; 2)av_hwdevice_ctx_create输入的设备名是/dev/dri/renderD128这样的形式,可通过ls /dev/dri查询,这里的示例/dev/dri/renderD128表示Intel集显设备; 3)VAAPI编码时,输入的YUV格式必须是NV12,其他格式YUV得转为NV12格式。vaapi_encode.c有个AVFrame(sw_frame),用于存放我们输入的YUV数据,该AVFrame的data[0]用于存放Y数据,data[1]存放UV数据,由于输入格式是NV12,所以data[1]中UV数据的内存布局为:UVUVUVUV···UVUV。 FFmpeg-QSV:FFmpeg源码目录doc\examples下的qsvdec.c 参考 [1] Linux FFmpeg VAAPI/QSV Installation Environment.https://01.org/zh/linuxmedia/quickstart/ffmpeg-vaapi-qsv-installation-environment?langredirect=1. [2] Intel media for linux.https://01.org/zh/intel-media-for-linux?langredirect=1. [3]Linux media.https://01.org/zh/linuxmedia?langredirect=1.
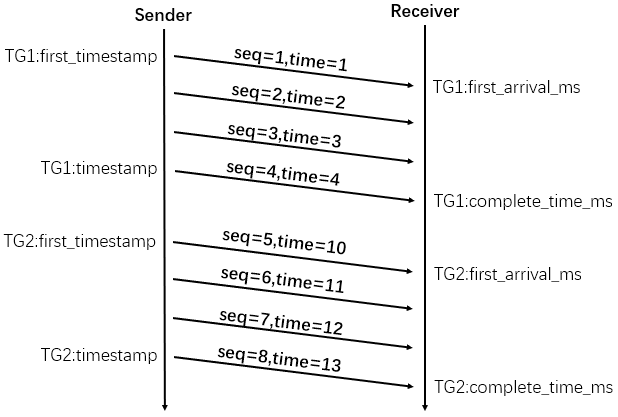
在新版GCC(Google Congestion Control)也就是Sendside BWE中,包含两种拥塞控制模型。一种是基于丢包的,一种是基于时延的,全部在发送端计算。Sendside BWE最后综合这两种估计值取小的那个作为目标码率。 基于时延的拥塞控制算法主要由四部分组成:预处理(pre-filtering), 到达时间滤波器(arrival-time filter), 过载检测器(over-use detector),码率控制器(and a rate controller)。本文主要介绍其中的到达时间滤波器。 到达时间模型 在参考[1]中定义了一种到达时间模型(Arrival-time model),在这里我们先介绍几个概念。 两个包组(包组概念下一小节介绍,包组属于预处理部分的内容)的到达时间差:inter-arrival时间: [crayon-69e9a3fa7ae42805873484/] 两个包组离开(发送)时间差:inter-departure时间: [crayon-69e9a3fa7ae4c071718576/] 包组i与包组i-1的时延变化: [crayon-69e9a3fa7ae50495563861/] 这个时延变化将在后续评估网络时延增长趋势的滤波器中用到,用于判断网络拥塞状况,这里就先不展开讨论,本文主要介绍这些时间差如何计算。 包组 在WebRTC中计算时延不是一个个包计算的,而是通过将包分组,然后计算这些包组间的时延,这样做目的主要是为了提高带宽估计准确性,避免无线网络环境下突发数据的影响,具体影响后面写篇专门文章分析。WebRTC中这些包组称作TimestampGroup。这里我们看下WebRTC中TimestampGroup的结构: [crayon-69e9a3fa7ae53187069213/] 那么如何对包进行分组呢? WebRTC是通过计算发送时间差值来分组。在包组中,除了第一个包外,后面的包距离包组第一个包的发送时间差小于5ms。假设每个包都有一个发送时间t,第一个包的发送时间为t0,如果后续的包发送时间与t0时间差△t = t - to <= 5ms,那么这些包都可以与t0发送时间的包归为一组,如果某个包得到的△t > 5ms,那么该包就作为下一个包组的第一个包,接着后面的包就跟该包继续比较时间差,判断能否归为一组。下面我们举个例子说明下。 上图中有两个包组TG1和TG2,其中序列号为1的包与4的时间差小于5毫秒,那么序列号1~4的包被划到一个包组TG1。序列号为5的包与1之间的时间间隔超过5毫秒,那么5就是TG2的第一个包,它与序列号6、7、8划到一个包组TG2。 在后续评估时延增长趋势的滤波器需要三个主要参数:发送时刻差值(timestamp_delta)、到达时刻差值(arrival_time_delta)和包组数据大小差值(packet_size_delta)。由上图可知: [crayon-69e9a3fa7ae57261079541/] 代码导读 ComputeDeltas函数 前面说到的时间差值计算以及包组判断代码主要由InterArrival类实现。InterArrival类主要就一个接口:ComputeDeltas。传入每个RTP包时间、大小等参数,计算包组时间间隔,包组大小差值,得到新的包组相关差值后返回true。 [crayon-69e9a3fa7ae5a275442690/] 下面解释下各个参数: timestamp:RTP包发送时间 arrival_time_ms:RTP包到达时间 system_time_ms:当前时间 timestamp_delta(output):包组发送时间差 arrival_time_delta_ms(output): 包组到达时间差 packet_size_delta(output) :包组大小差值 接下来看下相关代码流程,看timestamp_delta、arrival_time_delta_ms如何计算: [crayon-69e9a3fa7ae5e683350864/] packet_size_delta计算如下: [crayon-69e9a3fa7ae62640373646/] NewTimestampGroup函数 WebRTC新包组判断代码: [crayon-69e9a3fa7ae65558691096/] 若是第一个包,得作为后续包对比基准,不认为是新包组 若是突发数据(burst),不认为是新包组 与第一个包发送时间间隔大于kMaxBurstDurationMs(值为5),认为该包属于新包组 BelongsToBurst函数 这里我们也介绍下上一小节说到的突发数据。有些客户端发送数据时,没用使用pacing平滑发送模块,没有控制发送速率,这样容易导致突发流量,尤其是发送关键帧数据时,或者在无线网络环境下,也容易出现突发流量。我们看下WebRTC中如何判断突发数据的。 [crayon-69e9a3fa7ae68350937751/] 总结 本篇文章主要讲了到达时间模型以及在WebRTC中的源码实现:InterArrival。后面文章我们将研究下trendline滤波器。前面计算得到的相关差值我们将传递给trendline滤波器,进行网络拥塞情况判断。 WebRTC研究:Trendline滤波器-TrendlineEstimator 参考 [1] A Google Congestion Control Algorithm for Real-Time Communication.https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02.

在WebRTC GCC(Google Congestion Control)中,有一个叫做AlrDetector(应用受限区域探测器,Application limited region detector)的模块。该模块利用某段时间值,以及这段时间发送的字节数判断当前输出网络流量是否受限。这些限制主要跟应用程序本身输出网络流量的能力有关,例如编码器性能,不能编码出设置的目标码率。下面举个简单例子说明下。 假设我们经过带宽预测后,获取到一个目标码流target_bitrate_bps,此时我们程序需要按照该码率大小进行数据发送,但是一切都不是那么完美,例如编码器。编码器由于各种问题,编码出的数据码率低于target_bitrate_bps,使得数据发送码率低于要求,带宽利用率不足,发送码率占最大预算码率值比例低于某个值的话Alr(Application limited region)就会被触发了,恢复到某个值以上,Alr会停止。 下面说下AlrDetector的工作流程。 1)首先是在构造函数初始化相关参数配置,相关参数如下: [crayon-69e9a3fa7c613260903204/] IntervalBudget::can_build_up_underuse_初始化为true。IntervalBudget根据输入的评估码率,计算当前还能发送多少数据。 2)设置带宽预测得到的码率: [crayon-69e9a3fa7c61d763587525/] 3)发送数据时调用: [crayon-69e9a3fa7c620383906767/] 通过IntervalBudget::budget_ratio与start_budget_level_ratio以及stop_budget_level_ratio对比,设置AlrDetector的状态。 [crayon-69e9a3fa7c624710503412/] IntervalBudget::budget_ratio表示剩余要发送的数据占最大预算发送数据max_bytes_in_budget_的比例,定义如下: [crayon-69e9a3fa7c627691363858/] max_bytes_in_budget_按500ms时间窗口计算得到: [crayon-69e9a3fa7c62a455154748/] 可知如果IntervalBudget::budget_ratio大于start_budget_level_ratio,即剩余数据还有很多,发送码率低了,带宽没充分利用,Alr触发了,小于stop_budget_level_ratio时,alr_started_time_ms_重置,Alr停止。 4)通过获取AlrDetector::alr_started_time_ms_判断当前Alr是否触发,调用函数如下: [crayon-69e9a3fa7c62d066128134/]
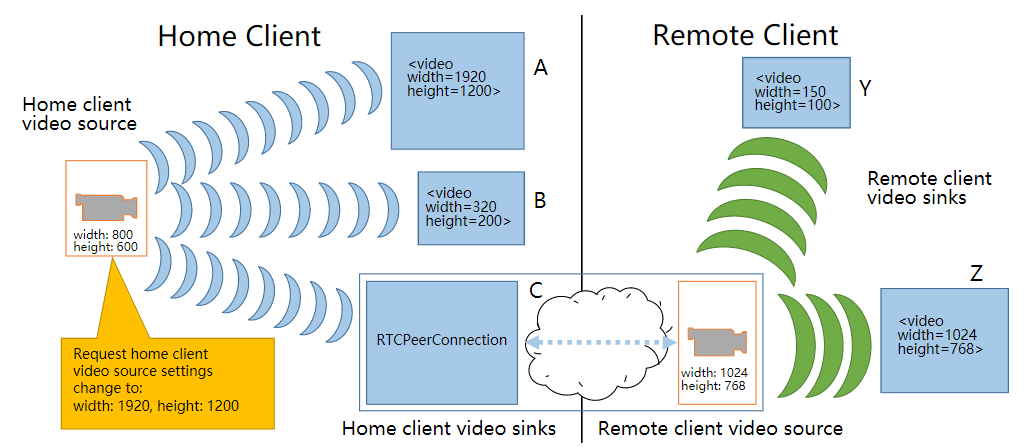
根据W3C的WebRTC 1.0: Real-time Communication Between Browsers规范,WebRTC的源码中定义了两套主要的C++接口,分别是MediaStream与PeerConnection相关的API。本篇文章主要介绍下MediaStream API中一些概念,方便理解内部代码如何处理。 MediaStream 相关API定义在源码api\media_stream_interface.h中。里面主要涉及这4个概念:source,sink,mediatrack,mediastream。 source与sink 在浏览器中,存在source到sink的媒体管道,source是生产媒体资源的,sink负责消费。传统的source一般是些静态资源,例如文件,以及web资源,不随时间改变。对于我们的WebRTC来说,source是动态资源,例如麦克风采集的音频,相机采集的视频,随时间而改变。sink的工作就是将这些source呈现给用户。sink可以是<img>,<video>,<audio>这些标签,用于本地渲染,也可以是RTCPeerConnection,将source通过网络传递到远端。在网络流传输中,RTCPeerConnection可同时扮演source与sink的角色,作为sink,可以将获取的source降低码率,缩放,调整帧率等,然后传递到远端,作为source,将获取的远端码流传递到本地渲染。 下面我们以video source举例,说下WebRTC源码中,source与sink定义。 在api\video\video_source_interface.h中,video source定义如下: [crayon-69e9a3fa7da1f064382256/] source可以添加、移除、更新sink,从而将VideoFrame送给对应的sink处理,一个source可对应多个sink。 在video\video_sink_interface.h中,video sink定义如下: [crayon-69e9a3fa7da29381001192/] sink通过OnFrame获取source传递的VideoFrame。 MediaStreamTrack与MediaStream MediaStream API中有两个重要组成:MediaStreamTrack以及MediaStream。MediaStreamTrack对象代表单一类型的媒体流,产生自客户端的media source,可以是音频或者视频,但只能是其中一种,是音频称作audio track,视频的话称作video track,这其实就是我们平时所说的音轨与视频轨。 一个track由source与sink组成。source给track提供数据。 Medi aStream用于将多个MediaStreamTrack对象打包到一起。一个MediaStream可包含audio track 与video track。类似我们平时的多媒体文件,可包含音频与视频。 一个MediaStream对象包含0或多个MediaStreamTrack对象。MediaStream中的所有MediaStreamTrack对象在渲染时必须同步。就像我们平时播放媒体文件时,音视频的同步。 简单点说,source 与sink构成一个track,多个track构成MediaStram。 在api\media_stream_interface.h中,MediaStream定义如下: [crayon-69e9a3fa7da2d805449380/] MediaStream可以添加移除audio track以及video track。 下面说下MediaTrack的定义,这里我们举例VideoTrack,代码同样位于api\media_stream_interface.h中。 [crayon-69e9a3fa7da31728543483/] 可以看到VideoTrack由video source与video sink组成。 pc\video_track.cc中,我们看下MediaTrack接口的一些具体实现: [crayon-69e9a3fa7da34686208774/] 由于VideoTrack由video source与video sink组成,所以对VideoTrack进行AddOrUpdateSink操作时,其实就是让VideoTrack的source进行AddOrUpdateSink。 示例 为了更好地理解上述概念,我们举个例子说明。下图home client中,摄像机产生视频video source。source的宽高设置分别是800以及600像素。home client 中三个MediaStream包含的track使用该摄像机视频作为source,此时就有三个video track了。三个video track分别连接三个不同的sink:<video>标签A,<video>标签B以及一个peer connection C。<video>A与<video>B分别对source的视频进行缩放处理后渲染到本地浏览器界面中。peer connection C作为sink把该video source 推流到remote client。在remote client,两个media stream使用peer connection作为source,连接到两个<video>sink(Y与Z),进行本地渲染。 参考 [1] Media Capture and Streams.https://www.w3.org/TR/mediacapture-streams/. [2] WebRTC 1.0: Real-time Communication Between Browsers.http://w3c.github.io/webrtc-pc/.
前段时间我的华为手机更新了系统,更新到安卓9.1,说增加方舟编译器等功能。可是问题也来了,续航尿崩,以前都是两天一充,现在一天一充也满足不了,一晚上待机都要耗百分十几的电。而且超级快充也变慢了。看了论坛,发现很多人有同样问题。无奈之下,只能退回到之前版本系统了。下了华为手机助手,USB连接手机,备份好后就开始回退之前版本了。回退后,手机被重新格式化了,所以还要恢复之前的备份。折腾了下,续航恢复之前的水平了,而且坏了好几个月的指纹解锁竟然也恢复了,之前我还以为坏了,期间也更新了几次系统。只能说华为软件水平真是一般,就像目前开源的那个方舟编译器,一个半成品也好意思叫开源。感觉这年头华为被吹得有点飘了,至少软件方面水平真是一般。下部手机在犹豫要不要换回索尼了,对国产手机真不敢抱有太多期待。